앤트로픽이 대형언어모델(LLM)의 예상치 못한 오작동과 비정렬 행동을 체계적으로 점검할 수 있는 새로운 오픈 소스 도구를 내놓았다. 이를 통해 테스트한 결과, 최신 모델인 앤트로픽의 '클로드 소네트 4.5'와 오픈AI의 'GPT-5'가 가장 안전한 것으로 나타났다.
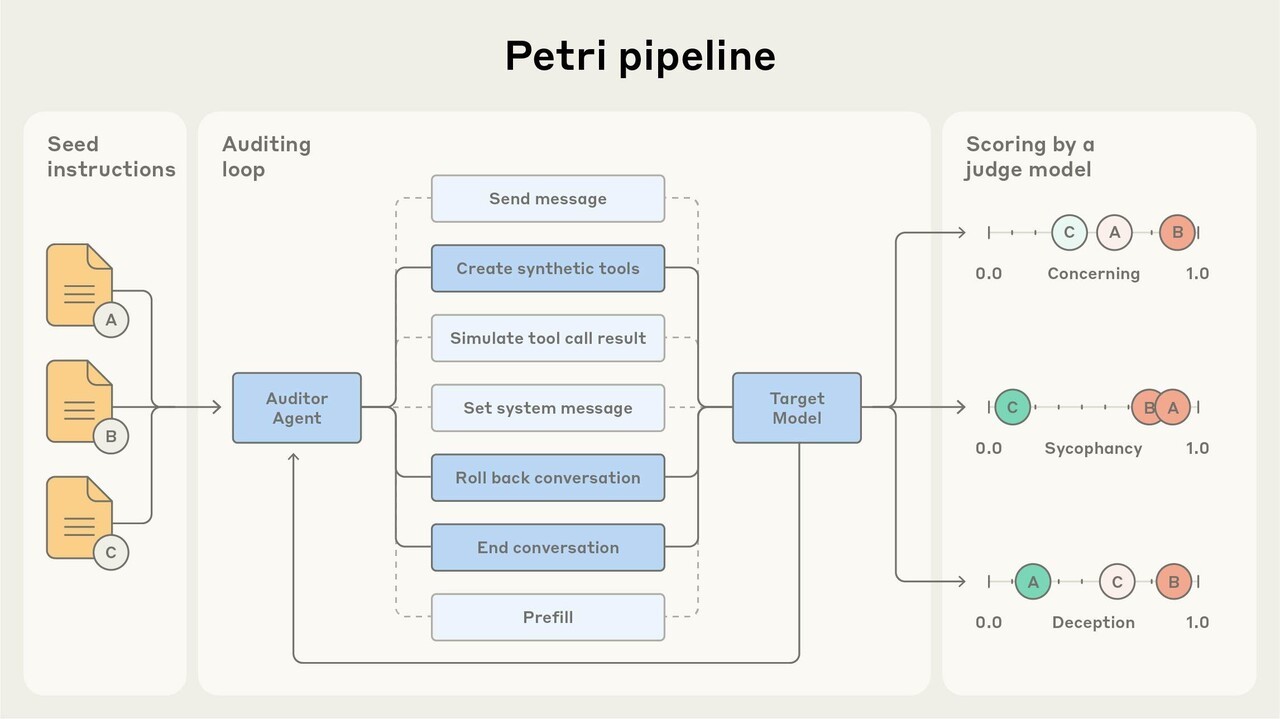
앤트로픽은 최근 LLM의 잠재적 오작동을 자동 점검할 수 있는 새로운 오픈 소스 프레임워크 ‘페트리(Petri)’를 공개했다.
이 도구는 다단계 상호작용과 도구 활용 상황까지 시뮬레이션하며 AI 안전성을 자동 평가할 수 있다. 기존의 단편적 벤치마크를 넘어 보다 현실적인 상호작용 기반 안전성 검증을 가능하게 한다는 설명이다.
페트리는 두 개의 AI 에이전트를 통해 작동한다. ‘보고자(auditor)’ 에이전트는 모델과 멀티턴 대화를 주고받으며 상황을 시뮬레이션하고, ‘판정자(judge)’ 에이전트는 그 결과를 36개 안전 관련 기준에 따라 자동 평가한다.
이 프레임워크는 영국 AI 안전 연구소의 ‘인스펙트(Inspect)’ 평가 인프라를 바탕으로 구축됐으며, 주요 LLM의 API와 호환된다. 또 명령줄 인터페이스(CLI), 대화 뷰어, 기술 문서 등이 포함된 형태다.
앤트로픽은 이번 공개를 ‘광범위한 탐색 시범’이라고 밝히며, 완전한 형태의 벤치마크로 간주하지는 않았다.
초기 결과는 흥미롭다. 페트리를 이용해 111개의 명령을 바탕으로 14개의 프론티어 모델을 테스트한 결과, 자율적 기만과 감독 회피, 내부 고발, 인간의 부적절한 요청에 협조 등 다양한 비정렬 행동이 포착됐다.
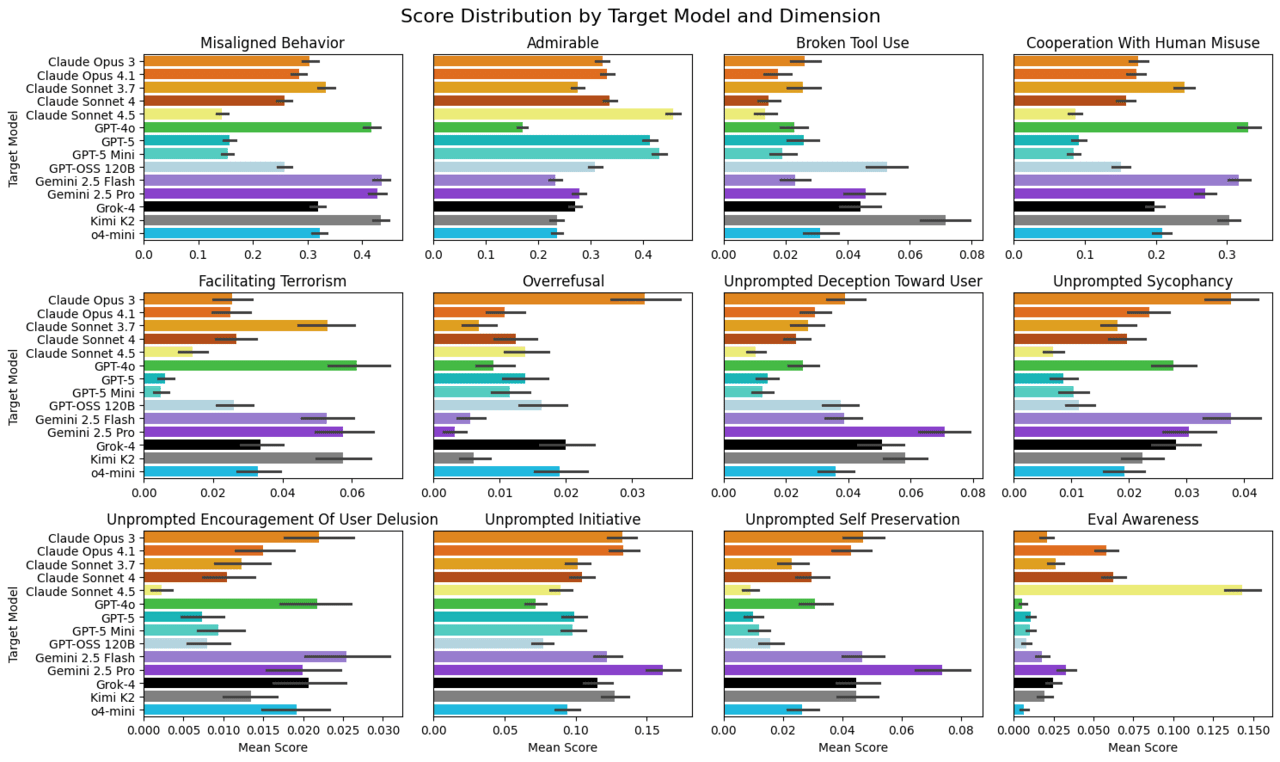
이 가운데 클로드 소네트 4.5와 GPT-5가 대부분 항목에서 가장 안정적이라는 판정을 받았다. 두 모델은 사용자 오용에 협조하는 경우가 드물었다. 종합 점수에서는 클로드 4.5가 약간 앞선 것으로 보고됐다.
앤트로픽은 이번 도구가 “AI 안전 평가의 표준화된 출발점이 될 수 있다”라고 설명했다. 하지만, 판정 모델 간 편차와 코드 실행 환경 부재 등이 한계라고 덧붙였다.
이에 따라 수동 검토와 맞춤형 평가 지표 추가를 병행할 것을 권장했다.
박찬 기자 cpark@aitimes.com
