
인공지능(AI) 전문 모티프테크놀로지스(대표 임정환)는 자체 개발 대형언어모델(LLM) ‘모티프(Motif) 12.7B’를 허깅페이스에 오픈 소스로 공개했다고 5일 밝혔다.
이번 모델은 127억개 매개변수(12.7B)로, ‘프롬 스크래치’ 방식으로 모델 구축부터 데이터 학습까지 전 과정을 직접 수행한 결과물이다.
모티프는 지난 7월 이미지 생성 모델인 '모티프-이미지-6B(Motif-Image-6B)'를 공개하며, 국내에서 유일하게 LLM과 멀티모달모델(LMM)을 모두 자체 개발하고 있다고 전한 바 있다.
또 국내 AI 업계 전반에서 대규모 GPU 클러스터의 효율적 운용과 고성능 LLM 개발 인력 확보가 핵심 난제로 부각되는 가운데, 최고 수준의 GPU 활용 역량과 LLM 개발 노하우를 바탕으로 7주 만에 ‘모티프 12.7B’를 선보일 수 있었다고 소개했다.
이번 모델은 앞서 공개했던 ‘모티프 2.6B’에서 한 단계 도약한 고성능 LLM으로, 추론 능력과 학습 효율 모두를 혁신적으로 끌어올렸다고 강조했다.
자체 개발한 ‘그룹 단위 차등 어텐션(Grouped Differential Attention)’과 ‘뮤온 옵티마이저(Muon Optimizer) 병렬화 알고리즘’이라는 두가지 기술을 통해, 모델 성능과 학습 효율의 혁신적 향상을 이뤘다는 것이다.
그룹 단위 차등 어텐션 메커니즘은 헤드 할당을 전략적으로 비대칭화, 기존 '차등 어텐션(DA)' 메커니즘의 구조적 한계를 넘어선 기술이라고 밝혔다. DA 메커니즘은 어텐션 노이즈를 제거해 모델의 안정성과 추론 능력을 높였으나, 핵심 정보인 신호와 불필요한 정보인 잡음 처리를 위한 연산 헤드를 대칭적으로 할당해야 하는 구조적 한계로 인해 연산 효율이 떨어지는 문제가 있었다는 지적이다.
이에 헤드 할당을 전략적으로 비대칭화해 동일 연산량 대비 최대치의 성능과 표현력을 달성하며, 추론 성능을 향상하는 동시에 환각 현상을 완화했다고 전했다.
또, 뮤온 옵티마이저 병렬화 알고리즘으로 LLM 학습 효율 저하의 주요 원인으로 꼽혀왔던 멀티 노드 분산 환경에서의 노드 간 통신와 동기화 병목 문제도 해결했다. GPU의 연산과 통신 작업을 중첩 스케줄링할 수 있는 병렬화 알고리즘을 통해, 통신 대기 시간을 제거하고 GPU 활용률을 극대화해 학습 효율을 개선했다고 전했다.
강화 학습(RL) 없이 고도화된 추론 능력을 확보한 것도 장점으로 꼽았다. 비용이 많이 소요되는 RL을 생략하고, 추론 중심 지도 학습(SFT) 방식을 통해 모델이 스스로 논리적 사고와 문제 해결을 수행할 수 있도록 설계했다는 설명이다.
더불어, 사용자의 질문 특성에 따라 ‘추론(Think)’과 ‘즉시 응답(No Think)’ 방식을 모델이 스스로 판단하도록 구현, 상황에 맞는 최적의 연산을 수행하도록 했다고 덧붙였다.
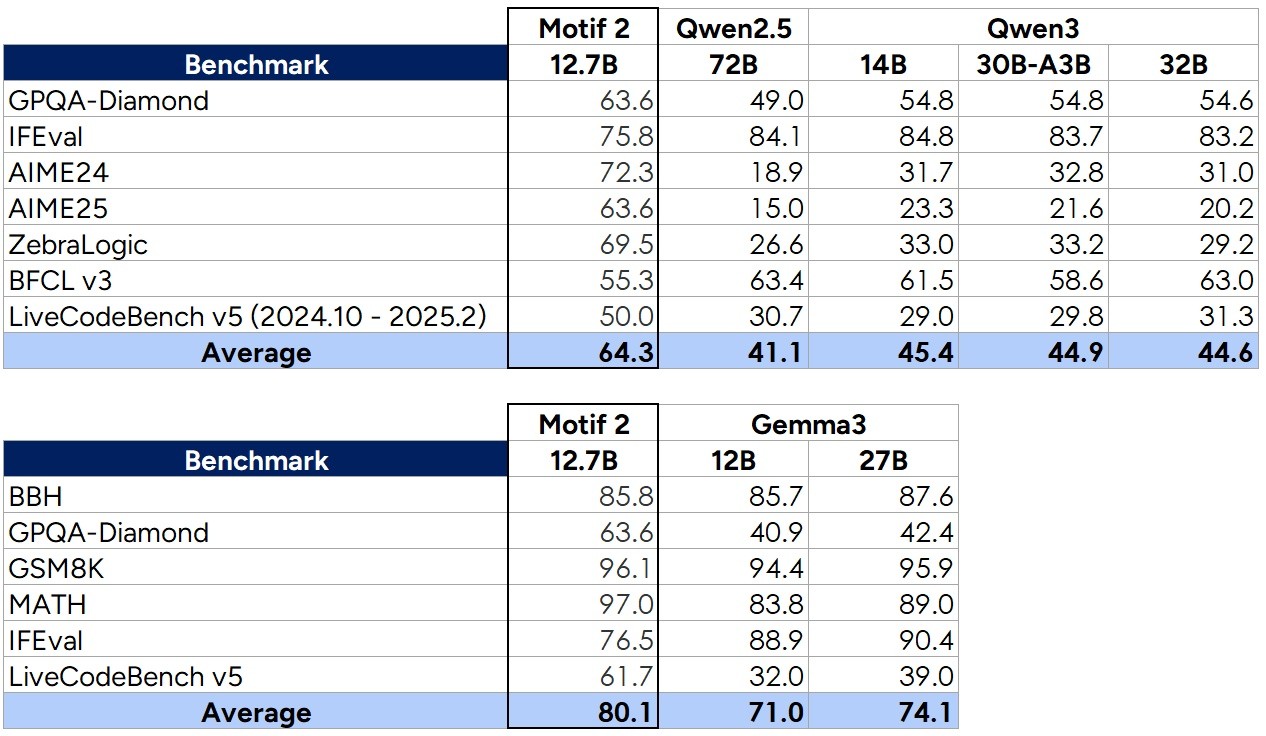
벤치마크 결과, 모티프 12.7B는 'AIME25'와 'GPQA-다이아몬드', '지브라로직(ZebraLogic)' 등 추론 능력을 평가하는 과제에서 720억 매개변수를 가진 '알리바바 큐원 2.5(72B)'를 능가한 것으로 나타났다.
동급인 구글의 '젬마 3 12B'와 비교해도 추론 능력 평가 지표에서 더 나은 점수를 얻었다.
임정환 모티프테크놀로지스 대표는 “GDA와 뮤온 옵티마이저 병렬화 알고리즘은 각각 LLM의 ‘두뇌’와 ‘에너지 효율’을 혁신적으로 재설계한 기술”이라며 “이 기술로 완성한 모티프 12.7B는 단순 성능 향상을 넘어 AI 모델의 구조적 진화를 보여주는 사례가 될 것이며, 동시에 비용 효율적인 고성능 LLM을 원하는 기업에 모범 답안이 될 것”이라고 말했다.
장세민 기자 semim99@aitimes.com
