다중감각인지란 단일 감각이 아닌 다중감각, 즉 시각, 청각, 후각, 촉각, 미각 등을 통합적으로 이용해서 인간처럼 인지적 특성을 갖는 기술이다.
사람은 오감을 통합적으로 이용해 외부정보 및 이벤트를 파악, 행동적 반응을 결정하는 인지적 특성을 형성한다. 인공지능 시스템에서도 이러한 다중감각적 정보처리 특성을 활용해 지능적 대응이 가능하게 한다. 인공지능이 여러 감각양식 정보를 처리하고 각 감각양식 간의 우세성 및 의존성 등 상호작용 관계를 파악해 주어진 환경을 정확하게 인식하고 이해할 수 있게 한다.
개별적 감각 입력 정보에 의존하는 상향적 처리(Bottom-Up Process)와 다양한 상황적 맥락(Context) 정보에 기초하는 하향적 처리(Top-Down Process)가 통합되도록 다중감각 정보의 가용성 및 상호관계 정보 특성을 함께 고려해야 한다.
◆기술동향
멀티모달 데이터로부터 행동을 인식하고 이해. 정확한 행동 인식을 위해 상황맥락과 관련된 다양한 감각양식(Modalities)의 입력 및 데이터 수집의 통합적 분석 모델을 개발해야 한다.
1) 멀티모달 소셜 인터렉션(Multimodal Social Interaction)
문자, 대화, 영상 등 멀티모달 정보 입력을 활용하여 감정 맥락(Emotional Context) 분석을 통해 사회적 상호작용성을 제고하는 기술을 제안하고 성능을 개선한다.
EU’s Horizon 2020의 EMPATHIC project는 차세대 Personalized Virtual Coach의 토대를 마련해 노인들의 독립적인 생활 지원한다. EMPATHIC-VC는 노인 사용자의 기대와 요구 사항 및 개인 이력에 맞춰 사람의 정서적, 사회적 상태를 인식, 요구에 적응하며 반응한다.
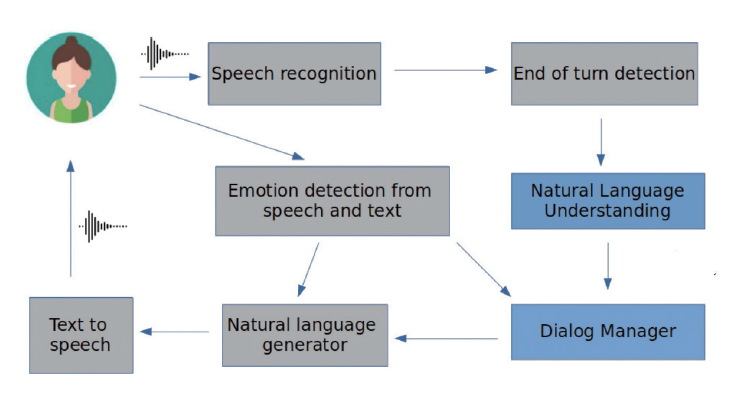
2) 음성인식(Speech Recognition)
시각과 청각정보 등 다양한 입력(Multimodal Inputs) 정보들을 모두 처리하여 음성을 인식할 때 노이즈 및 의미에 대한 강인함과 정확도가 향상된다.
Google의 ‘Looking to Listen at the Cocktail Party’, Audio-Visual Speech Separation은 영상, 음향 정보를 활용한 멀티모달 이해 연구를 통해 음향 분류 정확도 향상. 시각 및 청각 신호를 통합하여 음성신호 분리작업을 해결하는 Deep Network-Based 모델을 제시했다.
3) Transformer 모델
다중감각 데이터 처리 기술은 자연어 처리 분야의 Transformer 모델 적용으로 확장, 다양한 모달리티 간 변환 고도화 방향으로 발전 중이다. 언어지능 분야에서 최고 성능을 달성한 Transformer 모델을 확장해 다중감각 데이터 수용처리 연구가 본격화되고 있다.
4) 감각 정보 융합
음성과 영상, IMU를 비롯한 각종 IoT 센서 데이터 융합을 넘어 촉각과 후각 정보를 융합하는 등 감각의 수용 범위와 그 응용을 확장해 나가고 있다.
로봇의 파지(Grasping) 조작 제어는 시각 정보만 사용하는 비주얼 서보잉(Visual Servoing)이 대세였다. 최근 촉각(Haptic) 정보를 융합함으로써 작업 효율과 안정성을 향상하는 멀티모달 조작 기술이 등장했다.
미국 터프츠 대학(Tufts Univ.)은 다중감각 지능을 통해 로봇의 물체 종류 탐지 성능을 개선했다. 이 연구에서 로봇은 9종의 탐지 작업을 수행하며 각 과정에서 관찰한 장면, 촉감, 음향 등을 종합 판단, 물체의 종류를 판별했다.
5) 후각의 정보화ㆍ제품화
화면의 내용에 맞는 향기가 나는 TV가 2013년 동경대에서 연구됐지만 상용화에 실패했다. 화면 내용에 맞게 향기가 발생했으나 다른 향기로의 전환에 시간이 많이 걸렸다. 이후 CES2019에서 Airia라는 향기가 나는 프린트 기술을 선보였다. 잉크젯 프린터와 유사하며 32개의 노즈로 향기를 조합한다.
◆시장 동향
멀티모달 상황 인지 제품과 기술을 상용화 중이다. 스마트 스피커에 화면과 카메라를 결합하는 멀티모달 제품군(구글 Next Hub Max, 아마존 Echo Show 등)이 등장한 바 있다. 향후 신원 인식, 환경 상황 인식 등 인공지능에 다중감각인지(음성, 영상기반) 기술의 활용 기반이 조성되는 중.
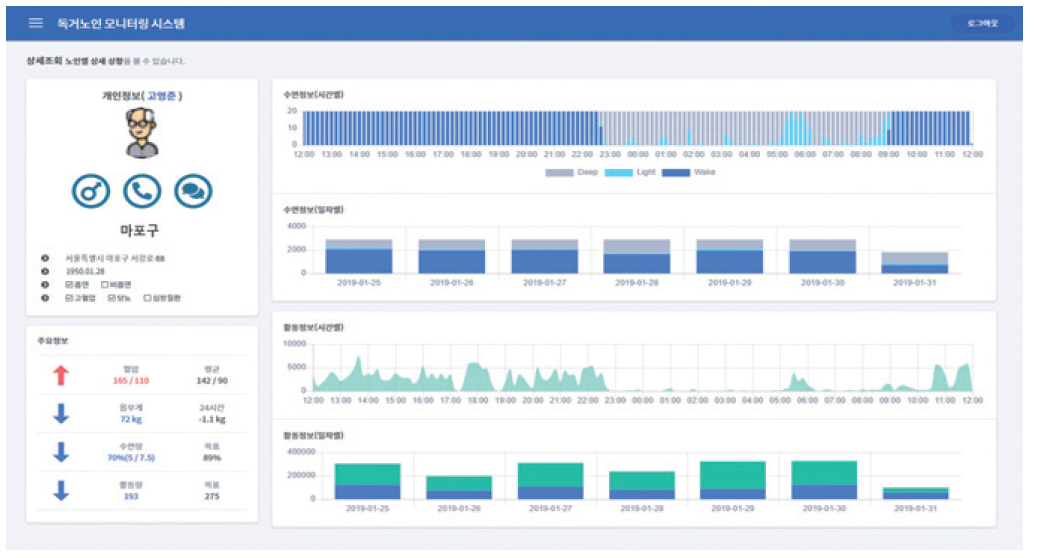
한국 마이크로소프트는 “멀티모달 통합 패턴 인지 기반의 맞춤형 돌봄 서비스” 실증 사업을 통해 웨어러블 디바이스 기반의 정신질환 헬스케어 R&D와 연계한다. 사용자의 일상생활 중 발생하는 복합적인 생체 및 활동 데이터 패턴을 비지도 학습 방법으로 훈련, 이상 징후를 검출해 정신건강 문제를 예측하는 기술과 서비스를 개발 및 검증할 계획이다.
◆발전전망
현재까지의 연구들은 단일 감각양식을 기반으로 개별 감각양식의 정보 인식 및 처리를 통한 의미 분류나 캡셔닝에 치중. 감각양식 간의 통합된 정보처리의 특성과 상호작용 속성 이해를 통해 계산 가능한 모델링 연구가 필요하다.
단기(2020~2022년)에는 지능적 정보처리의 대상으로서의 지각물 및 경험 표상을 구성이 목표. 그리고 의사소통 의미 및 감정 속성에 대한 언어 및 비언어적 멀티모달 맥락정보 요소를 연구한다.
중기(2023~2026년)적 목표는 정보처리 표상을 구성하는 다중 감각적 데이터 요소의 통합적 계산모델을 정립하는 것이다. 다중감각 맥락정보 요소의 상호작용 모델링 및 지능성 관계를 연구한다.
장기(2027~2030년)적으로는 멀티모달 데이터 기반 통합적 표상 생성 모델을 통해 지능적 정보처리 효과 검증, 표상 생성 및 계산 모델 고도화가 목표다. 또한 실세계 환경에 적응하는 능동적인 다중감각인지 체화형 지능을 개발하고자 한다.
◆주요 프로젝트
[해외]
①오픈AI 'Five'
연구시기 : 2017~2019년
②University of Southern California(USC) 'Multi-Agent Path Planning'
연구시기 : 2017~2020년
③Microsoft Research 'Deep Communicating Agents for Natural Language Generation'
연구시기 : 2017년~
④Microsoft Research 'Project Malmo'
연구시기 : 2016~2020년
⑤인텔 'MADRaS : Multi Agent DRiving Simulator'
연구시기 : 2018년~
⑥NSF, USDA, NASA 'NRI(National Robotics Initiative)2.0: Ubiquitous Collaborative Robots)'
연구시기 : 2020년~
⑦DARPA 'OFFSET'
연구시기 : 2017~2020년
⑧DARPA 'CODE'
연구시기 : 2015~2019년
[국내]
①서울대, GIST '조립 대상물의 작업계획이 주어진 상태에서 실환경의 물체를 인식하고 실제 조립을 수행하는 지능 로봇 기술 개발'
연구시기 : 2019년~
②KETI '5G 드론 시스템 및 원격운영시스템 개발'
연구시기 : 2020~2024년
③LG전자 '다수 로봇의 지능을 통합 고도화하는 클라우드 로봇 지능 증강공유 및 프레임워크 기술'
연구시기 : 2020~2023년
④카이스트 '무인이동체 자율 임무계획 기술 개발'
연구시기 : 2020~2027년
⑤카이스트 '군집 임무 계획 알고리즘 개발'
연구시기 : 2019~2024년
"인공지능과 자연지능 연계 집중할 때" AI 기술청사진 연구 총괄 IITP 박상욱 팀장
[특별기획] 인공지능 기술 청사진 2030 연재순서 표
AI타임스 임채린ㆍ정윤아 기자 lynnlim@aitimes.com
