
"편견 없는 AI를 갖춘 제품을 만들려면 기계학습 과정부터 제품 제작까지 맥락을 전체적으로 파악해야 한다. 다양한 인력도 필요하다. 데이터 공정성을 높이려면 연합학습을 통한 새로운 알고리즘 모델도 있어야 한다."
KAIST가 10일 개최한 '인공지능과 미래사회 국제심포지엄' 첫 세션에서 전문가들은 공정한 AI를 활용한 제품 모델링과 편향 없는 데이터 활용법에 대해 논의했다. 구글 AI 제품 윤리 총괄 책임자 털시 도시(Tulsee Doshi)는 '전체 맥락을 통한 편향성 파악'을 제안했다. 제품 속 공정성을 지키기 위해 각 프로세스마다 다양하게 문제를 이해해야 한다고 주장했다. 위스콘신대(메디슨 캠퍼스) 이강욱 교수는 공정한 데이터 수집을 위해 '연합형 페어배치(FedFB, Federated FairBatch)알고리즘'을 적극 제안했다.
AI 제품 공정성 문제, 제품 설계시 맥락 파악해야

구글 AI 제품 윤리 총괄 책임자는 “AI를 활용한 제품 설계 시 데이터를 왜 사용하는지, 어디에 응용할 건지, 구체적으로 어떤 데이터셋을 사용할 건지 맥락 속에서 전체적으로 파악해야 한다”고 주장했다. “모두 제품 모델링 결과에 영향을 미친다”며 “작은 프로세스 안에서 한 우물만 파는 건 바람직하지 않다”고도 말했다.
“제품에서 AI 공정성을 다룰 때는 공정성 표현 차제가 달라질 수 있기 때문이다”고 그는 덧붙였다. 인종 간의 공정성을 다룰 땐 이미지를 통한 편향으로 표현하지만, 번역의 공정성은 다르게 나타난다. 예를 들어, 터키어는 남녀 명사 구분이 없다. 그런데 영어로 ‘간호사’를 번역하면 'She is a nurse'로 나온다. ‘의사’를 영어로 바꾸면 'He is a doctor'로 번역된다. AI 번역기는 텍스트로 편향성을 보인다는 의미다. 도시는 “API에 있는 편향적 ‘독성’이 우리를 어떤 방식으로 분류하는지를 볼 수 있다”고 강조했다.
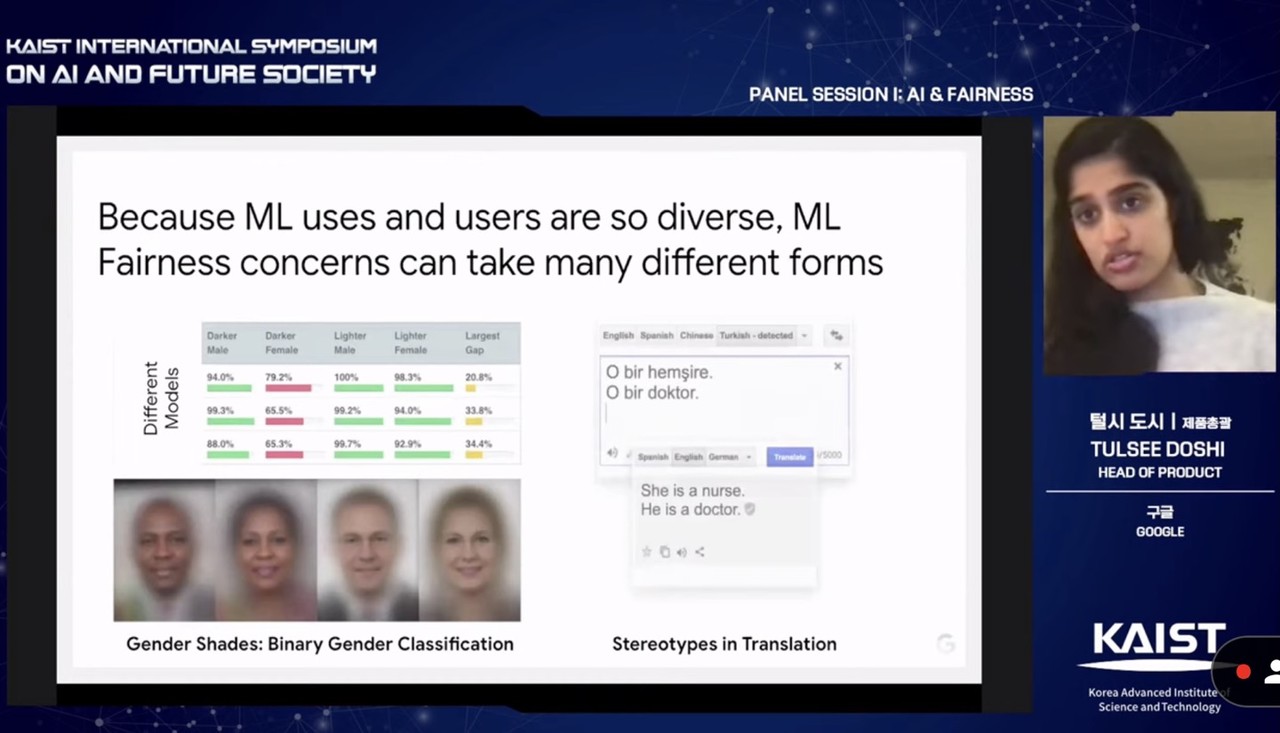
“AI를 활용한 제품 제작에서 공정성은 상황에 따라서도 달라질 수 있다”고도 했다. 사용자 그룹, 사용한 데이터셋, 분석법, 의사 결정 방식 등 다양한 상황을 통해 편향성이 스며들 수 있다”고 그는 덧붙였다.
제품 속 AI 공정성, 다양한 시도와 꾸준한 테스트만이 살길

전체 맥락 속 편향을 완화하기 위해 "다양한 커뮤니티를 유지하고, 전체 데이터를 수집해서 테스트를 지속적으로 해야 한다"고 도시 책임자는 주장했다. 이를 통해 "모델 디자인이나 시스템에 있는 편향을 완화할 수 있다"며 "제품 모델 성능까지 바꿀 수 있는 긍정적 결과를 얻을 수 있다"고 자신했다.
이 교수, 데이터 공정성 향상 위해 새 알고리즘 모델 제시
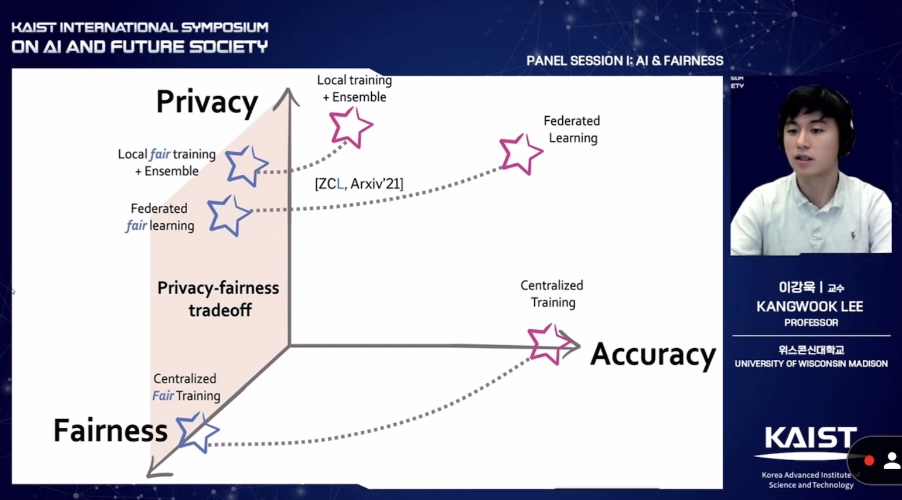
이강욱 교수는 데이터에 필수적인 프라이버시(Privacy), 정확성(Accuracy), 공정성(Fairness)에 대해 각각 소개했다.
이 교수는 "현재 데이터 프라이버시와 정확성 강화 연구는 어느 정도 진전됐다"고 설명했다. "주로 연합학습(Federated learning)으로 프라이버시와 정확성 강화 연구가 이뤄졌다"고 덧붙였다. 연합학습은 각 집단 데이터 모델을 학습해서 중간 결과를 서로 공유하는 방식이다. 그러면 하나의 최종 모델이 탄생한다. 데이터를 직접 공유하는 게 아닌 모델을 공유해서 안전하고, 집단 간의 모델을 조합해서 정확도가 높다.
그는 "공정성 강화 연구는 더딘 상태다"며 “공정성도 비슷한 원리로 높일 수 있다”고 주장했다. 현재 공정성과 프라이버시 관련 연구는 아직 미궁 속이다. "연합학습에서 공정성은 여전히 취약하다"며 "세 구역 장점을 다 취합할 수 있는 방법을 고안했다"고 밝혔다.

이 교수는 "'연합 페어배치(FedFB, Federated FairBatch) 알고리즘'으로 공정성을 높일 수 있다"고 말했다. "해당 알고리즘은 모든 훈련에 적용이 가능하다"며 "모델이 어떻게 각 프로세스에서 진행되는지 직접 관찰할 수 있다"고 설명했다. 이를 통해 데이터셋이 불균형할 때 다시 균형을 맞추는 기능(rebalancing)도 할 수 있다. 그는 "해당 알고리즘 모델이 정확성, 프라이버시뿐만 아니라 공정성까지 향상할 수 있다"고 자신했다.
하나가 아닌 여러 데이터셋을 대상으로도 진행이 가능하다. 각 집단의 페어배치를 실행해서 모듈이 중간 결과들을 서로 공유하는 셈이다. 해당 알고리즘을 통해 수행력을 높일 수 있다.
AI타임스 김미정 기자 kimj7521@aitimes.com
