
KT가 기존 언어모델을 뛰어넘는 새로운 초거대 AI 모델을 개발하고 있다고 밝혔다. 스마트 스피커, 콜센터, 로보틱스 등 다양한 분야에 인공지능(AI) 기술을 적용하고 있는 만큼 차별화된 언어모델이 필요한 까닭이다. KT가 개발하고 있는 언어모델은 구글 '버트(BERT)'와 오픈AI의 'GPT-3'의 개량된 버전이 될 것으로 전망된다.
서영경 KT 연구원은 24일 세계 최대 AI 개발자 컨퍼런스로 불리는 엔비디아 GTC 2022에서 KT가 개발 중인 차세대 언어모델을 공개했다. 서 연구원은 "KT는 현재 초거대 AI 모델을 개발하고 있다"면서 "여러 분야 언어를 이해하는 능력과 자연스러운 문장 생성능력을 개발하려면 초거대 AI가 필요하기 때문"이라고 말했다. 이어 "현재 KT가 개발하는 언어모델은 인코더-디코더 아키텍처"라고 밝혔다.
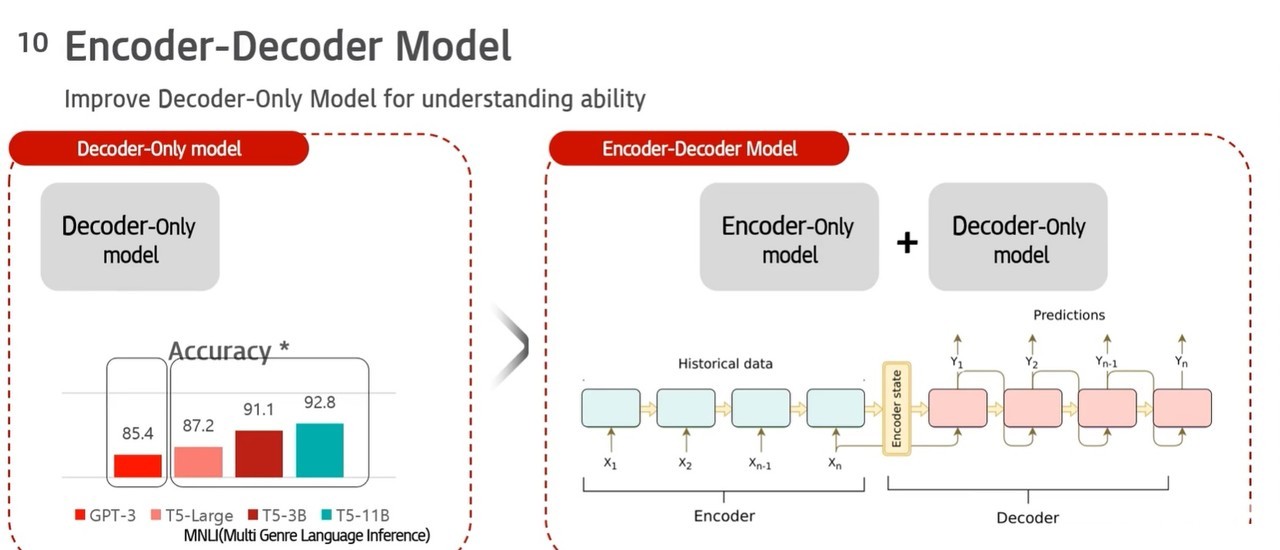
인코더와 디코더는 기계에 문장을 트레이닝하는 프로세스다. 문장을 적절한 벡터로 변환하는 것을 인코딩, 벡터를 적절한 문장으로 변환하는 것을 디코딩이라 부른다. 일반적으로 언어를 이해하는 능력은 인코딩 수행방식을 사용한다. 반면 언어 생성능력은 디코딩에 의존한다.
2018년 구글에서 출시한 버트는 인코더 기능만 갖춘 모델이다. 트랜스포머 모델을 적용하는 인코더만 탑재됐다. 반대로 문장 생성에 중점을 둔 GPT-3는 디코더 기능만 갖췄다.
KT가 개발하고 있는 인코더-디코더 아키텍처는 버트와 GPT-3 모델과는 다른 버전이다. 언어이해 능력과 생성능력을 모두 갖췄다. 사람이 하는 언어를 이해하고 데이터를 토대로 언어 생성도 할 수 있다.
서 연구원은 "구글이 발표한 보고서에 따르면 인코더-디코더 아키텍처 성능이 디코더만 있는 모델보다 좋다고 평가된다"면서 "의미 유사도(STS), 자연어 추론(NLI), 관계추출(RE), 기계 독해(MRC), 문서 요약 등에 언어 생성능력을 평가한 결과 성능이 우수하고 트레이닝이 더 잘된다는 것을 확인했다"고 말했다.

KT가 인코더-디코더가 모두 가능한 초거대 언어모델을 개발하려는 이유는 다양한 비즈니스에 AI를 적용하기 위해서다. 현재 KT는 스마트 스피커 '기가지니'를 비롯해 콜센터, 로보틱스 등의 사업에 AI를 탑재했다.
콜센터의 경우 전국 유무선 네트워크와 클라우드 인프라를 통해 사람 개입 없이도 고객의 전화를 처리할 수 있는 기술을 구현했다. KT의 AI 상담원 음성봇은 지난해 출시 이후 총 73%의 상담 완료율을 기록했다. 약 10만 명의 고객이 사람 개입없이 AI와 소통하며 상담을 종료했다.
서 연구원은 "KT가 이미 공개된 AI 모델을 사용하지 않고 자체적으로 초거대 AI 모델을 만드는 이유는 여러 비즈니스 모델 성능을 높이기 위해서다"라고 밝혔다. 그는 "모든 작업에서 대량의 훈련 데이터를 수집하는 방식은 시간이 오래 걸려 다양한 영역으로 확장이 불가능하다"면서 "새로운 비즈니스 영역에 AI 적용 시간을 단축시키기 위해 초거대 AI 모델을 개발하고 있다"고 설명했다.
초거대 AI를 다양한 비즈니스에 적용하기 위해 KT는 사전 언어모델로 훈련된 고정 지식과 실시간 변하는 유연한 지식을 구분 지었다. 사전에 학습된 고정 지식에 실시간 데이터를 더하는 방식이다. 새로운 비즈니스에 AI를 적용할 때마다 데이터를 사전 트레이닝 하는 방법보다 시간과 자원을 아낄 수 있다.
기존 고정 데이터에 채팅, 댓글, 음성 음성데이터, 전문지식 데이터를 계속 업데이트하는 방식이라고 이해하면 된다. 서 연구원은 "사용자가 어제 본 티라노사우르스가 나온 영화에 대해서 AI와 얘기한다고 하면 (유연한 데이터를 학습하지 않은 AI는) '영화가 재미있었겠네요' 등의 형식적인 대화밖에 하지 못하지만 외부 지식 데이터를 활용할 경우 AI가 백과사전 정보를 활용해 더 많은 대화를 이어갈 수 있다"며 "이것이 현재 KT가 추구하는 모델"이라고 말했다.
서 연구원은 현재 KT는 300억 개 파라미터(매개변수)로 AI를 학습하고 있다고 설명했다. 궁극적으로는 2000억 개 이상의 파라미터로 초거대 AI를 확장할 것이라고 밝혔다. 통상적으로 파라미터가 많을수록 AI가 더 정교한 학습이 가능한 것으로 알려져 있다. GPT-3는 1750억 개의 파라미터를 갖추고 있다. 네이버의 하이퍼클로바가 갖춘 파라미터 수는 2040억 개다.
그는 "초거대 AI는 인간과 AI와의 소통을 더 원활하게 할 것"이라며 "AI가 사람처럼 시끄러운 환경 속에서도 불완전한 문장을 이해할 수 있고 과거 대화 내역을 바탕으로 사용자와의 대화 내용을 이해해 감정과 억양을 담아 자연스럽게 소통하는 것도 가능해질 것"이라고 말했다. 또 "AI가 확장된 파라미터를 통해 웹페이지, 사진, 영상, 지도에 대해서도 사람과 대화를 나눌 수 있을 것"이라고 밝혔다.
AI타임스 김동원 기자 goodtuna@aitimes.com
[관련기사][GTC 2022] 정석근 네이버 클로바 CIC 대표 "하이퍼클로바, AI 개발에 새로운 패러다임 제시"
- [GTC 2022] 에스아이에이 "탄소 배출량 측정, 위성영상과 딥러닝으로 가능"
- [GTC 2022] 메디컬 AI, 건강 수명 연장하는 AI 기술 개발 앞장서
- [GTC 2022] 젠슨 황 엔비디아 CEO "AI 새 물결, 우리가 주도할 것"
- 청초한 외모, 수려한 말솜씨…광주 AI 행사에 깜짝 MC로 등장한 여성의 정체는
- “엔비디아, GPU 기반 AI가 칩 설계에서 사람보다 우수”
- 구글, AI 언어모델 'LaMDA 2'를 위한 베타 테스트 공개
- “날 추앙해~” 말하자 AI가 "오글거려~" 대답했다
- 아마존, 다국어 언어 모델 AlexaTM 공개
