
아마존(Amazon)의 에코(Echo)와 같은 인공지능(AI) 기기는 사용자의 일상 대화를 엿듣고 녹음할 수 있다. 컬럼비아 대학교(Columbia University)의 연구팀이 AI 시스템이 지속적으로 사용자의 말을 듣는 것을 방지하는 AI를 개발했다.
PC, 스마트폰 등의 컴퓨팅 기기에 '스파이웨어'를 숨겨 사용자 대화를 도청할 수 있고, 스마트 스피커를 도청 기기로 전환할 수도 있다. 이러한 도청으로부터 사용자를 보호 하기 위한 ‘신경망 음성 위장(Neural Voice Camouflage)’ 기술은 AI를 기반으로 배경에 맞춤형 오디오 노이즈(noise)를 만들어 녹음된 음성을 들리지 않게 만들 수 있다.
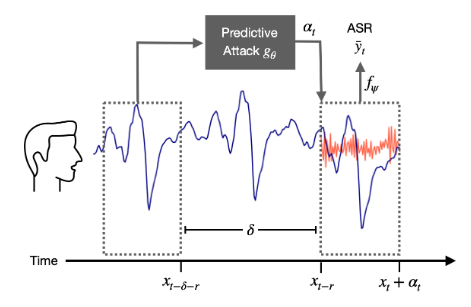
신경망 음성 위장 기술은 AI 도청을 막기 위해 ‘적대적 공격(adversarial attack)’을 사용한다. 이 전략은 알고리즘이 데이터에서 패턴을 찾는 기계 학습을 사용해 사람이 아닌 AI가 다른 것으로 오인하도록 소리를 조정한다. 기본적으로 AI를 사용해 다른 AI를 속이는 방식이다. 그러나 그 과정이 복잡하고 기계 학습 AI가 전체 사운드 클립을 처리한 후 조정하는 방법을 배우기 때문에 대화 중에 실시간으로 사용하기 어렵다.
신경망 음성 위장은 미래를 효과적으로 예측하기 위해 신경망 모델을 사용한다. 이 모델은 녹음된 음성에 대해 여러 시간 동안 훈련되어 2초 단위로 음성을 지속적으로 처리해 다음에 할 말을 위장해 삽입한다. 예를 들어 누군가가 ‘연회를 즐기십시오’라고 말하는 것을 AI가 듣고 따라올 가능성이 높은 방해(위장)하는 소리를 생성한다. 사람의 귀에는 생성된 소리가 배경 소음처럼 들리고 말은 쉽게 이해할 수 있지만 기계는 이해할 수 없게 된다.
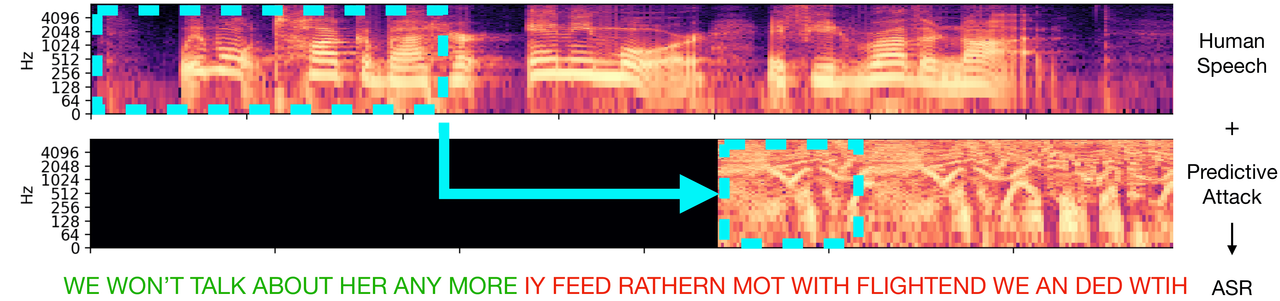
연구팀은 자동 음성 인식(ASR, Automatic Speech Recognition) 시스템 중 하나를 사용해 신경망 음성 위장의 정확성을 검증했다. 음성을 신경망 음성 위장로 처리했을 때 ASR의 문자 인증 정확도를 88.7%에서 19.8%로 줄이는 데 성공했다. 반면 ASR의 단어인증 정확도는 음성에 백색소음만 추가했을 때 87.2%, 신경망 음성 위장의 예측기능이 없는 적대적 공격을 이용한 노이즈 처리가 도청할 때 79.5%로 나타났다.

또한 마이크와 같은 방에 있는 스피커 세트를 통해 위장된 음성 녹음을 재생해 시험한 경우에도 여전히 작동했다. 예를 들어 스피커로부터 'I also have a new monitor’를 들은 ASR은 ‘with reasons with they also toscat and neumanitor"로 표기했다.
연구를 주도한 컬럼비아 대학의 컴퓨터 과학자인 미아 차퀴어(Mia Chiquier)는 이것은 AI에 사용해 개인 정보를 보호하기 위한 첫 번째 단계일 뿐이라고 말했다. 이어 “인공 지능은 우리의 목소리, 얼굴, 행동에 대한 데이터를 수집한다. 우리는 우리의 개인 정보를 존중하는 새로운 세대의 기술이 필요하다”고 강조했다.
음성 처리를 연구하는 앤아버(Ann Arbor)의 미시간 대학(University of Michigan)의 컴퓨터 과학자 앤드류 오웬스(Andrew Owens)는 “머신 러닝의 고전적인 문제와 미래 예측을 적대적 공격의 또 다른 문제와 결합하는 것은 훌륭하다"고 말했다. 또한 음성 기반 적대 공격의 적용을 연구하는 일리노이 대학 어바나 샴페인(University of Illinois, Urbana-Champaign)의 컴퓨터 과학자 보 리(Bo Li)도 ASR에 대한 새로운 접근 방식에 깊은 인상을 받았다고 말했다.
AI타임스 박찬 위원 cpark@aitimes.com
