이미지를 생성하는 ‘달리(DALL-E)’처럼 음성을 생성하는 인공지능(AI)이 나왔다.
달리에 텍스트와 사진을 입력하면 사진을 기반으로 텍스트 내용과 일치하는 이미지를 생성하는 것처럼 텍스트와 음성 샘플을 입력하면 텍스트를 제공한 음성으로 변환해주는 인공지능이다.
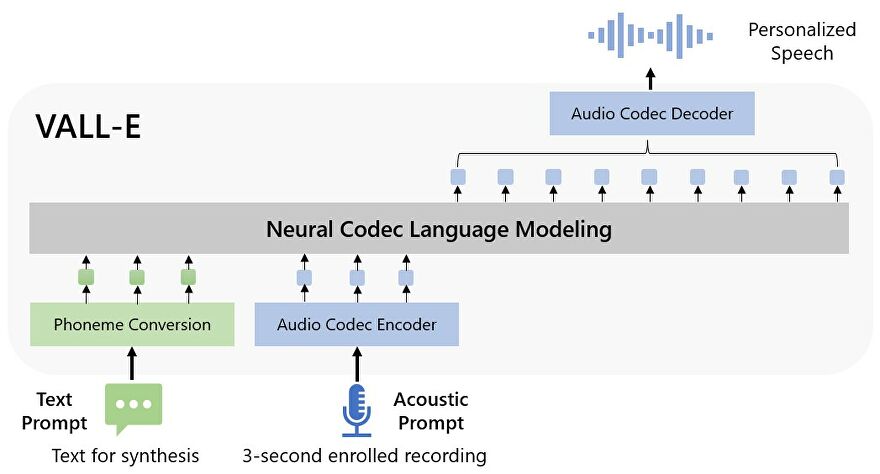
마이크로소프트(MS)가 3초 분량의 녹음을 사용해 사람의 목소리를 복제할 수 있는 텍스트-음성 변환 AI 모델 ‘발리(VALL-E)’를 출시했다고 아스테크니카가 9일(현지시간) 보도했다.
발리는 특정 목소리를 학습하면 그 사람이 말하는 모든 음성을 합성할 수 있는 것이 특징이다. 많은 음성 AI 도구가 어려움을 겪는 화자의 감정과 어조까지 쉽게 복제할 수 있다.
발리를 이용하면 고품질 텍스트-음성 변환 응용 프로그램, 텍스트 대본을 변경해 녹음을 편집하는 음성 편집 또는 GPT-3와 같은 다른 생성 AI 모델과 결합한 오디오 콘텐츠를 생성할 수 있다.
발리는 일반적으로 파형을 조작해 음성을 합성하는 다른 텍스트-음성 변환 방법과 다르게 텍스트 및 음성 프롬프트에서 개별 오디오 코덱 코드를 생성한다. 오디오 코덱 코드는 사람의 소리를 분석해 음성 정보를 개별 구성 요소로 표현하는 일련의 ‘토큰’으로 구성된다. 이 토큰들은 훈련 데이터를 통해 학습된 방법으로 다시 음성으로 복구된다.
MS의 텍스트-음성 변환 AI 모델 ‘발리’ (영상=코딩머니)
MS는 발리를 신경 오디오 코덱 모델인 ‘인코덱(EnCodec)’이 생성하는 개별 오디오 코덱 코드에서 훈련된 ‘신경 코덱 언어 모델’이라고 부른다. 인코덱은 메타가 지난 10월 공개한 오디오 압축 기술이다.
또 공개 도메인 오디오북에서 가져온 7000명이 넘는 화자의 6만시간 분량의 영어 음성 데이터로 발리를 훈련시켰다.
발리는 화자의 음색, 감정 및 톤을 보존하는 것 외에도 샘플 음성의 음향 환경을 모방할 수도 있다. 예를 들어 샘플이 전화 통화에서 나온 경우 생성된 음성도 전화 통화처럼 들린다.
MS는 발리가 잠재적으로 악용되거나 오남용될 수 있다는 우려 때문에 아직 대중에 공개하지 않았다. 발리는 화자의 신원을 유지하는 음성을 합성할 수 있기 때문에 음성 식별을 스푸핑하거나 특정 화자를 사칭하는 등 모델 오용 시 잠재적 위험이 따를 수 있다.
박찬 위원 cpark@aitimes.com
