
거대 기술 기업과 오픈소스 개발자 사이에서 벌어지고 있는 생성 인공지능(AI) 개발 경쟁의 무게추가 오픈소스 진영으로 기울어지고 있다는 분석이 나왔다.
구글과 오픈AI 등 기술기업이 천문학적인 금액을 투자해 대규모언어모델(LLM)을 개발하고, 이를 토대로 'GPT-4'와 같은 초거대 AI모델을 훈련시키고는 있으나 정작 개발자들은 이보다 오픈소스 커뮤니티에서 공유할 수 있는 기술을 활용하고 있다는 것이다.
블룸버그는 5일(현지시간) 루크 세르나우 구글 수석 엔지니어가 게시한 내부 문서를 인용해 구글과 오픈AI가 LLM으로 생성 AI 시장을 장악하기 위해 경쟁하는 가운데 조용히 치고 올라온 오픈소스 커뮤니티가 주도권을 잡아가는 양상을 보이기 시작했다고 보도했다.
세르나우는 문서에서 메타가 공개한 LLM ‘라마(LLaMA)’가 유출된 이후 이를 활용한 개발 활동이 늘면서 기술 개발 속도가 급격히 증가했다고 주장했다.
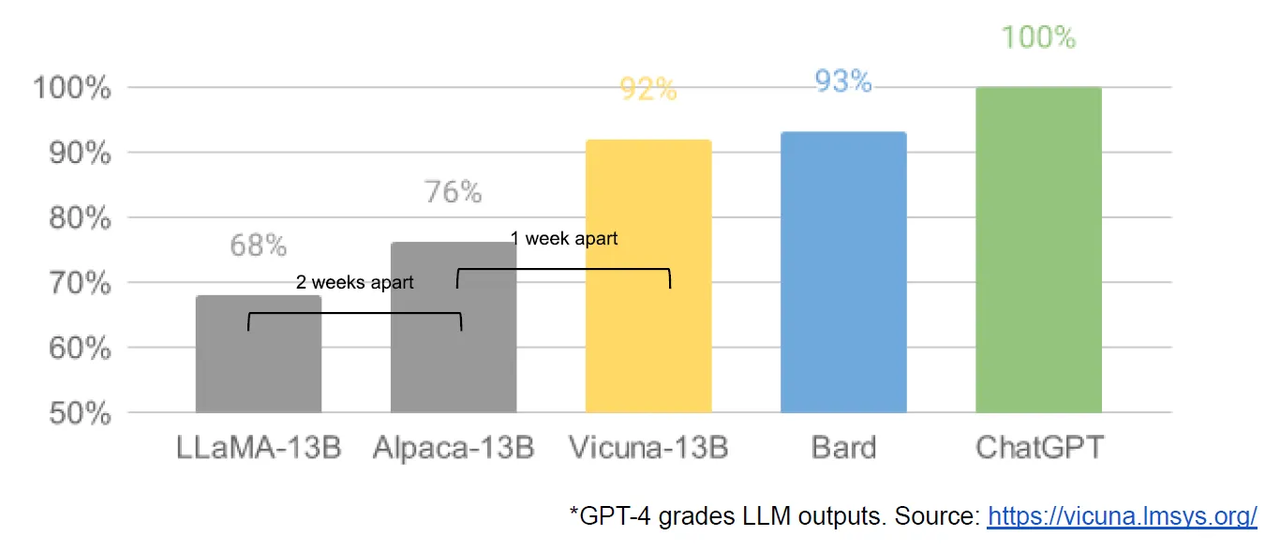
이에 따르면 유출된 라마를 기반으로 훈련한 ‘알파카(Alpaca)’나 ‘비쿠냐(Vicuna)’ 등 오픈소스 기반의 소형언어모델(sLLM)은 라마를 능가하는 성능을 보였다. '챗GPT' 응답 품질을 100%로 설정했을 때 라마는 68%, 알파카는 76%, 비쿠나는 92%, 구글 ‘바드(Bard)’는 93%를 기록했다.
구글과 오픈AI가 높은 정확도를 제공하는 5400억개 이상의 매개변수를 가진 LLM으로 시장을 통제하고 있지만 비용이 많이 들고 휴대성이 좋지 않다. 즉, 더 작은 시스템에서 실행하기 어렵고 대규모 컴퓨팅 인프라가 필요하며 모델을 생성하는 데 시간이 걸린다.
반면 오픈소스 진영은 훨씬 더 저렴하게 더 작은 데이터 세트에서 몇 달이 아니라 몇 주 만에 구축할 수 있는 더 작고 민첩한 모델을 생산하고 있다. 라마는 130억 개의 매개변수로 다른 LLM보다 훨씬 작으며, 오픈소스 커뮤니티가 빠르게 복제한 알파카, 비쿠냐 등 소형 언어 모델들의 기반 모델이 됐다.

더 작은 모델은 선별된 소규모 데이터 세트에 대해 훈련을 받을 수 있기 때문에 더 잘 작동한다. 이식성이 높고 훈련 및 배포 비용이 낮기 때문에 사용하기 쉽고 부담이 적다.
세르누아는 구글은 오픈소스 커뮤니티와 차별화되는 독특한 장점 또는 비결이 없고, 오픈소스 커뮤니티는 LLM과 매우 유사한 작업을 수행할 수 있는 소형 언어 모델을 신속하게 개발하고 있다고 지적했다.
또한 제한된 LLM에 대해 엄청난 가격을 지불할 의사가 없는 사람들이 있으며, 비슷한 품질의 무료 오픈소스 모델이 사용 가능할 때에는 더욱 그렇다는 설명이다.
세르누아는 라마를 유출한 메타에 대해 “역설적이게도 이 상황에서 유일한 승자는 메타다” 라고 주장했다. 모델이 유출됐지만 사실상 대부분의 오픈소스 혁신이 라마 위에서 이루어지고 어떤 장애물도 없이 바로 제품에 통합할 수 있게 됐기 때문이다.
나아가 구글이 소형 언어 모델들을 위한 기반 모델을 오픈소스로 공개해 오픈소스 커뮤니티와 협력함으로써 리더로 자리매김해야 한다고 강조했다.
박찬 기자 cpark@aitimes.com
