
지난해 11월 등장한 '챗GPT'는 전 세계에 '알파고 쇼크'에 버금가는 충격을 남겼다.
각국 정부와 기술 대기업들의 대응 행보도 빨라지고 있다.
특히 마이크로소프트(MS)는 12조원에 달하는 천문학적인 자금을 투자하며 챗GPT를 개발한 오픈AI에 바짝 다가섰다. 이전과는 확연하게 다른 파트너십을 바탕으로 거의 모든 사업분야와 제품군에 챗GPT를 접목해 나가는 중이다.
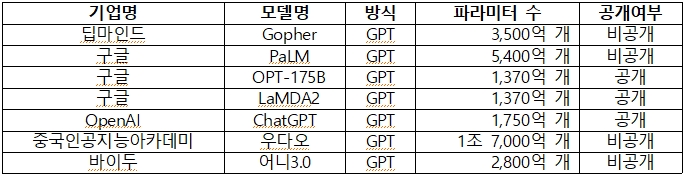
챗GPT 등장 이후 내로라하는 빅테크 기업들은 생성AI 모델 개발과 관련 서비스를 앞다퉈 출시하는 형국이다. 구글의 '바드(Bard)', MS의 빙챗(Bing-chat), 메타의 라마(LLaMA) 등이 대표 사례다.
영어 중심의 초거대 생성AI 모델이 대부분이다. 하지만 오픈소스로 공개해 대중화를 통한 시장 선점을 노리는 기업도 적지 않다.
중국은 정부 주도로 초거대 AI 모델을 구축하는데 투자를 집중하고 있고, 우리나라도 지난 4월 '초거대AI 경쟁력 강화 방안'을 발표하는 등 대응책 마련에 부심하고 있다.
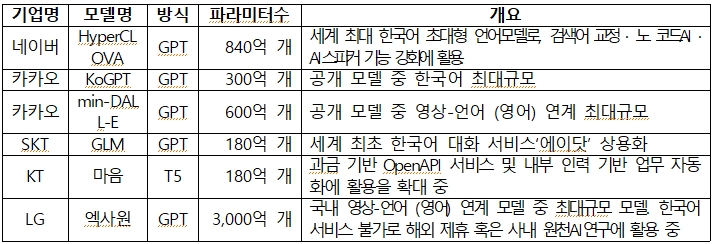
국내 기업 가운데는 포털과 통신사를 중심으로 거대 AI모델 구축이 이루어지고 있다. 우리말 서비스 성능을 높이는 데 집중하는 것으로 보인다.
특히 네이버는 '하이퍼클로바' 서비스를 고도화 해 상반기 중에 새로운 검색을 경험할 수 있는 '서치GPT'를 출시할 예정이다. 또 카카오브레인은 연내 'KoGPT' 기반 버티컬 AI서비스를 내놓기로 했다.
초거대 생성AI에는 여러가지 이슈가 있다.
우선 학습 데이터 부족을 꼽을 수 있다. 학습 데이터에 최신 데이터를 포함하지 못해나타나는 문제가 많다. 이는 신뢰성 문제로 이어진다.
초거대 생성AI를 훈련하고 운영하는 데는 과도하리만치 많은 컴퓨팅 자원을 필요로 한다는 점도 문제다. 최근들어 데이터 경량화 기술과 머신러닝 학습 추론 방법을 개선하기 위한 연구가 이어지고 있는 이유다.
초거대 AI 활용이 본격화되면서 AI의 비윤리성・편향성 이슈도 확산되는 추세다. 사전 학습 데이터 자체가 편중된 때문에 발생하는 문제다. 최근 이같은 문제를 해결하기 위해 데이터의 특징을 사전에 규명하고 분류하거나 제거하려는 연구가 이어지고 있다.
해외에서는 비윤리성과 편향성 완화를 위해 거대 IT기업에서 학습데이터 및 모델을 다양한 방법으로 검증하려는 시도를 하고 있다. 모델 및 데이터를 비상업적 용도로 공개하는 등 문제가 발생했을 때 빠르게 조치하기 위한 체계도 구축하는 중이다.
일례로 구글은 지난해 이미지/영상 처리 AI에 응용하기 위한 몽크 스킨 톤(MST: Monk Skin Tone) 피부색 구분 체계를 공개했다. 인종 기반 대신 채도에 따른 10단계 체계로 AI 모델을 평가해 인종적 편향성을 낮추려는 노력이었다.
네이버를 비롯한 국내 IT 기업들도 AI 윤리 준칙을 발표하고 있다. 또 KAIST는 인공지능 공정성 연구센터에서 AI 모델의 편향성을 판단하기 위한 프레임워크인 MSIT AI FAIR 2022를 개발하는 등 연구소 차원에서도 다양한 방법을 시도하고 있다.
가장 큰 문제는 '환각' 현상이다. 부적절한 답변 또는 거짓 답변을 생성하는 것을 방지하기 위한 연구가 절실한 시점이다. 이를 위해 최근 다양한 기술적 시도가 이어지고 있기는 하지만 아직은 해결방법이 명확하지 않다.
그랜드뷰리서치와 마켓앤마켓 분석에 따르면 초거대 생성AI 시장은 오는 2030년 이전까지 세계 AI시장의 10%를 차지할 전망이다. 고성장 시장이다.
눈여겨 봐야할 부분은 '챗GPT'의 등장으로 구글이 지난 10년간 지배했던 검색 광고 시장에 균열이 발생하고 있다는 점이다. 실제로 전세계 검색 광고 시장의 93.4%에 달하는 높은 점유율을 보이고 있는 구글이 챗GPT 등장 이후 'code red’를 발령하고 비상사태에 들어갔다. 반면에 시장 점유율 2.8%에 불과한 MS는 불과 몇 달만에 사용자가 6배 이상 증가하는 효과를 누렸다. 일일 사용자 1억명을 돌파하는 등 지금도 가파른 성장세를 보이고 있다.
그런데 오픈AI가 'GPT4'를 내놓으며 API 사용료를 15~53배까지 인상했다. 'GPT 3.5'는 1000단어당 약 3원(8K)이었는데 'GPT4'는 1000단어당 약 39.9(8K)~159.6원(32K)이다. 이는 초기에 무료로 서비스를 해오던 국내 서비스 기업에 큰 부담이 되고 있다.
더구나 우리나라의 초거대 생성AI 기술 수준은 논문과 특허 보유 측면에서 절대적인 열위에 놓여있따. 미국, 중국 등에 크게 뒤쳐진 상황이다. 올해 클래리베이트 조사 결과에 따르면 지난 2018~2022년 국가별 생성AI 상위 1% 특허 건수에서 중국이 256건, 미국은 159건에 달하는데 반해 우리나라는 9건에 불과한 것으로 나타났다.
우리나라 AI 생태계 수준은 54개국 가운데 8위에 올라 있다. 그러나 AI기술을 활용하는 전문 인력 부문에 해당하는 글로벌 AI인덱스에서는 미국을 100점으로 보았을 때 우리나라는 11.4점에 불과하다. 글로벌 추세에 크게 못미치는 수준이다.
국내 기업 가운데 가장 많은 인재를 확보한 네이버도 구글이나 MS와 비교하면 절반에도 못 미치는 상황이다. AI 인재 확보가 시급하다. 국내 AI 기업들이 하나같이 '인재 부족'을 가장 큰 애로사항으로 꼽고 있는 것도 당연하다.
국내 인공지능 생태계를 조금이라도 빨리 안정적으로 구축하기 위해서는 기업과 연구소의 이머징 기술 개발에 발맞춰 정부의 신속한 지원이 이루어져야 할 것으로 보인다.
가장 중요한 요소는 타이밍이다. 초거대 생성 AI의 등장은 우리 산업계에 '알파고' 이후 가장 큰 충격으로 다가왔다. 인공지능 산업이 이제 제2라운드에 돌입했다. 시의 적절한 민ㆍ관협력이 필요한 시점이다.
조영임 가천대 컴퓨터공학과 교수 yicho@gachon.ac.kr
