
메타가 생성 인공지능(AI) 모델의 학습에 따른 저작권 문제를 방지하기 위해 장치를 마련했다. 사용자의 데이터 학습 거부 요청을 받아 들이기 위해 양식(form)을 추가했다.
CNBC는 30일(현지시간) 메타가 페이스북 도움말 센터 리소스 섹션을 통해 '생성 AI 데이터 주체 권리(Generative AI Data Subject Rights)'라는 양식을 추가했다고 보도했다.
이에 따르면 메타는 양식을 통해 '인터넷 또는 라이선스가 있는 소스에서 공개적으로 사용할 수 있는' 데이터를 '제 3자 정보'라고 지칭했다. 이런 정보는 '예측과 패턴을 사용해 새로운 콘텐츠를 생성하는 생성 AI 모델을 훈련하는 데 사용되는 수십억개의 데이터' 중 일부를 나타낼 수 있다고 설명했다.
또 관련 게시물에서는 '다른 제공업체로부터 데이터를 라이선싱하는 것 외에도 웹에서 공개 정보를 수집한다'고 밝혔다. 예를 들어 이름이나 연락처 같은 개인 정보가 포함될 수 있다고 밝혔다.
즉 거부 의사를 따로 밝히지 않으면 페이스북 댓글이든 인스타그램 사진이든 잠재적으로 생성 AI 모델 교육에 사용할 수도 있다는 뜻이라고 CNBC는 설명했다.
메타의 대변인은 "최신 오픈 소스 대형언어모델(LLM) '라마 2'를 학습하기 위해 메타의 사용자 데이터를 활용하지 않았다"라고 말했다. 또 "사용자는 데이터 주체로서 권리를 행사할 수 있고 AI 모델을 훈련하는 데 데이터 사용을 반대할 수 있다”고 강조했다.
하지만 이는 기본 설정이 '사용 동의'로 설정, 사용자가 번거롭게 거부 항목을 찾아서 거부 의사를 밝혀야 하는 '옵트인(opt-in) 방식' 방식이다. 거부하는 방법을 모르면, 자신의 데이터를 AI 학습에 사용하도록 동의한 것과 같다. 이는 어도비가 지난해부터 실행했던 방식과 같다.
최근 AI 학습에 동의 없이 데이터를 가져다 썼다는 저작권 문제로 인해 메타나 오픈AI은 소송에 처해 있다. 이번 조치는 이런 문제에 대한 '보험'인 셈이다.
게다가 메타의 이번 양식 제출에는 해설이 필요할 정도다. 메타는 3가지 옵션 중 하나를 선택하도록 했는데, 각 항목은▲생성 AI에 사용하는 타사의 개인정보에 액세스하거나 다운로드 또는 수정하고 싶음 ▲생성 AI에 사용되는 타사의 개인정보를 삭제하고 싶음 ▲다른 문제가 있음 등이다.
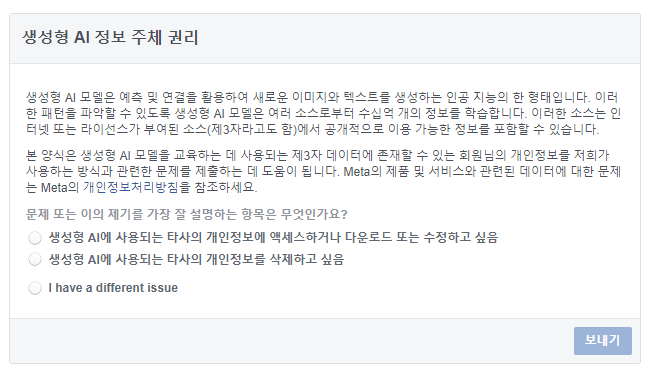
데이터를 AI 학습에 허용하기 싫은 경우 정답은 두번째 '삭제하고 싶음'이다. 첫번째를 선택하면 개인정보를 메타가 사용하거나 수정하도록 허락하겠다는 뜻이다.
한편, 오픈AI 역시 메타와 같은 의도로 이달초 LLM 학습 데이터 긁어 모으는 'GPT봇'을 출시하고, 동시에 차단 방법을 공개한 바 있다.
임대준 기자 ydj@aitimes.com
