
대형언어모델(LLM) ‘추론’ 벤치마크 테스트에서 엔비디아 GPU가 또 선두를 차지했다. 그러나 이번에는 인텔의 ‘가우디2(Gaudi2)’가 근소한 차이로 2위에 올랐다는 사실이 더 주목받았다. 인텔 제품이 추론 분야에서 엔비디아의 대안이 될 수도 있다는 평가다.
로이터는 11일(현지시간) ML퍼프(MLPerf)의 추론 벤치마크 테스트 결과, LLM 부문에서 인텔의 가우디2 칩이 엔비디아 'H100'에 약 10% 느린 성능을 기록했다고 보도했다.
ML퍼프는 인공지능(AI) 엔지니어링 컨소시엄인 ML커먼스가 마련한 벤치마크 테스트 기준이다. ML퍼프 추론은 참여 기업들이 이 기준을 토대로 자사 제품을 테스트하고, 그 결과를 ML커먼스에 제출하는 형태로 이루어진다.
다만 테스트는 참여 기업이 원하는 항목만 진행하기 때문에 그 자체로만 전체적인 비교 분석은 불가능하다.
ML커먼스는 이번 테스트를 위해 새로운 LLM 벤치마크를 도입한 ‘ML퍼프 추론 3.1 벤치마크’를 발표했다.
앞서 지난 6월 ML커먼스는 처음으로 LLM을 다루는 ‘ML퍼프 3.0 학습 벤치마크’를 공개했다. 당시 벤치마크 테스트 결과 엔비디아 H100 GPU가 8가지 범주에서 모두 새로운 기록을 세우며 압도적인 우위를 보였었다.
그러나 LLM을 학습하는 것은 추론을 실행하는 것과는 상당히 다르다. 학습을 통해 LLM은 단순히 정보를 획득하지만, 추론에서 LLM은 기본적으로 문장 작성이나 이미지 생성과 같은 생성 작업을 수행한다.
ML커먼스는 새로운 LLM 벤치마크가 60억개의 매개변수를 가진 'GPT-J' 참조 모델을 사용해 CNN과 데일리 메일의 뉴스 기사를 요약하도록 설계했다고 밝혔다. 즉 AI 데이터 처리의 추론 부분을 시뮬레이션한다는 설명이다.
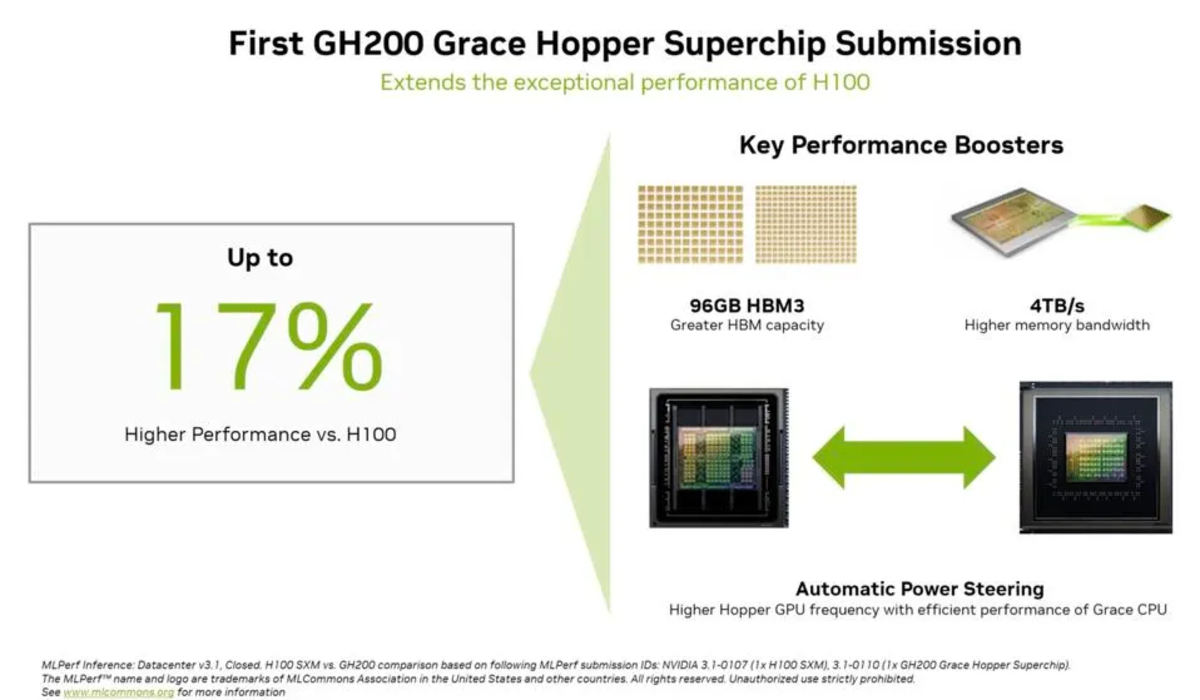
엔비디아는 네년 상반기에 상용화 예정인 최신 'GH200' 그레이스 호퍼 슈퍼칩과 H100 GPU 8개를 탑재한 'HGX 100' 시스템의 테스트 결과를 제출했다.
그 결과 엔비디아의 하드웨어는 컴퓨터 비전, 음성 인식 및 의료 영상 등 모든 테스트에서 최고 성능을 보였다. 또 LLM 추론 및 추천 시스템과 같이 더욱 까다로운 워크로드 측면에서도 상위권을 차지했다.
특히 GH200 그레이스 호퍼 슈퍼칩은 HGX 100보다 평균 성능이 약 17% 높은 것으로 나타났다.
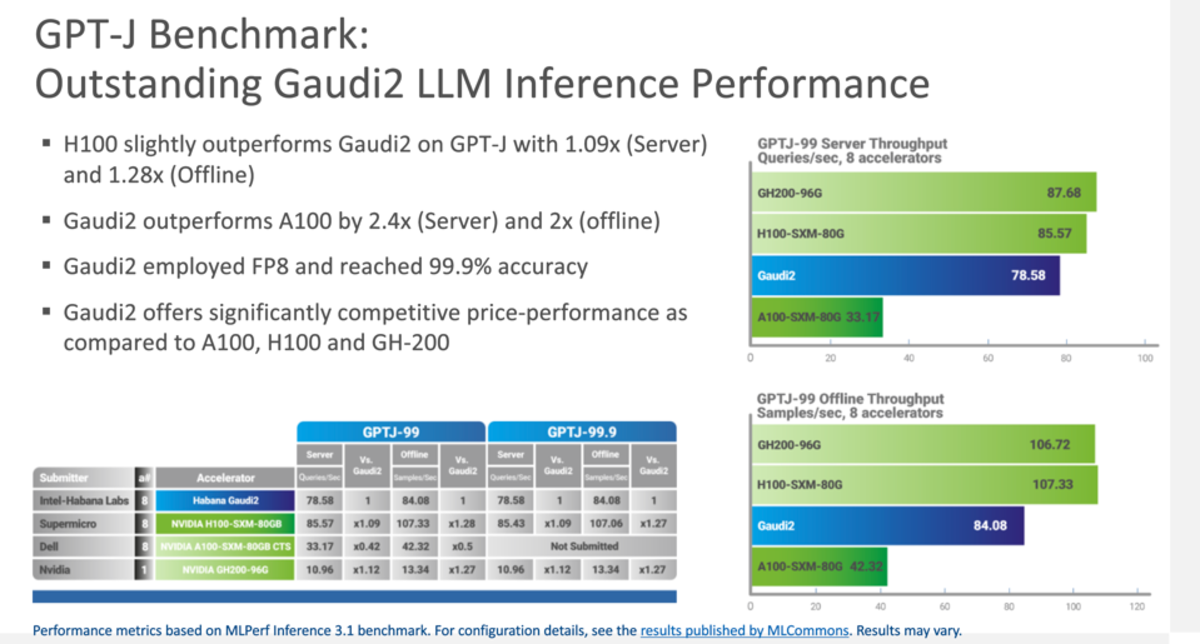
엔비디아가 1위를 차지했지만, 인텔의 자회사 하바나 랩스에서 제작한 가우디2 가속기는 턱밑까지 따라붙은 것으로 나타났다. 가우디2는 엔비디아 HGX 100보다 단지 10% 느린 것으로 나타났다.
인텔의 가우디2가 5나노미터 H100 GPU와 달리 7나노미터 제조 공정을 기반으로 한다는 점도 주목할만 하다. 또 인텔은 이번 달 말에 'FP8 정밀 양자화'라는 기능을 업데이트하면 AI 추론 성능이 최대 2배 향상될 것이라고 주장하고 았다. 5나노미터 가우디3 칩셋도 올해 말 출시 예정이다.
게다가 인텔은 이 정도 성능을 발휘하는 가우디2가 엔비디아보다 저렴, 경쟁력이 있다고 강조했다. 하지만 칩의 정확한 가격은 공개하지 않았다.
이외에도 구글은 자체 개발한 최신 TPU의 테스트 결과를 제출했지만, 엔비디아의 성능에는 미치지 못했다. 퀄컴은 경쟁 제품보다 적은 전력을 소비하는 퀄컴 클라우드 AI100 칩셋으로 좋은 성적을 거뒀다.
한편 엔비디아는 최근 GPU에서 구동하는 LLM 성능을 개선하는 ‘텐서RT-LLM(TensorRT-LLM)’ 소프트웨어를 출시했다. 텐서RT-LLM를 적용하면 H100의 경우 추론 성능을 2배까지 가속할 수 있다. 이번 벤치마크 테스트에 텐서RT-LLM을 적용했다면, 엔비디아 칩의 추론 성능이 크게 향상할 수도 있을 것으로 추정되는 부분이다.
박찬 기자 cpark@aitimes.com
