
스마트폰과 같은 엣지 기기에서 인공지능(AI) 모델 학습을 직접 실행할 수 있는 기술이 나왔다. 이를 통해 클라우드를 연결하지 않고 새 데이터를 기반으로 지속적인 온디바이스 AI 미세조정이 가능하게 될 전망이다.
MIT 뉴스는 16일(현지시간) MIT와 MIT-IBM 왓슨 AI 연구소 연구진이 엣지 기기의 수집 데이터로 AI 모델을 훈련하는 ‘포켓엔진(PockEngine)’기술을 공개했다고 소개했다.
일반적으로 엣지에서 AI 애플리케이션을 고도화하기 위해서는 최신 사용자 데이터를 클라우드 서버에 업로드, 모델을 미세조정해야 한다. 그러나 이 방법은 클라우드 연결에 따른 비용 문제뿐 아니라 데이터를 장치 외부로 유출하는 보안 문제가 발생한다.
포켓엔진은 이를 해결하기 위해 AI 모델이 엣지 기기에서 직접 새 데이터에 효율적으로 적응할 수 있도록 지원한다. 특히 정확성을 높이기 위해 AI 모델의 어느 부분을 업데이트해야 하는지 결정, 계산 오버헤드를 최소화하고 미세조정 속도를 향상한다.
연구진은 기존 방법과 비교한 결과 포켓엔진이 일부 하드웨어 플랫폼에서 모델 정확도를 유지하면서 수행속도는 최대 15배 더 빨라지게 했다고 전했다. 또 포켓엔진의 미세조정 방법이 복잡한 질문에 답변하는 AI 챗봇의 성능도 크게 향상하는 것을 발견했다.
송 한 MIT 컴퓨터과학과 교수는 “기기 내 미세조정을 통하면 개인정보 강화와 비용 절감, 맞춤화 기능, 평생 학습 등이 가능하다. 하지만 제한된 리소스 내에서 이를 처리하기란 쉽지 않다. 포켓엔진을 사용하면 엣지 기기에서 추론뿐 아니라 학습도 실행할 수 있게 된다”라고 말했다.
AI 모델은 예측을 위한 데이터 처리 담당 레이어를 다수 연결한 신경망으로 구성된다. 추론의 경우, 모델이 실행되면 입력 데이터는 최종 예측 출력까지 레이어에서 레이어로 전달된다. 추론 중 각 레이어에 전달된 데이터는 일단 처리되면 더 이상 저장할 필요가 없다.
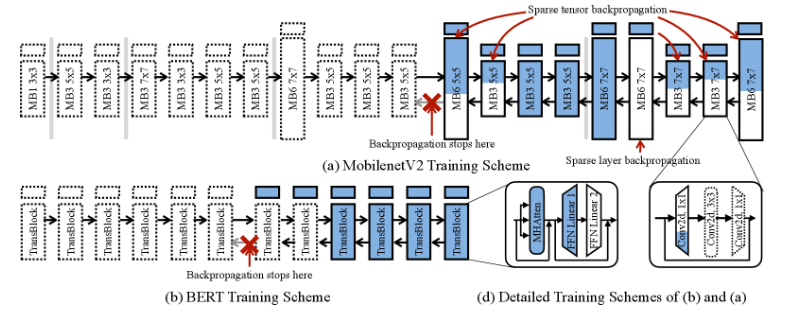
그러나 학습 및 미세조정 중에는 '역전파(backpropagation)'라는 프로세스가 발생한다. 역전파에서는 출력을 정답과 비교한 다음 모델을 역방향으로 거슬러 올라가며 각 레이어의 출력이 정답에 미친 영향을 계산해 저장한다. 이러한 레이어의 중간 결과를 저장해야 하기 때문에 추론보다 학습 및 미세조정에는 더 많은 메모리가 필요하다.
연구진은 신경망의 모든 레이어가 정확도 향상에 중요한 것은 아니며 중요한 레이어의 경우에도 전체 레이어를 업데이트할 필요가 없을 수도 있다고 지적했다. 업데이트가 필요하지 않은 전체 또는 부분 레이어을 비롯해 필요없는 요소를 정확히 찾아냄으로써 포켓엔진은 미세조정 속도를 높이고 계산과 메모리 양을 줄인다는 설명이다.
일반적으로 역전파 그래프는 런타임 중에 생성되므로 많은 계산이 필요하다. 역전파 그래프는 모델에서 각 레이어의 출력이 정답에 미친 영향을 계산한 그래프다. 포켓엔진은 런타임 중에 사용할 효율적인 역전파 그래프를 컴파일 시간에 생성하고 추가 최적화를 수행, 효율성을 향상한다.
이런 작업은 컴파일 시간에 한번만 수행하면 되기 때문에 런타임 중 계산 오버헤드가 크게 줄어든다.
한 교수는 “하이킹을 떠나기 전과 같다. 집에서 어떤 길을 갈 것인지 어떤 길을 무시할 것인지 신중하게 계획을 세우면 실제로 하이킹을 할 때 사간과 수고가 줄어드는 것과 같다”라고 설명했다.
애플 'M1' 칩과 스마트폰이나 라즈베리 Pi 컴퓨터에서 사용하는 '디지털 신호 프로세서(DSP)' 등 엣지 장치의 AI 모델에 포켓엔진을 적용했을 때 정확도 저하 없이 최대 15배 빠르게 온디바이스 학습을 수행한다는 실험 결과를 얻었다. 또 포켓엔진은 미세조정에 필요한 메모리 양을 크게 줄일 수 있었다.
또 대형언어모델(LLM) '라마 2'에 적용한 결과 복잡한 언어 작업을 처리하는 데도 효율성을 입증했다고 전했다.
앞으로는 텍스트와 이미지를 함께 처리하는 대형멀티모달모델(LMM) 미세조정에도 포켓엔진을 적용할 계획이다.
연구진은 "포켓엔진은 엣지 장치의 제한된 리소스에서 개인 정보 보호, 비용 효율성, 사용자 정의 및 평생 학습 기능을 제공하는 혁신적인 솔루션"이라고 강조했다.
에리 맥로스티 아마존 AGI 수석 관리자는 “이 작업은 다양한 산업 분야에서 LLM을 채택할 때 문제가 되는 효율성 문제를 해결한다"라며 "더 큰 모델을 통합하는 엣지 애플리케이션에 대한 가능성을 제공할 뿐만 아니라 클라우드에서 대규모 AI 모델을 유지하고 업데이트하는 비용을 줄이는 데도 도움이 된다”라고 연구의 중요성을 강조했다.
박찬 기자 cpark@aitimes.com
