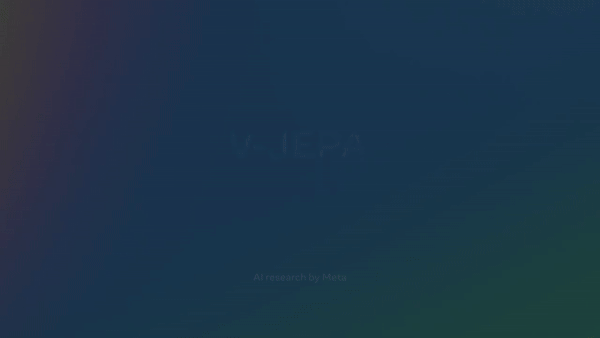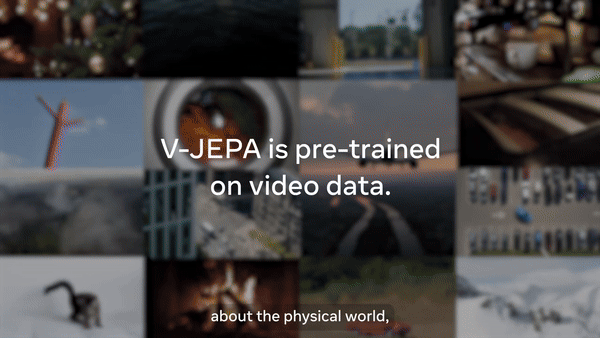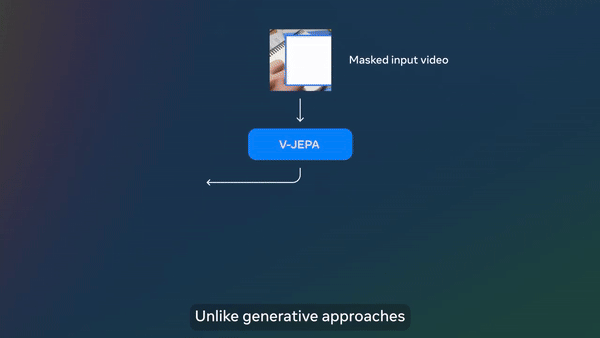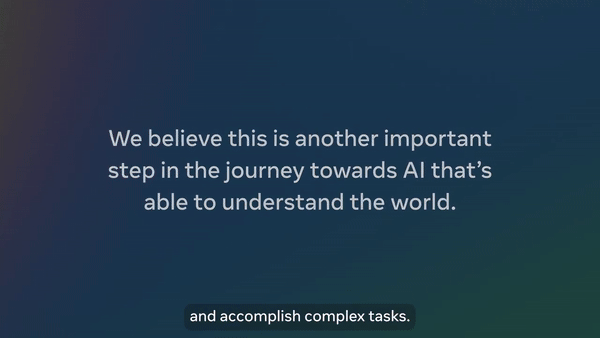
메타가 인간이 세상을 이해하는 방식과 유사하게 비디오를 이해하는 새로운 인공지능(AI) 모델을 출시했다. 무슨 일이 일어나고 있는지 말해주지 않아도, 지켜보는 것만으로 학습하는 것과 비슷한 방식이다. 비디오 속 객체와 장면 간의 상호 작용을 분석, 세상에 대한 기계의 이해를 향상한다는 설명이다.
메타는 16일(현지시간) 비디오에서 누락된 부분이나 가려진 부분을 예측 생성하는 AI 모델 ‘V-제파(V-JEPA)’을 블로그를 통해 공개했다.
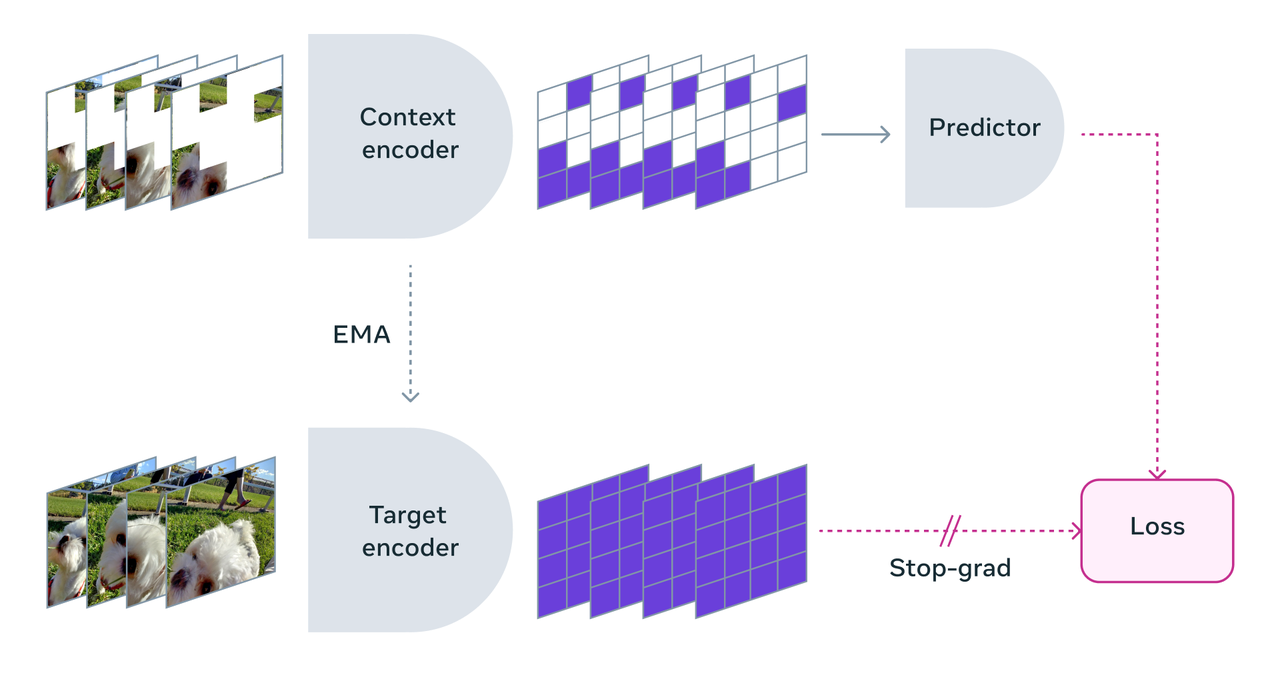
이 모델은 얀 르쿤 메타 수석 AI과학자가 주도로 개발됐으며, 인간과 유사한 방식으로 비디오를 이해하기 위해 개발된 AI 아키텍처다. 픽셀 수준에서 비디오의 누락된 부분을 재구성하려는 기존 생성 AI 모델과 달리, 추상적 표현 공간에서 누락되거나 가려진 영역을 예측하는 비생성(nongenerative) AI 모델이다.
이는 모델이 새로운 콘텐츠를 생성하거나 누락된 픽셀을 직접 채우지 않는다는 것을 의미한다. 대신 비디오의 각 프레임을 큰 블록 단위로 나눈 블록 간의 의미론적(semantic) 공간 정보과 시간의 흐름에 따라 일어나는 프레임간의 세부적인 정보를 학습함으로써 비디오의 누락된 부분을 예측한다.
메타는 "V-제파는 세밀한 개체 상호 작용과 시간에 따라 발생하는 상세한 개체 간 상호 작용을 구별하는 데 가장 잘 작동한다”라고 말했다. 예를 들어, 모델은 누군가가 펜을 내려놓는지, 펜을 집는지, 펜을 내려놓는 척하는지의 차이를 구분할 수 있다. 다만 현재는 약 10초 정도의 짧은 시간에서만 예측이 가능하다.
또 V-제파는 라벨을 지정하지 않은 비디오에서 학습하는 것이 특징이다. 이는 아이들이 지켜보는 것만으로 학습하고, 무슨 일이 일어나고 있는지 말해 줄 사람이 필요하지 않은 것과 같다. 이를 통해 학습이 더욱 빠르고 효율적으로 이루어진다. 모든 픽셀을 채우려고 하기보다는, 스마트한 방법으로 동영상에서 누락된 부분을 찾아내는 데 중점을 둔다.
메타는 V-제파가 비디오의 모든 프레임에 대해 모든 픽셀을 수집하고 분석할 필요가 없기 때문에 훈련 효율성을 1.5~6배 향상할 수 있다고 주장했다.
메타는 향후 영상과 함께 오디오 콘텐츠는 처리할 수 있도록 오디오를 통합, V-제파의 기능을 확장할 계획이다. 현재는 깃허브에서 연구목적으로 사용할 수 있다.
박찬 기자 cpark@aitimes.com
