
구글이 대형언어모델(LLM)의 답변을 검색으로 확인하는 LLM을 개발했다. 이 방식은 인간이 확인할 때보다 높은 정확도를 기록했다는 설명이다.
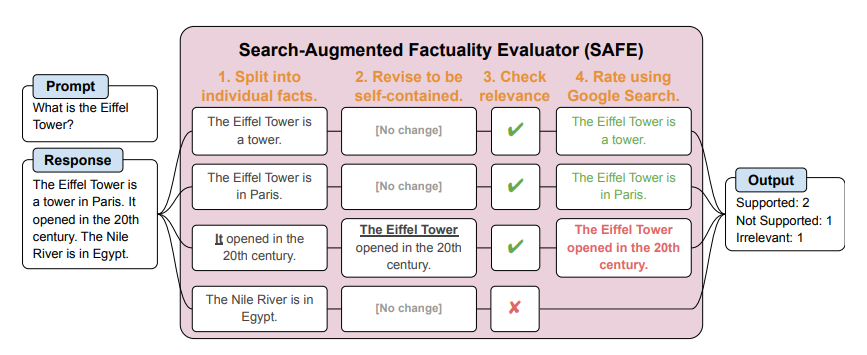
벤처비트는 28일(현지시간) 구글 딥마인드의 인공지능(AI) 전문가 팀이 'SAFE(검색증강 사실 평가자)'라는 시스템을 개발했다고 보도했다.
이 방식은 LLM의 답변이 사실인지 확인하기 위해 인간이 구글 검색 엔진 등을 이용해 응답에 대한 소스를 찾는 방법과 동일하다. 연구진은 별도의 LLM을 구축, 구글 검색을 사용해 정답을 확인했다.
시스템을 테스트하기 위해 '롱팩트(LongFact)'라는 벤치마크를 통해 '챗GPT'와 '제미나이', '클로드', '팜 2' 등 LLM 4개 제품의 답변에 포함된 약 1만6000개의 사실을 확인했다.
그 결과 SAFE가 크라우드소싱을 통한 인간 확인 결과와 72% 일치한다는 사실을 발견했다. 특히 SAFE와 인간 체크가 일치하지 않을 경우, SAFE가 76%의 경우에서 올바르다고 밝혔다.
또 큰 모델일수록 일반적으로 사실적 오류가 적지만, 최고 성능을 발휘하는 모델이라고 해도 상당수의 허위 사실을 출력한다고 지적했다.
특히 이 방식의 강점은 비용 문제로 나타났다. SAFE는 인간 체크보다 약 20배 저렴하다는 설명이다. LLM에 의해 생성된 정보의 양이 계속 폭발적으로 증가함에 따라, 이를 검증하는 경제적이고 확장 가능한 방법으로 주목받고 있다고 평이다.
연구진은 깃허브에 SAFE를 공개, 모든 사람이 사용할 수 있도록 개방했다.
임대준 기자 ydj@aitimes.com
