
최근 인공지능(AI) 물결이 전 세계를 덮치며 사람들은 그 어느 때보다 AI와 긴밀히 연결된 삶을 살고 있다. 특히 요즘은 AI의 기반이 되는 대형언어모델(LLM), 즉 파운데이션 모델이 떠오르고 있다.
LLM은 엄청난 양의 데이터로 자기지도학습(self-supervision)을 수행하는 머신러닝 모델이다. 데이터에 있는 전반적인 패턴을 학습, 다양한 패턴과 관계성을 활용해 각종 태스크에 활용할 수 있다.
즉 여러 작업을 수행하는 LLM의 등장으로 각 태스크를 위한 모델을 따로 구축할 필요가 없어진 것이다. 결과적으로 시간과 자원을 절약하는 것은 물론, 자연어처리와 컴퓨터비전 및 멀티모달 AI 분야에서 많은 발전을 이룰 수 있었다.
LLM의 기반이 되는 아키텍처 '트랜스포머', 그중에서 '비전 트랜스포머'를 소개하며 멀티모달 영상이해 기술을 소개하고자 한다. 이는 트웰브랩스가 보유한 핵심 기술이기도 하다.
트웰브랩스는 영상 기반 멀티모달모델을 개발하는 국내 AI 스타트업이다. 많은 양의 데이터를 학습해 영상의 시각 정보를 이해하는 기술을 보유했다. 이 외에도 영상 속 음성 언어, 소리, 등장인물, 문자 등 다양한 정보를 총괄적으로 이해, 영상에서 필요한 정보를 검색할 수 있는 멀티모달 기술을 개발했다.
수만개의 영상 속에서 ‘파도 위를 달리는 남자'나 ‘스티브 잡스가 어떻게 아이폰을 소개했는가'와 같은 장면을 간단히 검색해 원하는 순간을 찾을 수 있다.
영상언어 생성 모델인 ‘페가수스-1’은 자체 개발한 800억 매개변수 규모의 언어모델을 바탕으로, 영상 요약과 영상 기반 질의응답 등 비디오-텍스트(video to text) 소통을 가능하게 한다. 트랜스포머 아키텍처를 사용해 특정 상황에 대한 영상별 언어모델 구축 과정을 생략, 기간을 단축했다.
트웰브랩스는 영상을 이해하는 하나의 LLM을 토대로, 관련 모든 작업의 자동화를 추구하고 있다. 향후 다양한 영역에서 영상 분석 AI의 쓰임새가 늘어날 것으로 예상한다.
비전 트랜스포머 (Vision Transformers)
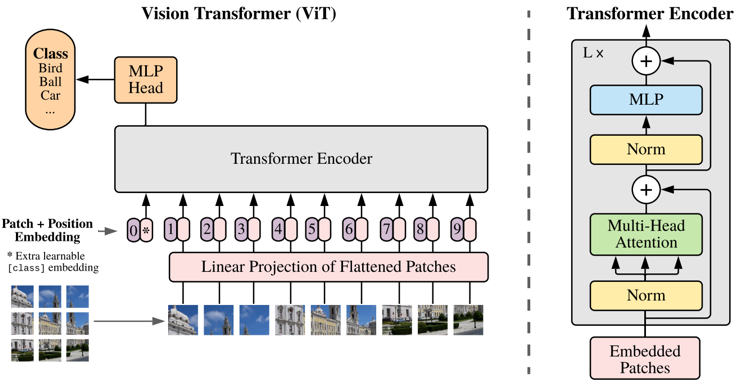
원래 컴퓨터 비전 분야에서 가장 많이 사용하는 아키텍처는 컨볼루션 신경망(CNN)이었다. 하지만 자연어처리(NLP)에서 트랜스포머 아키텍처가 성공을 거두자, 연구자들은 트랜스포머를 이미지 데이터에도 적용하기 시작했다. 그렇게 비전 트랜스포머가 등장하게 됐다.
특히 트랜스포머 아키텍처의 인코더 블록을 이미지 분류 문제에 적용하는 비전 트랜스포머(ViT) 아키텍처는 논문(An Image is Worth 16 x 16 Words: Transformers For Image Recognition at Scale)에서 찾아볼 수 있다.
논문의 저자는 이미지를 패치로 나누고(split into patches), 이런 패치들을 펼쳐 선형으로 만든 후, 해당 임베딩(linear embeddings)을 트랜스포머에 입력(input)한다고 기재했다. 이런 이미지 패치는 자연어처리의 토큰처럼 입력으로 다뤄진다는 설명이다.
ViT 아키텍처는 이미지를 패치화하는 단계, 멀티-레이어 트랜스포머 인코더 단계, 그리고 글로벌 표현(Representation)을 출력 라벨(output label)로 변환하는 멀티-레이어 퍼셉트론(MLP) 단계를 포함한다. ViT는 사전학습 비용이 비교적 저렴하고, 여러 이미지 분류 데이터셋에서 최첨단 결과를 달성하거나 뛰어넘기도 한다.
ViT의 특징 및 한계점
하지만 몇 가지 문제점도 있다. 그중 하나는 고해상도 이미지 처리에 어려움을 겪는다는 것이다. 이미지가 커지면 엄청나게 많은 컴퓨팅 파워를 필요로 하기 때문이다. ViT의 토큰 수는 고정돼 있기 때문에, 다양한 크기의 시각적 요소를 포함하는 태스크에는 사용하기가 애매해진다.
ViT의 한계적인 특징으로는 CNN과 비교했을 때 유도 편향(inductive bias)이 적다는 점을 꼽을 수 있다. 유도 편향은 머신러닝 문제를 더 잘 풀기 위해 모델에 사전적으로 추가하는 가정들을 일컫는다. 예를 들어 비전, 즉 시각적인 정보를 다룰 때 픽셀 간의 집약성(locality)이 존재한다고 가정하면 공간 정보를 잘 뽑아낼 수 있게 된다.
무조건 패치를 활용해 표현에 한계가 있는 CNN과는 달리, ViT는 모델의 자유도가 높다는 의미다. 하지만 그만큼 제너럴리스트에 가까운 모델이 되기 때문에, 더 많은 데이터를 필요로 한다.
트웰브랩스의 차별점은 대용량 데이터를 학습, 트랜스포머 기반에서도 성공적으로 이미지와 영상을 이해하도록 만들었다는 것이다. 즉 ‘비전 트랜스포머’의 성공적 예시다.
트웰브랩스 개발 부서
