한국과학기술원(KAIST)과 LG AI연구원 등 국내 연구진이 해외 유명 연구소와 협력, 대형언어모델(LLM) 모델의 성능을 평가하는 새로운 오픈 소스 벤치 마크 도구를 선보였다. 기존 벤치 마크의 단점을 보완하고 인간 선호도와 비슷한 결과를 내기 위해 2가지 방식을 병합한 것이 특징이다.
마크테크포스트는 4일(현지시간) KAIST, LG AI연구원, 카네기멜론대학교, MIT, 앨런 AI연구소, 일리노이대학교 시카고 등의 연구진이 '프로메테우스 2(Prometheus 2)'라는 새로운 벤치 마크 모델을 발표했다고 소개했다.
이 벤치마크 도구는 기존 LLM 평가 도구의 단점을 뛰어넘기 위해 2가지 방법을 합쳐놓은 것이다.
연구진은 "GPT-4와 같은 LLM은 다른 LLM의 품질을 평가하는 데 종종 사용된다"라며 "하지만 투명성, 제어 가능성, 경제성 등에서 약점이 있다"라고 전했다.
또 "기존 오픈 소스 평가 도구는 사람의 선호도와는 크게 다른 평가를 내리고, 직접 평가와 비교 평가를 모두 수행할 수 있는 유연성이 부족하다"라고 지적했다.
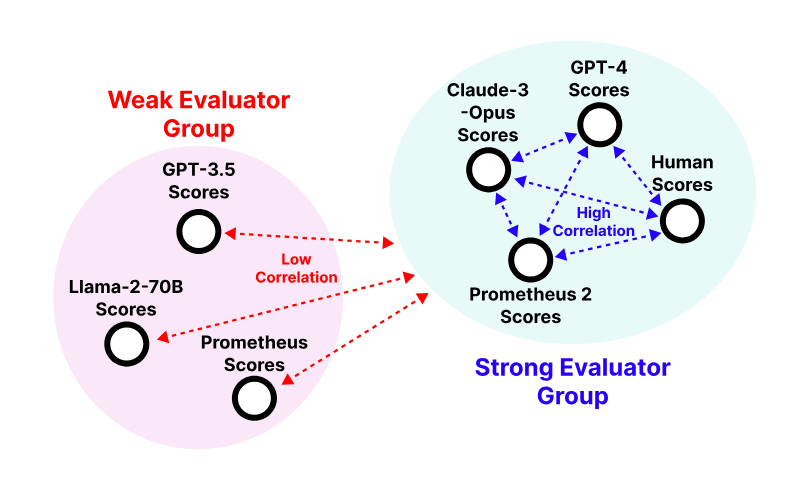
따라서 이런 문제를 해결하기 위해 인간은 물론, GPT-4의 판단과 가까운 강력한 벤치 마크 도구 프로메테우스 2를 개발했다고 전했다. 이는 기존에 발표한 '프로메테우스'를 업그레이드한 것이다.
설명대로 ▲기존과 같이 LLM 성능을 측정하는 단일 도구와 ▲두 모델의 성능을 비교하는 쌍별(Pairwise) 테스트 두가지 도구를 병합했다.
여기에 도구의 성능을 높이기 위해 1000개의 새로운 항목을 갖춘 우선 수집(Preference Collection) 데이터셋을 활용했다. 두가지 교육 형식을 효과적으로 결합, 선형 병합 접근 방식을 통해 장점을 혼합해 평가 작업 전체에서 높은 성능을 보인다는 설명이다.
실제로 비쿠냐 벤치(Vicuna Bench), MT 벤치, 플라스크(FLASK) 벤치, 피드백(Feedback) 벤치 등 4가지 직접 평가 벤치마크에 대한 테스트에서 인간이나 GPT-4와 가장 가까운 상관 관계를 보였다. 기존 오픈 소스 모델보다 뛰어난 성능을 발휘, 85%가 넘는 정확도 점수를 달성했다.
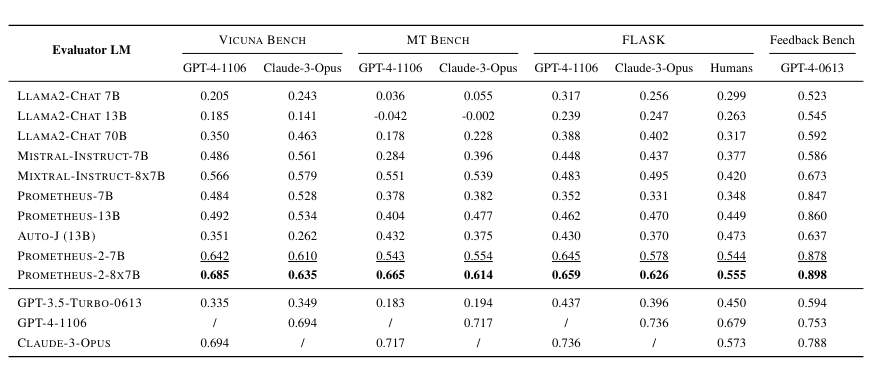
이는 프로메테우스 2가 LLM 성능 평가에 뛰어날 뿐더러, 고비용의 독점 솔루션을 대체할 수 있는 오픈 소스 벤치마크 도구로 상당한 잠재력이 있다는 것을 보여준다고 밝혔다.
연구진은 "인간의 판단과 흡사한 투명하고 확장 가능하며 적응 가능한 LLM 벤치마크 도구를 개발하는 것은 자연어처리(NLP) 발전의 중요한 과제"라며 "프로메테우스 2는 오픈 소스 평가의 중요한 발전을 나타내며 독점 솔루션에 대한 강력한 대안을 제공한다"라고 강조했다.
프로메테우스 2 모델과 코드, 데이터는 깃허브를 통해 공개됐다.
임대준 기자 ydj@aitimes.com
- 클로드3·GPT-4의 수학 실력은 "암기 아닌 추론"...'과적합' 벤치마크 발표
- 허깅페이스, LLM '의료 지식' 평가하는 벤치마크 공개
- 올거나이즈, '금융 전문' LLM 리더보드 최초 공개…“산업 영역 순차적으로 늘릴 것”
- "기존 벤치마크 한계 도달"...새로운 LLM 평가 수단 속속 등장
- 김기응 KAIST 교수, AI 에이전트 분야 '영향력 있는 논문상' 수상
- 애플 M4 칩, 벤치마크서 인텔 제치고 최고 CPU 등극
- KAIST,국내 최대 규모 첨단 양자팹 구축 추진
- KAIST-앨런 튜링 연구소, AI·데이터 과학 공동 연구 추진
- LG디스플레이, 생성 AI 자체 개발해 업무혁신 가속화
- KAIST "GPT-4V 뛰어넘는 오픈 소스 LMM 개발"
