구글이 동영상에 맞는 음성 및 음향 효과를 생성하는 인공지능(AI) 기술을 개발 중이라고 밝혔다. 이는 피카랩이나 일레븐랩스, 스태빌리티 AI는 물론 국내 가우디오랩 등도 개발 중인 기능으로, 동영상 생성 AI의 발전과 함께 음향 분야의 경쟁도 치열해지는 양상이다.
구글 딥마인드는 17일(현지시간) 공식 블로그를 통해 비디오와 오디오, 텍스트 프롬프트 등을 사용해 영상 사운드트랙을 생성하는 'V2A(비디오-오디오)' 기술을 개발 중이라고 소개했다.
딥마인드는 “비디오 생성 AI는 놀라운 속도로 발전하고 있지만, 대부분은 소리를 포함하지 않는다"라며 "V2A 기술은 생성 영화에 생명을 불어넣는 유망한 접근 방식이 될 수 있다"라고 설명했다.
실제 이날 공개한 샘플은 구글이 지난달 공개한 동영상 생성 AI '비오'의 클립을 활용했다.
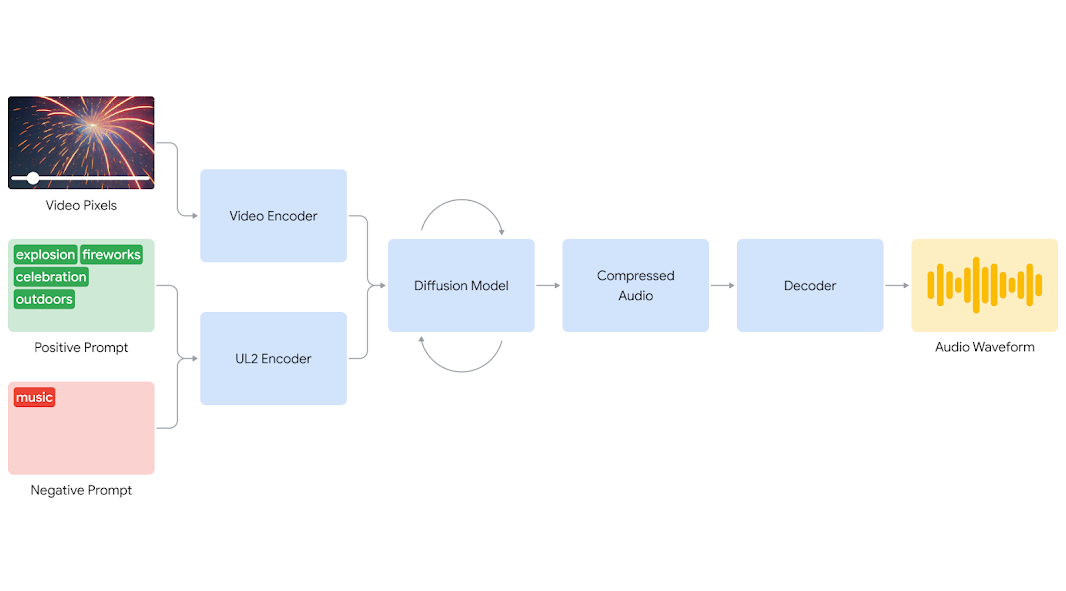
이 기술은 비디오와 들어맞는 다양한 소리는 물론 대화까지도 생성해 낸다. AI가 영상의 픽셀을 이해, 상황에 맞는 음향과 음성을 생성하는 원리다. 즉, 영상만 올리면 AI가 알아서 소리를 만들어 준다.
이미지 생성 AI와 같은 확산 모델(Diffusion Model)을 사용했으며, 비디오와 사운드, 대화 내용의 조합을 학습 데이터로 사용했다.
이런 모델은 생성 AI 비디오 확산은 물론, 기존 영화 작업 등에도 큰 영향을 미칠 수 있다는 분석이다.
구글과 흡사한 기술을 개발 중인 국내 스타트업 가우디오랩은 영상 프롬프트가 보편화되면 상당 시간을 잡아먹던 영화 후반부의 사운드 작업이 획기적으로 빨라질 것이라고 전한 바 있다. 딥마인드도 기록물이나 역사적 영상 작업자들에게 유용할 것으로 내다봤다.
이런 까닭에 피카랩은 지난 3월 이미 생성 영상에 음성과 음향 효과를 입히는 기능을 유료로 출시했다. 일레븐랩스와 스태빌리티AI도 지난달 같은 기능을 공개했다.
구글은 아직 V2A가 완전한 것은 아니라고 설명했다. 많은 영상으로 훈련하지 않았기 때문에, 아직 고품질 음향을 생성하지는 못한다고 밝혔다.
또 이런 이유와 오용 방지를 위해 이 기술을 대중에게는 당장 공개하지 않을 것이라고 덧붙였다.
딥마인드는 “V2A 기술은 먼저 선도적인 제작자와 영화 제작자의 작업을 통해 피드백을 수집, 고도화할 것”이라며 "본격 출시에 앞서 엄격한 안전성 평가와 테스트를 거칠 것"이라고 말했다.
임대준 기자 ydj@aitimes.com
