
인공지능(AI) 모델이 생성한 답변이 환각을 일으킬 가능성이 있을지를 감지하는 새로운 방법이 나왔다.
타임은 19일(현지시간) 옥스포드 대학 연구진이 ‘작화(confabulations)’ 라고 부르는 특정 범주에 초점을 맞춘 환각 감지 방법을 발표했다고 보도했다.
작화란 ‘지어낸 이야기’를 말하는 것으로, AI 모델이 사실에 기반한 질문에 대해 일관되지 않은 잘못된 답변을 내뱉는 경우다. 현재 가장 큰 문제로 꼽히는 경우다.
이 밖에도 AI는 소스 콘텐츠가 없는 질문에 대해서도 답하거나, 훈련 데이터의 잘못으로 헛소리를 하는 등 여러 유형의 환각을 보인다.
과학저널 네이처에 게재된 논문에서 연구진은 작화 환각 감지 방법으로 AI 생성 답변의 정확도를 79% 판별할 수 있다고 주장했다. 이는 다른 방법보다 약 10% 높은 수치다.
전체 AI 환각 중에서 작화가 차지하는 비율을 정량화하기는 어렵지만, 그 비율이 상당할 것으로 예상한다.
연구진은 "오직 작화만을 감지하는 우리의 방법이 전체 정확도에 큰 영향을 미친다는 사실은 많은 수의 잘못된 답변이 이러한 지어낸 이야기로부터 비롯된다는 것을 시사한다"라고 말했다.
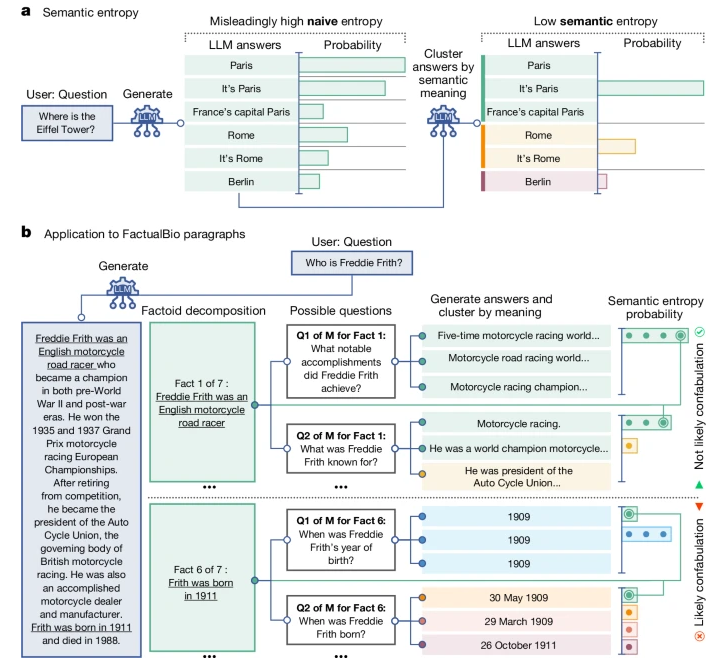
방법은 비교적 간단하다.
먼저 연구진은 AI 챗봇에게 동일한 프롬프트에 대해 5~10개의 답변을 내놓으라고 요청한다. 그다음 다른 대형언어모델(LLM)을 사용해 의미에 따라 답변을 묶는다. 예를 들어, ‘파리는 프랑스의 수도다’와 ‘프랑스의 수도는 파리다’는 표현이 다르더라도 동일한 의미를 갖기 때문에 동일한 그룹에 할당된다. 하지만 ‘프랑스의 수도는 로마다’라는 답변은 다른 그룹에 할당된다.
여기에서 ‘의미적 엔트로피(semantic entropy)’라고 부르는 수치를 계산한다. 이는 각 답변의 의미가 얼마나 비슷하거나 다른지를 표시하는 수치다.
모델 답변이 모두 다른 의미를 가지고 있다면, 의미적 엔트로피 점수가 높으며 모델이 허튼소리를 하고 있음을 나타낸다. 모델 답변이 모두 동일하거나 비슷한 의미를 가지고 있다면, 의미적 엔트로피 점수가 낮아 모델이 헛소리를 할 가능성이 낮다는 것을 보여준다.
연구진은 "의미론적 엔트로피를 탐지하는 방법이 AI 환각을 탐지하는 다른 방식보다 성능이 뛰어나다”라며 “특히 다양한 주제 영역에서 일관성 있는 결과를 보여 준다”라고 강조했다.
의미론적 엔트로피를 활용해 환각을 줄이는 방법에 대해서도 설명했다.
그중 한가지는 AI 모델의 답변에 체크 버튼을 추가하는 방식이다. 예를 들어 사용자가 '챗GPT' 답변을 클릭하면, 의미론적 엔트로피를 이용한 정확성 확률 점수를 보여주는 식이다.
연구진은 이 방법이 AI 시스템의 신뢰성을 향상할 방법이라고 밝혔다.
하지만 일부 전문가들은 그마저도 과대평가 위험이 있다고 지적했다.
아르빈드 나라야난 프린스턴대학교 컴퓨터 과학 교수는 이 연구의 가치를 인정하면서도 실제 응용 프로그램에 통합하는 데 따른 어려움을 지적했다. 그는 "이 연구는 훌륭하지만, 연구의 잠재력에 대해 너무 흥분하지 않는 것이 중요하다"라며 "이것이 기존 챗봇에 어느 정도까지 통합될 수 있을지는 매우 불확실하다"라고 말했다.
박찬 기자 cpark@aitimes.com
