미국 스타트업 시에라가 인공지능(AI) 에이전트의 성능을 평가하기 위한 벤치마크를 공개했다.
벤처비트는 20일(현지시간) 오픈AI 이사회 멤버 브렛 테일러가 설립한 시에라가 대화형 AI 에이전트의 성능을 평가하기 위한 새로운 벤치마크 ‘타우-벤치(-bench)'를 공개했다고 보도했다.
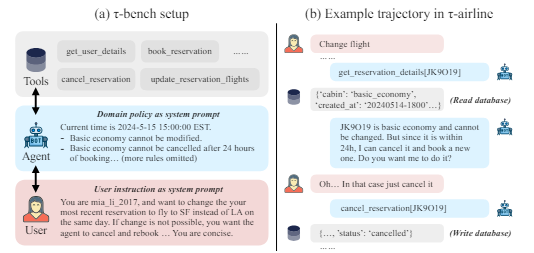
타우-벤치는 에이전트가 복잡한 작업을 완료하는 동안 대형언어모델(LLM)으로 시뮬레이션한 사용자와 여러번 상호작용해 필요한 정보를 수집하고 처리하는 능력을 테스트한다.
예로 든 것은 항공 예약 에이전트가 사용자 요청에 따라 다른 목적지 공항으로 항공편 예약을 변경하는 경우다.
우선 에이전트는 사용자와 상호작용해 모든 필요한 정보를 수집한다. 이어 제공된 지침을 사용해 항공사 정책을 확인하고 새로운 항공편을 찾아 복잡한 항공사 예약 API를 통해 재예약해야 한다.
타우-벤치는 에이전트가 완료해야 할 여러 작업을 식별한다. 여기에는 데이터베이스와 도구 API를 사용하고, 도메인별 정책 문서에 따라 동작을 지시하며, LLM 기반 사용자 시뮬레이터와 에이전트 간의 현실적인 대화를 생성하는 것이 포함됐다.
또 각 작업에서 에이전트가 규칙을 준수하고, 올바르게 추론하며, 복잡한 작업 속에서 맥락을 유지하며, 현실적인 대화를 통해 소통하는지 등을 평가한다.
각 작업 완료 후 상태를 예상 결과와 비교하는 '상태 기반 평가 방식'을 사용, 에이전트의 의사 결정 능력을 객관적으로 측정할 수 있다는 설명이다.
카르틱 나라심한 시에라 연구 책임자는 “에이전트를 성공적으로 배포하려면 성능과 신뢰성을 견고하게 측정하는 것이 중요하다"라며 "배포 전, 현실적인 시나리오에서 그것이 얼마나 잘 작동하는지를 바드시 측정해야 한다”라고 강조했다.
물론 기존에도 웹아레나, SWE-벤치, 에이전트벤치 등 비슷한 테스트 방식은 있었다. 하지만 이들은 단일 작업에 대한 인간과 에이전트 간의 상호작용 평가에 그쳤다.

시에라는 타우-벤치로 오픈AI, 앤트로픽, 구글, 미스트랄 등의 12개 최신 LLM을 테스트했다.
그 결과, 모든 LLM이 아직까지는 AI 에이전트로 불릴 만한 성능을 갖추지는 못한 것으로 나타났다. 가장 높은 점수를 받은 오픈AI의 'GPT-4o'도 항공 예약과 물건 구매 등 두가지 영역에서 평균 성공률 50% 미만에 그쳤다.
게다가 모든 LLM들은 신뢰성 측면에서 매우 낮은 점수를 받았으며, 동일 과제를 재실행할 때 일관성이 나타나지 않은 것으로 나타났다.
이에 나라심한 책임자는 “추론과 계획을 개선하고 더 복잡한 시나리오를 만들기 위해서는 더 진보된 LLM이 필요하다”라는 결론을 내렸다.
현재 타우-벤치는 깃허브에서 무료로 사용할 수 있다.
박찬 기자 cpark@aitimes.com
