애플이 다양한 비전 인공지능(AI) 기능을 수행할 수 있는 모델용 학습 프레임워크를 오픈 소스로 공개했다. 이를 통해 모델 하나로 수십가지에 달하는 다양한 모달리티(modality) 작업을 처리할 수 있는데, 이는 애플의 온디바이스 AI 정책과 맞아 떨어진다는 분석이다.
벤처비트는 1일(현지시간) 애플이 스위스 연방 공과대학 로잔(EPFL)과 협력해 허깅페이스에 ‘4M(Massively Multimodal Masked Modeling)’의 데모를 공개했다고 소개했다.
4M은 이미지 하나로 다양한 비전 AI 작업을 처리하기 위한 멀티모달모델용 학습 프레임워크다. 지난해 12월 뉴립스(NeurIPS)에서 오픈 소스 논문 발표 후 7개월 만에 실제 데모를 공개한 것이다.
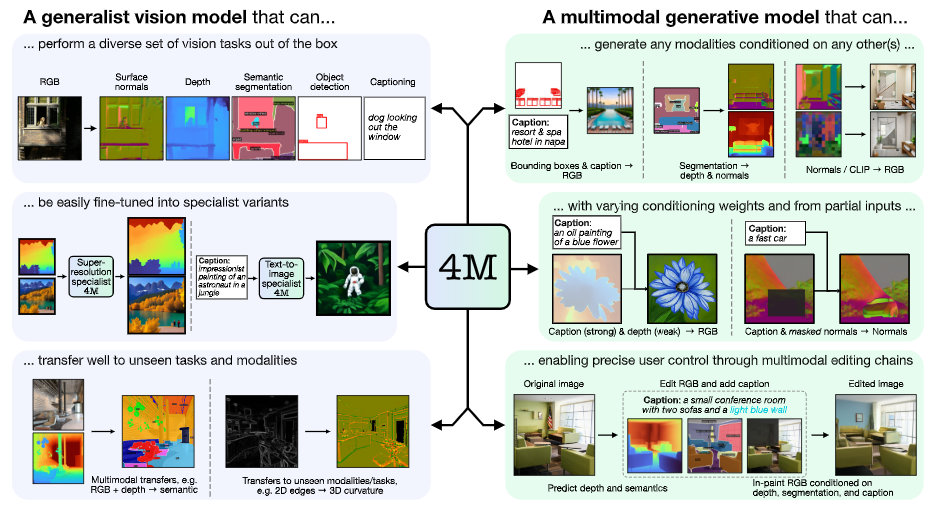
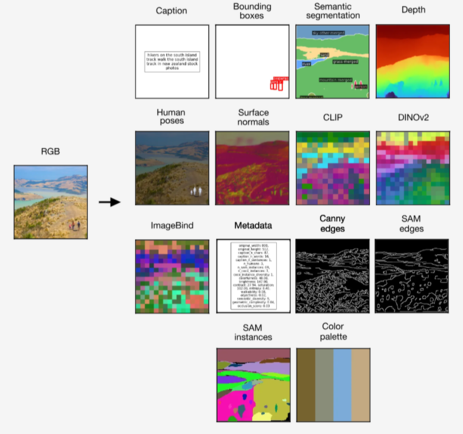
이를 통해 모델을 학습하면 이미지 분석을 통한 캡션 생성부터 바운딩 박스, 객체 분할, 메타데이터, 깊이, 이미지 바인드, 기하학적 및 의미적 모달리티와 신경망 피처 맵을 포함한 다양한 비전 작업을 가능케 해준다.
예를 들어, RGB 이미지에서 객체 분할, 깊이, 바운딩 박스, 캡션 등의 모달리티를 생성할 수 있고, 캡션에서 RGB 이미지, 객체 분할, 깊이, 바운딩 박스를 생성할 수 있다.
4M에서 각 모달리티를 개별적으로 토큰화한 다음, 토큰 시퀀스로 묶으면 다양한 모달리티 세트에서 단일 트랜스포머 인코더-디코더를 훈련할 수 있다. 4M은 하나의 임의의 토큰 하위 집합을 다른 집합으로 매핑해 훈련한다.
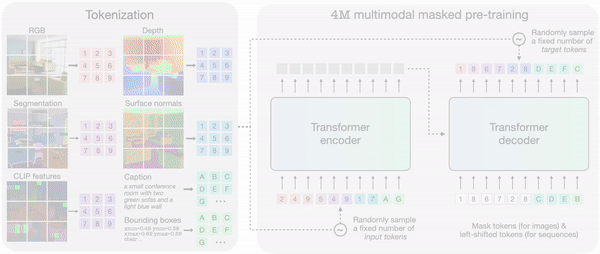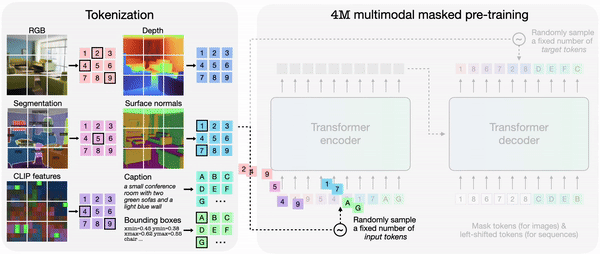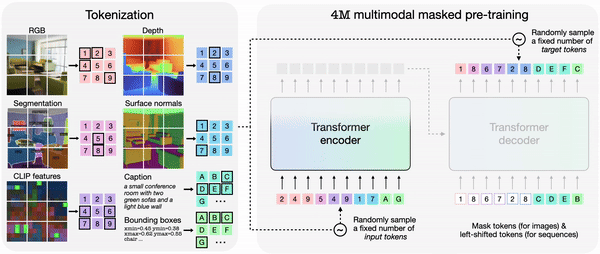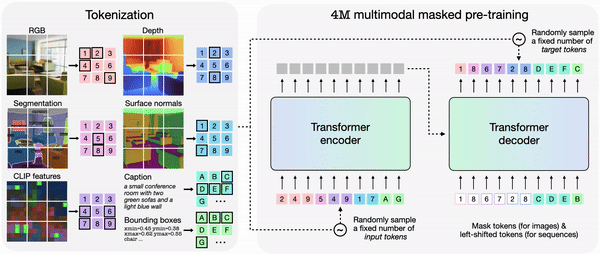
훈련된 4M 모델은 다른 모달리티의 조합으로 임의의 모달리티를 생성할 수 있으며, 부분 입력만으로도 예측을 수행할 수 있다. 개별적으로 예측하는 대신, 4M은 새로 생성된 모달리티를 입력으로 다시 연결, 다음 모달리티 생성할 수 있다. 그 결과 모든 훈련 모달리티를 일관된 방식으로 예측할 수 있다는 설명이다.
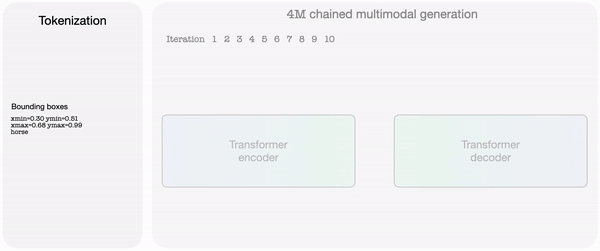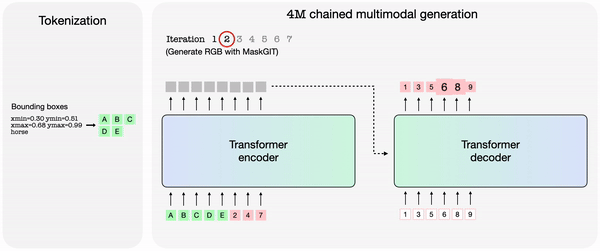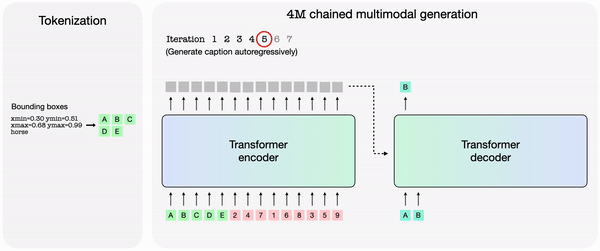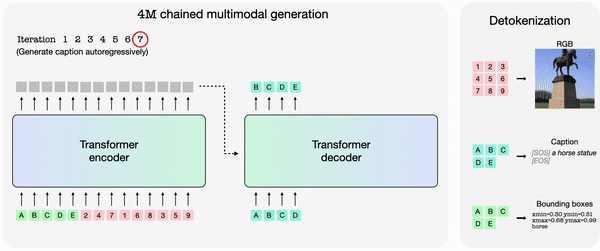
애플은 4M에서 훈련된 '4M-7 198M' '4M-21 705M' '4M-84 2.8B' 등 모델도 출시했다. 4M 프레임워크와 관련 모델들은 아파치 2.0 라이선스에 따라 오픈 소스로 공개됐다.
이 프레임 워크의 가장 큰 장점은 다양한 비전 작업에서 뛰어난 성능을 보이는 것뿐만 아니라, 기존 프로그램에 폭넓게 응용이 가능하다는 점이다.
즉, '시리(Siri)'가 텍스트와 이미지, 공간 정보 등을 포함하는 복잡한 다중 파트 쿼리를 이해하고 응답하게 만들 수 있다.
또 맥용 영상 편집 도구 '파이널 프로컷'에서 자연어 프롬프트로 비디오 콘텐츠를 생성하고 편집하게 만들 수 있으며, 혼합현실(MR) 헤드셋 '비전 프로'에도 유용할 것으로 봤다.
벤처비트는 "애플 인텔리전스는 아이폰과 맥같은 장치에서 개인화된 온디바이스 AI 경험에 초점을 맞춘 반면, 4M은 회사의 장기적인 AI 야망을 암시한다"라며 "자연어 입력을 통해 3D 장면을 조작하는 모델의 기능은 비전 프로와 애플의 증강현실(AR) 노력에 흥미로운 의미를 가질 수 있다"라고 평했다.
박찬 기자 cpark@aitimes.com
- 비전 모델 능력 평가하는 '멀티모달 아레나' 출시..."GPT-4o가 1위"
- 메타, 첨단 멀티모달 모델 ‘카멜레온’ 출시..."이미지 생성은 일단 보류"
- 레카, 새로운 LMM 강자 '코어' 출시..."일부 성능서 GPT-4 등 능가"
- 구글 딥마인드, 13배 빠르고 10배 저렴한 AI 훈련 방법 ‘제스트’ 공개
- 애플, '시리' 전면 업데이트는 내년 봄에...카메라 달린 'AI 에어팟' 2026년 출시 예정
- 메타, 온디바이스 AI 언어모델 ‘모바일LLM’ 공개
- 애플, 2D 이미지로 3D 깊이 파악하는 기술 개발.."커머스·자율주행에 유용"
