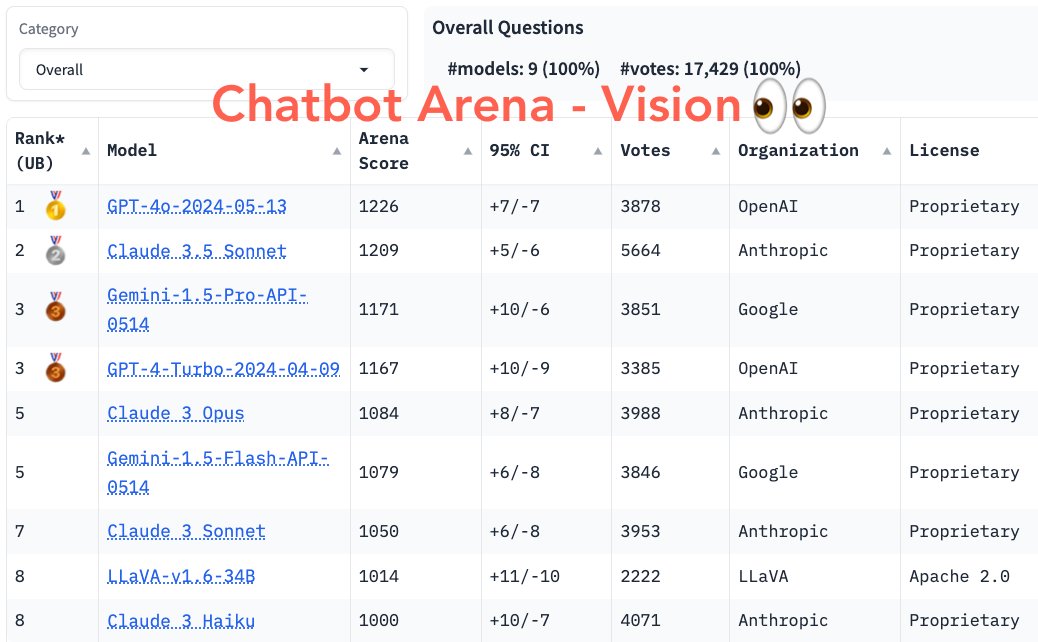
인간 선호도 평가인 '챗봇 아레나'로 유명한 LMSYS가 인공지능(AI) 모델의 이미지 이해 능력을 평가하는 '멀티모달 아레나'를 공개했다. 여기에서도 오픈AI의 'GPT-4o'가 1위를 차지했다.
LMSYS는 28일(현지시간) X(트위터)를 통해 챗봇 아레나의 비전 모델용 리더보드를 출시했다고 발표했다.
이에 따르면 지난 2주 동안 다양한 사용 사례에 대해 1만7000표 이상의 사용자 투표를 진행한 결과, 현재 선두에 오른 것은 GPT-4o다.
그 뒤를 앤트로픽의 '클로드 3.5 소네트'가 추격하고 있으며, 구글의 LMM '제미나이 1.5 프로'는 3위에 머물렀다.
오픈 소스 모델 중에서는 마이크로소프트의 MSRA 연구소가 내놓은 'LLaVA-v1.6-34B'와 앤트로픽의 '클로드 3 하이쿠'가 비슷한 점수로 공동 8위를 지키고 있다.
LMSYS는 캘리포니아대학교 버클리, UC 샌디에이고, 카네기 멜론 대학교 등이 운영하는 조직으로, 1년 전 등장한 챗봇 아레나는 기존 벤치마크와는 달리 사용자가 블라인드 방식으로 2개의 챗봇에 질문을 던지고, 마음에 드는 결과에 투표하는 방식이다.
지난해 말부터 벤치마크 효용성 문제가 지속적으로 제기되며, 챗봇 아레나는 새로운 대안으로 주목받으며 큰 인기를 얻고 있다.
이에 따라 LMSYS는 벤치마크 대상을 기존 언어 능력에서 이미지로 확장한 것이다. 멀티모달 아레나에서는 사용자들이 이미지 설명이나 수학 문제 풀이, 문서 이해, 밈 설명, 스토리 작성 등 다양한 사례를 임의의 두 모델에 요구하고, 결과를 비교해 투표한다.
GPT-4o는 챗봇 아레나 1위에 이어 2관왕에 올랐다. 클로드 3.5 소네트는 하위 섹션인 '코딩'과 '하드 프롬프트'에서는 1위에 올랐지만, 여전히 챗봇과 멀티모달 등 주요 2분야에서는 2위에 그쳤다.
물론 LMM의 이미지 이해 능력은 아직 인간에 비해 크게 떨어지는 것으로 알려지고 있다.
벤처비트는 최근 프린스턴대학교 연구진이 도입한 벤치마크(CharXiv) 결과를 인용, GPT-4o의 정확도가 47.1%에 불과하다고 지적했다. 이런 점수는 인간의 정확도인 80.5%에 크게 뒤떨어지는 수치다.
한편, LLM 성능을 평가하는 벤치마크가 점차 다양화되고 있다. 대표적인 허깅페이스의 LLM 리더보드도 하루 전날인 27일 대폭 업그레이드됐다.
그만큼 벤치마크에 대한 관심과 중요성이 커졌다는 분석이다. 이는 LLM의 성능을 객관적으로 비교, 관련 분야의 연구를 촉진하고 모델을 채택하려는 기업에는 중요한 참고가 되기 때문이다.
LMSYS에도 사용자들의 다양한 요청이 몰리고 있다. 특정 외국어나 이미지 및 비디오 생성 능력을 비교하는 리더보드도 신설해 달라는 글이 눈길을 끌고 있다.
임대준 기자 ydj@aitimes.com
