
그야말로 인공지능(AI)가 사회를 뒤덮은 모습이다. 어딜 가도 AI 그 자체로, 혹은 응용돼 존재하고 있는 모습이다. 특히 영상과 영화계 산업에서는 빠질 수 없는 요소로 자리잡아 가고 있다.
영상 사전제작(pre-production)에서 대본 작성과 촬영장소 발굴, 영상 후반작업(post-production)의 오브젝트 삭제(object removal)와 씬 안정화(scene stabilization)까지, AI와 머신러닝은 미디어 산업에 스며들고 있다. 누군가는 우려를 표하지만, 결과적으로는 긍정적이기도 하다. 지루하고 반복적인 작업에 시간을 적게 소요하는 것은 물론, 자본을 아끼면서 더 가치있는 작업에 비중을 둘 수 있기 때문이다.
■ 영상이해란
특히 미디어산업계에 가장 강력한 영향을 미치고 있는 기술은 '영상이해'라고 할 수 있다. 그렇다면 영상이해란 무엇일까. 영상이해 모델은 영상 콘텐츠의 분석, 해석, 이해를 통해 영상 전체 문맥을 이해할 수 있도록 정보를 추출하는 기술이다.
프레임 단위의 물건 혹은 객체 인식, 오디오 정보 분석을 넘어 AI로 '자연어와 동작(action)'을 결합하는 단계까지 나아간 것이다. 이를 위해서는 동작인식(activity recognition)과 객체탐지(object detection) 등 영상이해 작업을 수행해 동적인 '영상 매체'의 뉘앙스를 파악할 수 있어야 한다. 결과적으로는 시각적, 청각적, 그리고 대화적인 정보를 모두 처리하고 이해할 수 있다.
영상이해 AI모델은 '챗GPT' 등 대형언어모델(LLM)과는 확실히 다르다. LLM의 경우 영상 데이터를 이해하기 위한 별도 학습 과정을 거치지 않았기 때문이다. 쉽게 말해 AI 영상이해 모델은 마치 사람처럼 영상을 이해한다.
보다 완벽한 영상이해를 위해 트웰브랩스를 포함한 여러 조직, 연구원들이 탐구를 지속해 나가고 있다.
■ 미디어 산업에서 영상이해는 어떻게 응용할까
그렇다면 응용 가능한 영역은 어디까지일까. 미디어 전문가들과 영상 콘텐츠 크리에이터들이 어떻게 영상이해를 활용하는지 확인해 볼 필요가 있다.
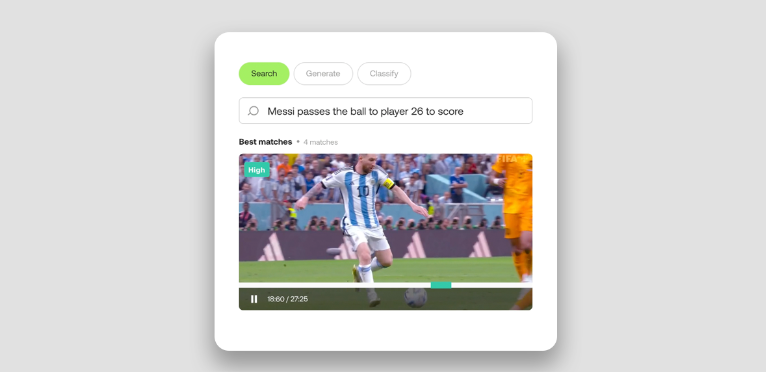
1) 영상 검색
만일 몇페타바이트(PB)가 넘는 거대한 데이터 콜렉션 속에서 하나의 특정 영상을 찾는다고 하면 고역일 수밖에 없다. 이때 구글 검색처럼 단순히 영상의 시각적 요소를 '글'로 표현해 찾을 수 있다면 어떨까.
특정 선수의 골 장면을 합쳐 하이라이트 영상을 만드는 경우가 있다. 이때 개인화 AI영상이해 모델에 검색을 진행, 몇초 만에 결과물을 받을 수 있는 식이다.
반면 전통적 영상 검색의 경우, 접근 방식이나 실행 방면에서 큰 제한이 있다. 태그나 키워드 매칭에 의존해 영상을 인덱싱하고 검색하면 시각과 청각 정보들로 영상을 깊이 있게 이해할 수 없기 때문이다. 한마디로 멀티모달 AI 기술을 활용할 수 없다.
하지만 현대적 영상이해 모델은 이미지, 소리, 대화, 화면에 나오는 텍스트 등 영상에서 제공하는 모든 데이터 종류를 동시에 통합할 수 있다. 데이터 정보 간의 복잡한 상관관계를 포착하는 것이다. 그렇게 미묘한 수준까지 잡아내며 사람과 같은 수준의 영상 해석을 가능케 한다.
이때 클라우드 객체 스토리지에서 영상검색을 진행해 훨씬 빠르게, 그리고 몇배 더 정확하게 이뤄질 수 있도록 한다. 영상 편집가들은 수동적 태깅이 아닌, 자연어를 활용해 대형 미디어 아카이브 속에서 특정 순간이나 숨겨진 영상을 빠르고 정확하게 발굴할 수 있다.
트웰브랩스의 영상검색API(서치API)는 1시간 정도 분량의 영상을 15분 안에 인덱싱, 해당 비디오를 100개국어가 넘는 언어로 '의미 검색'이 가능하게 해 준다.
2) 영상 분류
AI 기반 영상이해로 영상의 종류나 주제에 따른 자동 분류도 가능하다. 트웰브랩스의 분류API (Classify API)를 이용하면 영상 콘텐츠의 의미론적 특징, 개체, 액션 등 요소를 분석해 스포츠, 뉴스, 예능, 다큐 등으로 분류 및 정리할 수 있다.
특정 장면까지도 분류할 수 있다. 광고나 콘텐츠 조정 등 실용적인 사례에 활용할 수 있다. 예를 들어 무기가 등장하는 장면의 경우 교육적인지, 극적인지, 혹은 폭력적인지를 문맥 및 컨텍스트에 따라 이해하고 분류를 진행하는 방식이다.
결과적으로는 크리에이터나 영상 플랫폼은 물론 사용자에게도 편리함을 제공한다. 관심사나 선호에 맞게 더 정확한 추천이 가능하기 때문이다. 빠르게 영상 아이템을 찾아 영상편집 혹은 아카이빙 등 목적으로 로그해야 하는 영상후반작업(post-production) 전문가들에게도 많은 도움이 될 수 있다.
트웰브랩스 기술에서 사용하는 모든 영상은 보통의 메타데이터를 포함하고 있지만, 유저들에게는 맞춤형 메타데이터를 추가해 보다 세부적이고 컨텍스트에 특화한 정보를 제공할 수도 있다.
영상 관제(CCTV) 및 보안과 스포츠 분석부터 콘텐츠 조정과 맞춤광고까지, 영상이해는 기존의 영상분류를 완전히 뒤집을 수 있는 능력을 가지고 있는 것이다.
(영상=트웰브랩스)
3) 영상요약
몇초 만에 생성되는 세부적인 설명과 묘사로 영상 데이터셋을 요약할 수도 있다. 긴 영상 속 중요한 콘텐츠를 정확한 표현으로 압축해 시청자의 이해력과 참여도를 높인다.
특히 신체적 장애나 인지 장애 등으로 인해 비디오가 적합한 매체가 아닌 경우, 보충 설명 역할로 더 큰 도움이 될 수 있다.
미디어와 엔터테인먼트 산업에서는 영화, 방송 프로그램, 드라마 등 비디오 콘텐츠의 프리뷰나 트레일러를 제작할 때 이용할 수 있다. 전반적인 영상 콘텐츠를 정확하게 요약하는 동시에, 시청 여부 결정에도 도움을 준다.
트웰브랩스 '생성 API (Generate API)'도 주어진 영상을 기반으로 텍스트를 생성한다. 특히 맞춤형 3가지 엔드포인트를 제공한다. 각 엔드포인트는 특정 수준의 유연성과 커스터마이제이션을 제공하도록 설계했다.
먼저 '요점 API(Gist API)'는 제목, 주제, 걸맞는 해시태그 목록 등 정확한 텍스트 아웃풋을 생성할 수 있다.
'요약 API(Summary API)'는 영상 요약, 챕터, 그리고 하이라이트를 생성하도록 설계했다.
'생성 API(Generate API)'는 유저가 특정 형식이나 문체 혹은 스타일로 프롬프팅을 할 수 있도록 지원한다. 영상 내용을 바탕으로 글머리기호로 요약한다든지, 리포트를 작성한다든지, 심지어는 창의적인 노래 가사도 생성할 수 있다.
■ 영상이해의 기반이 되는 기술
이재성 트웰브랩스 대표는 “AI는 세상의 존재하는 데이터의 80%밖에 이해하지 못하고 있다"라며 "이는 나머지 데이터가 영상 콘텐츠로 잠겨 있기 때문"이라고 말했다. 이어 “우리는 그 자물쇠를 푸는 열쇠를 만들고 있다"라고 MASV와의 인터뷰에서 언급한 바 있다.
실제 기존 컴퓨터 비전(CV) 모델은 디지털 이미지를 이해하기 위해 뉴럴 네트워크와 머신러닝을 사용하는데, 이 때문인지 항상 영상 속 컨텍스트(문맥)을 이해하는 데 어려움을 겪어 왔다. 물론 V모델은 객체, 사물, 행동을 잘 식별하는 편이다.
하지만 사물과 행동간의 관계를 식별하는 데 특화하지는 않았다. 이 때문에 최근까지 AI를 활용해 영상을 분석하는 능력이 제한돼 있었다.
트웰브랩스의 파운딩 솔루션 아키텍트인 '트래비스 쿠튀르(travis Couture)'는 이 문제를 '콘텐츠 vs 컨텍스트', 즉 내용 대 문맥으로 요약한다.
그동안 영상이해 분야에서는 비디오 콘텐츠를 더 해결하기 쉬운 형태로 '쪼개는 접근방식을 취해왔다. 보통 프레임별로 개별 이미지로 취급해서 분석, 오디오 채널들을 따로 분리해 전사(transcription)한 것이다. 그렇게 두 과정이 모두 끝나면 모든 결과를 합쳐서 결론을 도출하는 방식이었다.
하지만 해체와 재조립을 거치고 나면 콘텐츠(내용)는 들어있을지 몰라도, 컨텍스트는 잃게 된다. 이는 영상 매체에 치명적인 문제다.
트웰브랩스는 이에 컴퓨터비전 접근방식에서 벗어나 '진정한 영상이해'를 목표로 데이터를 한번에 이해하고 처리하고자 한다.

■ 멀티모달 영상 이해
영상은 역동적이고, 여러 겹으로 이뤄져 있으며, 유동적이다. 그 집합적 요소들이 해체돼서 각자 따로 분석되면, 전체를 이루지 못한다. 트웰브랩스는 이 문제를 해결하기 위해 멀티모달 AI를 활용했다.
여기서 ‘모달리티'는 어떤 사건이 경험되는 방식을 의미한다. 영상은 현실세계와 비슷하게 여러가지 모달리티를 갖고 있다. 청각적, 시각적, 시간적, 언어적 정보 등과 같이 말이다.
이소영 트웰브랩스 공동창립자(사업개발자)는 "이러한 모달리티를 개별적으로 분석해서 다시 하나로 조합하려고 하면, 결코 완전하게 전체적인 이해와 맥락을 얻어낼 수 없다"라고 설명했다.
트웰브랩스는 멀티모달 접근 방식으로 사람이 영상을 해석하는 방식을 재현, 마렝고 비디오 초거대모델을 개발했다. 지각적, 의미적, 맥락적 정보를 생성 모델인 페가수스에 제공해 인간이 지각에서 처리와 논리로 나아가는 방식을 모방한다는 설명이다.
사람의 뇌가 끊임없이 방대한 양의 정보를 받고, 해석하고, 정리하는 것처럼 트웰브랩스의 멀티모달 AI도 여러 자극들을 통합해 일관적인 이해를 도출하는 데 중점을 둔다. 시간, 객체, 음성, 텍스트, 사람, 행동과 같은 변수들을 중심으로 영상에서 데이터를 추출해 벡터 또는 수학적 표현으로 통합한다. 행동 인식 또는 행동 감지, 패턴 인식, 객체 감지, 장면 이해 등 여러 필수 작업을 거친다.
미디어 산업 응용 가능성은 무궁무진하기 때문에, 사용자가 비디오 이해 기술을 탐구하고 테스트할 수 있도록 샌드박스 환경인 '플레이그라운드'도 제공한다. 견고한 문서와 API를 제공해 사용자가 몇 번의 API 호출만으로 비디오 이해 기능을 플랫폼에 내장할 수 있도록 지원한다.
■ 마치며
영상이해 AI는 다양한 산업군에 적용 가능하지만, 오늘은 특별히 미디어산업에서 어떻게 이롭게 작용할 수 있는지 알아 봤다. 추후 계속해서 이 분야가 발전해나가며 잠들어있는 많은 영상 자산들이 다시 빛을 보는 순간들이 오길 바란다.
영상이해를 경험해보고 싶거나 더 많은 정보를 알고 싶다면, 트웰브랩스 플레이그라운드에 가입해 10시간의 무료 크레딧으로 직접 사용해보는 걸 추천한다.
김서영 트웰브랩스 PMM(Product Marketing Manager)
