
초거대 모델은 자연어 처리(NLP) 및 컴퓨터 비전 분야에서 인기를 끌고 있다. 하지만 대부분 일반 대중은 비디오 이해 분야에서 초거대모델이 지닌 잠재력을 완전히 이해하기 어려운 실정이다.
다량의 비디오 데이터를 효율적으로 처리하고 분석하는 것이 어렵고, 비디오 이해를 향상하기 위해 다양한 모달리티를 효과적으로 결합하는 것도 복잡한 과정이기 때문이다. 하지만 엔터테인먼트, 교육 및 감시 등 분야에서 개발자들의 다양한 요구와 사용 사례들이 생겨나며 '실제 제품에 대한 비디오 이해의 적용'이 화두로 떠오르고 있다.
비디오 이해를 발전시킬 만한 유망한 연구분야 중 하나는 바로 '하이브리드 모델 개발'이다. 오디오, 텍스트, 시각 등 다양한 모달리티의 강점을 결합하는 모델로, 비지도 학습 및 자기도 자기지도 학습과 같은 기술을 활용해 다양한 모달리티에서 특징을 추출하고 비디오 콘텐츠를 보다 종합적으로 이해한다.
이에 최근 출시한 멀티모달 비디오 초거대모델을 간단히 살펴보도록 하겠다.
3.1 - 비디오CoCa(VideoCoCa)
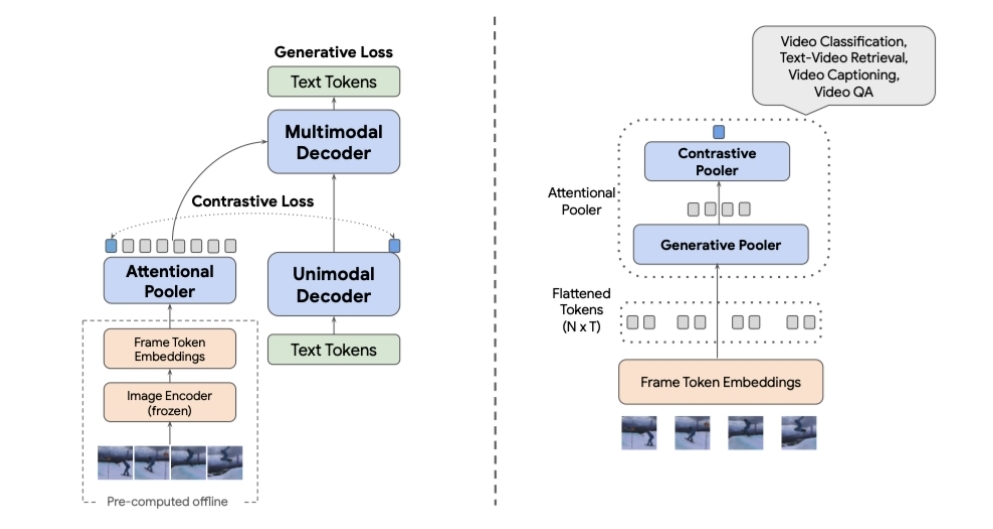
비디오CoCa는 미세조정(finetuning)에 의존하지 않고 기존에 존재하는 CoCa(contrastive captioners)를 활용하는 비디오-텍스트 모델링 방법이다. 모델은 문장 후보를 생성하기 위해 CoCa 모델을 사용한다. 비디오와의 관련성에 따라 점수를 매기도록 학습된 '트랜스포머 기반 모델'로 후보 문장들에 점수를 매기는 방식이다.
비디오CoCa를 다양한 데이터셋에서 테스트한 결과, 제로샷 비디오 분류(zero-shot video classification), 제로샷 비디오 텍스트 검색(zero-shot video-text retrieval), 영상 캡셔닝, 그리고 (미세조정된 뒤의) 영상 질의응답과 같은 작업에서 최신 기술 및 방법에 버금가는 성능을 달성한 바 있다.
아울러 어블레이션 연구(ablation studies)를 통해 CoCa는 비디오CoCa의 필수 구성 요소라는 것이 증명됐다.
3.2 - MERLOT-리저브

MERLOT 리저브는 비디오 프레임, 텍스트 및 오디오에서 공동 추론(joint reasoning)을 진행하며 비디오의 멀티모달 신경 스크립트 지식 표현(multimodal neural script knowledge representations)을 학습하는 모델이다. 특히 시간과 (오디오, 자막, 비디오 프레임을 포함한) 모달리티에 걸쳐 비디오를 표현하도록 설계됐다.
텍스트와 오디오 자기지도학습을 통해 새로운 'contrastive masked span learning objective'를 사용, 2000만개 이상의 유튜브 비디오를 통해 훈련을 거쳤다. 결과적으로 비디오 내 다양한 요소 간의 의미적 및 시간적 관계를 포착, 영상이해 태스크에 사용할 수 있는 풍부한 비디오 콘텐츠 표현을 학습할 수 있다.
논문 저자들은 다수 기준을 통해 MERLOT 리저브를 평가, 최신 기술(visual commonsense reasoning, situated reasoning, action anticipation과 비디오 QA와 같은)을 능가한다는 사실을 입증했다. 크로스-도메인 데이터셋(cross-domain datasets)에서도 뛰어난 성능을 달성한다는 것을 증명했다.
또 어블레이션 연구를 수행하며 '스크립트 지식 기반의 사전학습'이 MERLOT 리저브에 결정적인 역할을 한다는 것도 발견했다. 이후 학습을 거친 MERLOT 리저브의 표현들을 더 깊게 분석해 비디오 컨텐츠의 유의미한 의미적 구조 및 구문적인 구조를 포착할 수 있다는 것을 보여준 바 있다.
3.3 - Vid2Seq

Vid2Seq는 나레이션(설명)을 입힌 비디오로 사전 학습된 단일 단계 밀도(single-stage dense) 영상 캡셔닝 (영상 캡션 생성) 모델이다. 어느 정도 길이의 '편집되지 않은 영상'에서 프레임 및 전사된 음성을 인풋으로 받아들인다. 이후 단일 토큰 시퀀스를 예측하며 밀집된(dense) 이벤트 캡션을 각자 영상 내 지정된 시간적 위치와 함께 출력한다.
Vid2Seq의 아키텍처는 T5 언어모델(T5 language model)을 특수한 시간 토큰으로 보완, 동일한 아웃풋 시퀀스 내에서 이벤트 경계(event boundaries)와 텍스트 설명을 막힘없이 예측할 수 있게 한다.
특히 Vid2Seq는 대규모로 사용가능한 HowTo100M에 있는, 라벨링되지 않은 내레이션 비디오를 활용해 사전 훈련을 학습을 거쳤다. 특히 다양한 도메인을 다루는 1800만 개의 나레이션 비디오를 포함하는 YT-Temporal-1B 데이터 세트를 사용한다. 이런 비디오를 기반으로 연구자들은 전사된 음성의 문장 경계를 유사 이벤트 경계(pseudo-event boundaries)로 재구성, 전사된 음성의 문장들을 유사 이벤트 캡션(pseudo-event captions)으로 사용했다.
Vid2Seq는 ActivityNet-Captions, YouCook2 및 Video Timeline Tags를 포함한 standard dense event captioning benchmarks에서 최첨단 성능을 달성한다. 퓨샷 밀집된 영상캡셔닝 세팅, 영상 문단 캡션 생성 태스크와 스탠다드 영상 캡션 생성 태스크에 대한 일반화 능력도 좋다는 설명이다.
■ 결론
최첨단 신경망 아키텍처의 개발 덕분에 비디오 이해 기술은 지난 10년간 큰 발전을 이뤘다. 과거에는 비디오 이해가 물체 인식, 세분화와 트래킹과 같은 로우- 레벨 인지 태스크(low-level perception task)에 제한됐었다. 하지만 현재 접근 방식을 이용하면 분류, 검색, 질문응답과 캡셔닝(캡션 생성) 등 하이레벨 이해 태스크(high-level understanding tasks)를 처리할 수 있어 더 많은 활용 가능성을 제공한다. 아울러 멀티모달 비디오 초거대모델이 점점 개발되는 지금, 영상이해 기술의 미래가 기대되는 부분이다.
트웰브랩스에서도 멀티모달 비디오 이해를 위한 초거대모델을 개발하며 영상이해기술 개발에 힘쓰고 있다. 다량의 영상 속에서 원하는 순간을 자연어로 검색해서 찾을 수 있게 하는 영상 검색 솔루션은 물론, 영상 내용을 바탕으로 질문을 던지면 인사이트를 도출하고 요약도 할 수 있는 비디오-투-텍스트 생성 솔루션을 제공하며 사람처럼 영상을 이해할 수 있는 모델을 개발하기 위해 노력 중이다. 해당 솔루션은 playground@twelvelabs.io에서 영상을 올려서 검색도 해보고, 요약도 해보며 직접 체험해볼 수 있다.
김서영 트웰브랩스 PMM(Product Marketing Manager)
