
프랑스 인공지능(AI) 스타트업 미스트랄 AI가 플래그십 대형언어모델(LLM) '라지(Large)'의 신규 버전을 공개했다. 미스트랄은 새로운 AI 모델이 하루 전에 출시한 메타의 라마 3.1 모델과 동등한 성능을 가지고 있다고 주장했다.
벤처비트는 24일(현지시간) 미스트랄이 대형언어모델(LLM) ‘라지 2’를 출시했다고 소개했다.
이에 따르면 라지 2 모델은 1230억개(123B)의 매개변수로, 12만8000 토큰의 컨텍스트 창을 제공한다. 라마 3.1 중 가장 큰 모델(405B)에 비해 매개변수가 3분의 1도 안 되는 크기다.
이전 버전인 라지 모델을 기반으로 추론, 코드 생성 및 수학 전반에 걸쳐 성능 개선과 함께 고급 다국어 기능을 제공한다. 한국어를 포함해 영어, 프랑스어, 독일어, 스페인어, 이탈리아어, 포르투갈어, 아랍어, 힌디어, 러시아어, 중국어, 일본어 등 12개 언어와 80개의 코딩 언어를 지원한다.
또 고급 함수 호출 및 검색 등 새로운 기능을 제공한다.
미스트랄은 라지 2 모델이 합성 텍스트 생성, 코드 생성, 검색 증강 생성(RAG)와 같이 높은 추론 능력이 필요하거나 매우 특수화된 작업에 효과적이라고 설명했다.
다만, 이미지를 이해하거나 입력할 수 있는 멀티모달 기능은 빠졌다. 전날 출시된 '라마 3.1'도 멀티모달 모델이 아니다. 이 부분은 오픈 소스 진영의 과제로 남아있다.
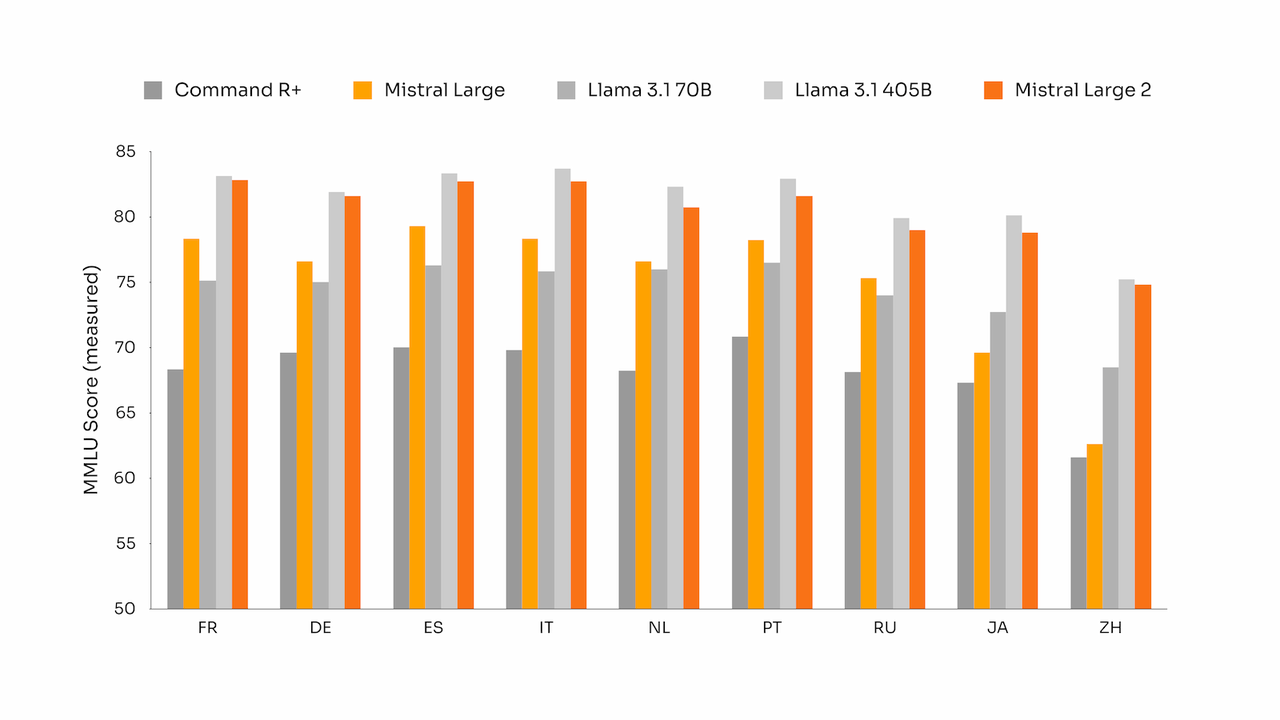
특히 성능은 크기가 3배가 넘는 라마 3.1의 근접, 훨씬 더 큰 비용 이점을 제공한다고 강조했다.
라지 2는 추론 능력 측정 벤치마크인 MMLU에서 라마 3.1-405B와 동등한 성능을 보였다.
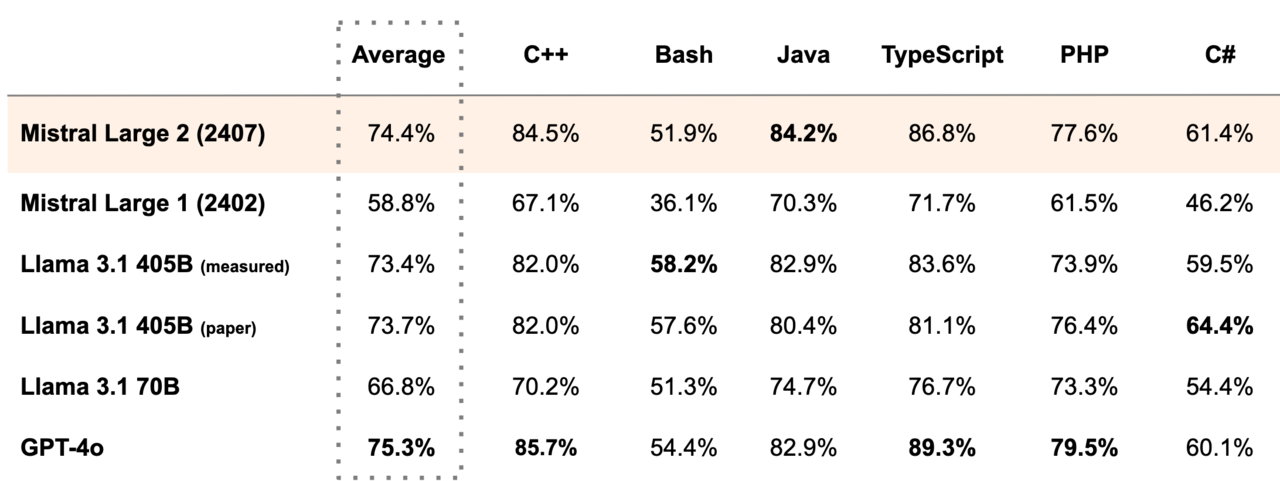
코드 생성을 위한 휴먼 이밸(HumanEval) 및 휴먼 이밸 플러스 벤치마크에서 라지 2는 'GPT-4o'에 이어 2위를 차지, '클로드 3.5 소네트'와 '클로드 3 오퍼스' '라마 3.1-405B' 등의 성능을 능가했다.
코드 생성 정확도를 평가하는 멀티플-E(MultiPL-E) 벤치마크와 수학 중심 벤치마크인 GSM8K 및 매스 인스트럭트(Math Instruct)에서도 GPT-4o에 이어 2위를 차지했다. 함수 호출 벤치마크에서는 GPT-4o, 클로드 3.5 소네트, 클로드 3 오퍼스를 제치고 1위를 차지했다.

현재 미스트랄 라지 2는 구글 버텍스 AI, 아마존 베드록, 애저 AI 스튜디오, IBM 왓슨xi에서 사용할 수 있다. 미스트랄의 르 플래트폼(le Plateforme)에서 ‘미스트랄-라지-2407’이라는 이름으로 새 모델을 사용할 수도 있고, 미스트랄의 AI 챗봇인 '르샤(le Chat)'에서 무료로 테스트해 볼 수도 있다.
다만, 라지 2는 비상업적 연구 용도로만 공개됐다. 상업 및 기업용 애플리케이션에 사용하려는 경우 별도의 라이선스 및 사용 계약이 필요하다. 즉, 오픈 소스라고 볼 수는 없다.
이처럼 최근 지난 18일 오픈AI의 'GPT-4o 미니'를 시작으로 일주일 새 주요 모델 3개가 공개됐다.
이에 대해 테크크런치는 "비가 오면 하늘에서 프런티어 모델이 같이 쏟아져 내린다"라고 비유했다.
박찬 기자 cpark@aitimes.com
