
구글이 26억 매개변수의 온디바이스 인공지능(AI) 모델을 오픈 소스로 공개했다. 구글은 이 모델이 오픈AI의 'GPT-3.5', 미스트랄의 '믹스트랄 8x7B' 등 큰 모델 성능을 능가했다고 주장했다.
벤처비트는 31일(현지시간) 구글이 26억 매개변수의 초소형 오픈 소스 모델 ‘젬마 2 2B’를 출시했다고 보도했다.
이에 따르면 젬마 2 2B모델은 인간 선호도를 평가하는 LMSYS의 챗봇 아레나에서 1130점을 받아 매개변수가 10배 더 많은 'GPT-3.5-터보'의 1117점과 믹스트랄-8x7B의 1114점보다 약간 앞섰다.
또 추론 능력 측정 벤치마크인 MMLU에서 56.1점, 코딩 관련 벤치마크인 MBPP에서 36.6점을 기록해 이전 버전에 비해 상당한 개선을 보였다.
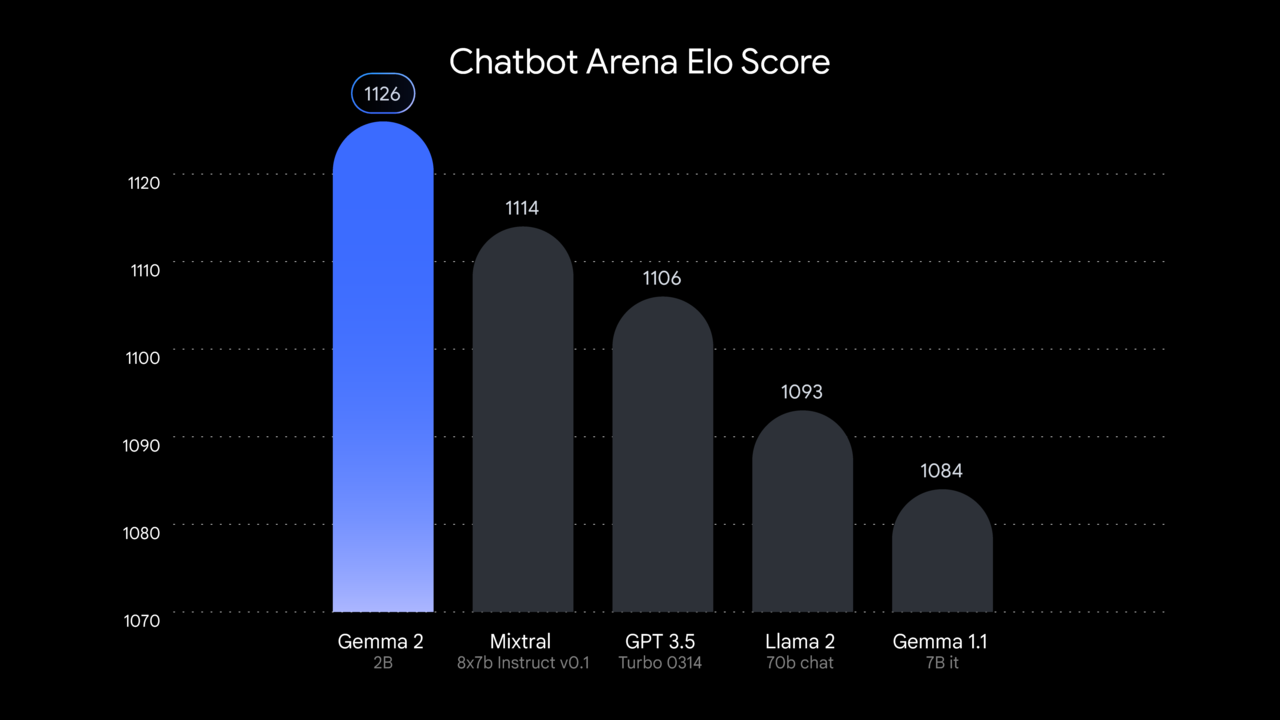
이는 정교한 훈련 기법과 효율적인 아키텍처, 고품질 데이터셋 등을 통해 매개변수 규모 차이를 보완할 수 있음을 보여주는 예로 꼽힌다.
특히 젬마 2 2B는 모델 압축 및 증류(distillation) 기술의 중요성을 강조한다. 증류는 더 큰 모델을 사용, 작은 모델을 훈련할 데이터셋을 구축하는 것이다.
큰 모델에서 작은 모델로 지식을 효과적으로 증류함으로써 성능을 희생하지 않고도 더 접근 가능한 AI 모델을 만들 수 있다는 논리다. 이 접근 방식은 컴퓨팅 요구 사항을 줄일 뿐만 아니라, 대형 AI 모델의 훈련 및 실행에 따른 환경 영향을 줄이는 문제도 해결한다.
또 젬마 2 2B는 구글의 TPU v5e 칩을 사용, 2조개 토큰 규모의 데이터셋으로 훈련된 다국어 모델이다.
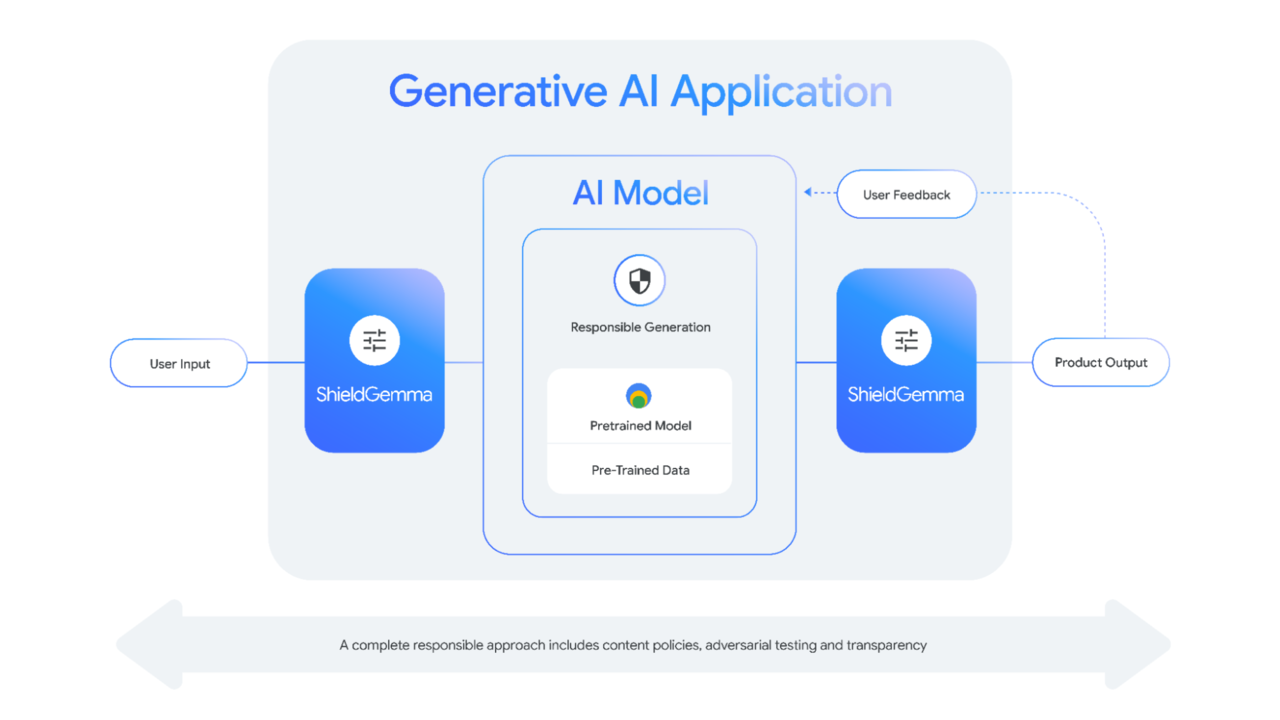
한편 구글은 이날 AI 모델 입력 및 출력에서 유해한 콘텐츠를 탐지하고 완화하도록 설계된 최첨단 안전 분류기인 '쉴드젬마(ShieldGemma)'도 공개했다.
쉴드젬마는 혐오 발언, 괴롭힘, 노골적인 성적 콘텐츠, 위험한 콘텐츠 등 4가지 영역에서 유해 콘텐트를 필터링하는 젬마 2 기반의 안전 콘텐츠 분류 모델 모음이다. 2B 모델은 온라인 분류 작업에 이상적이며, 9B 및 27B 버전은 지연 시간이 덜 중요한 오프라인 애플리케이션에 더 높은 성능을 제공한다.
이 외에도 젬마 2 모델의 내부를 탐색할 수 있도록 신경망의 개별 기능을 식별하고 추적할 수 있는 젬마 스코프(Gemma Scope)를 공개했다.
젬마 스코프는 희소 오토인코더(SAE)를 사용하여 모델에서 해석 가능한 특징을 추출, 내부 작동 방식을 탐색한다. 젬마 스코프를 통해 개발자들은 더 이해하기 쉽고 책임감 있고 신뢰할 수 있는 AI 시스템을 구축할 수 있다는 설명이다.
이와 관련, 구글은 지난 주 SAE를 사용해 모델 내부를 탐색할 수 있는 ‘점프렐루 SAE(JumpReLU SAE)’ 아키텍처를 발표한 바 있다.
박찬 기자 cpark@aitimes.com
- 구글, LLM 내부 해석 가능한 아키텍처 공개…오픈AI·앤트로픽 흡사한 '희소 오토인코더' 방식
- 구글, '버텍스 AI'에 기업용 서비스 대거 추가...제미나이 플래시2·젬마2·이매진3 등도 출시
- 구글, 온디바이스 AI용 오픈 소스 sLM ‘젬마’ 출시
- 아르시, LLM 지식을 온디바이스 모델로 전달하는 '증류' 도구 출시
- 엔비디아, '라마 3.1 8B' 절반으로 줄인 모델 출시..."4B 모델 중 최강 성능"
- 구글, 인기 VLM ‘팔리젬마 2' 업그레이드 버전 출시..."모델 세분화로 유연성 확대"
- 구글, 오픈 소스 온디바이스 모델 '젬마 3' 공개..."단일 GPU 구동 역대 최강 성능"
