인공지능(AI) 음성 비서 경쟁이 본격화됨에 따라, 중국 알리바바가 새로운 오디오언어모델을 선보였다. 음성인식모델 중 최고로 꼽히는 오픈AI의 오픈 소스 '위스퍼(Whisper)'에 자사의 언어모델인 '큐원2(Qwen2)'를 결합한 것이다.
마크테크포스트는 11일(현지시간) 알리바바 큐원팀이 뛰어난 정밀도와 다양한 상호작용으로 복잡한 오디오를 처리할 수 있는 '큐원2-오디오(Qwen2-Audio)'를 공개했다고 보도했다.
오픈AI의 'GPT-4o'나 구글의 '프로젝트 아스트라'에서 볼 수 있듯이 사람 음성을 이해하고 답할 수 있는 음성모델의 중요성이 강조되고 있다.
그러나 오디오 언어 모델은 '계층적 태그 시스템(hierarchical tagging systems)'이라는 복잡한 구분법에 다른 복잡한 사전훈련 과정을 거쳐야 했다. 또 다양한 음성을 동시 처리하거나 음악이나 주변환경 음 등이 섞인 상황에서는 성능이 저하됐다.
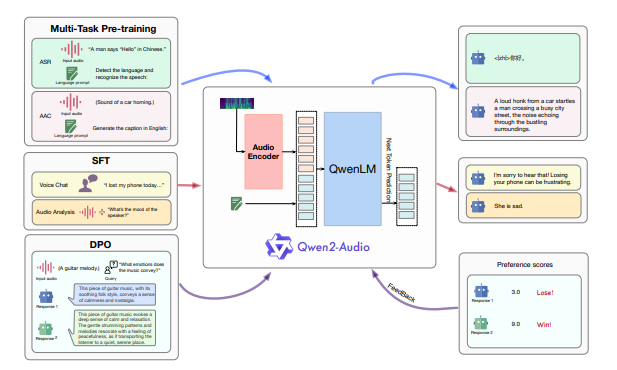
이 문제를 해결하기 위해 알리바바 연구진은 계층적 태그 대신, 자연어 프롬프트를 사용해 사전 학습 프로세스를 단순화하고 지시 기능을 향상했다고 밝혔다. 즉, '위스퍼-라지-v3' 모델에 향상된 오디오 인코더와 대형언어모델(LLM) '큐원 2 7B'를 통합한 것이다.
이에 따라 이 모델은 오디오 분석과 음성 채팅 두가지에서 모두 뛰어난 성능을 보였다는 설명이다.
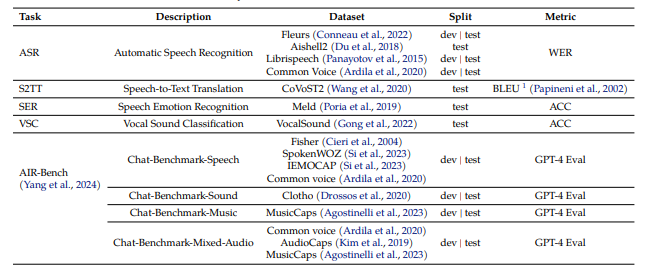
벤치마크에서 자동 음성 인식(ASR), 음성-텍스트 변환(S2TT), 음성 감정 인식(SER) 등에서 이전 모델을 능가했다.
특히 VSC(보컬 사운드 분류) 작업에서 큐원2-오디오는 93.92%의 정확도를 달성했으며, 오디오 중심 기능 테스트에서 '제미나이 1.5 프로'와 같은 이전 SOTA보다 성능이 뛰어나다고 밝혔다.
연구진은 "결론적으로 이 모델은 사전 훈련 프로세스를 단순화하고, 데이터 볼륨을 확장하고, 고급 아키텍처를 통합함으로써 이전 모델의 한계를 해결하고 오디오 상호작용 시스템에 대한 새로운 표준을 제시한다"라고 강조했다.
또 "작업별 미세 조정 없이도 다양한 작업에서 우수한 성능을 발휘할 수 있는 능력은 오디오 신호를 처리하고 상호작용하는 방식을 혁신할 수 있는 잠재력을 보인다"라고 덧붙였다.
이 모델은 오픈 소스로 공개됐다.
한편 알리바바는 지난 6월 오픈 소스 최강이라는 '큐원 2'를 출시했으며, 이어 지난 주에는 역시 최강성능이라는 수학 전용 소형언어모델(sLM) ‘큐원2-매스(Qwen2-Math)’를 공개한 바 있다.
임대준 기자 ydj@aitimes.com
