
데이터베이스와 대형언어모델(LLM)의 추론 기능을 결합, 의미적 추론이나 데이터 소스에서 직접 얻을 수 있는 것 이상의 지식을 요구하는 자연어 쿼리를 처리하도록 하는 새로운 접근 방식이 나왔다. LLM 한계를 넘기 위해 웹 데이터를 찾는 검색 증강 생성(RAG)에 이어, 데이터베이스를 직접 연결하는 이번 기술에는 '테이블 증강 생성(TAG)'이라는 이름이 붙었다.
벤처비트는 2일(현지시간) UC 버클리와 스탠포드대학교 연구진이 데이터베이스에서 자연어 질문에 답하기 위한 새로운 패러다임인 TAG(Table-Augmented Generation)에 관한 논문을 아카이브에 게재했다고 보도했다.
사용자가 자연어 질문을 하면, 텍스트-SQL이나 RAG이라는 두가지 접근 방식을 주로 사용한다. 그러나 두 방식 모두 의미적 추론이나 데이터 소스에서 직접 얻을 수 있는 것 이상의 지식을 요구하는 자연어 쿼리 처리에는 어려움을 겪는 것으로 나타났다.
텍스트 프롬프트를 데이터베이스에서 실행할 수 있는 SQL 쿼리로 변환하는 기존의 텍스트-SQL 방법들은 관계 연산으로 표현할 수 있는 자연어 질문만을 다루며, 이는 사용자 질문 중 일부에 불과하다. RAG 역시 소수 데이터 기록을 찾아 답변할 수 있는 질문만을 고려한다.
따라서 복잡한 쿼리에 대응하는 효과적인 시스템을 만들기 위해서는 단순 조회나 관계 연산을 넘어, 데이터베이스의 계산적 정밀성과 언어 모델의 추론 능력을 결합해야 한다는 설명이다.
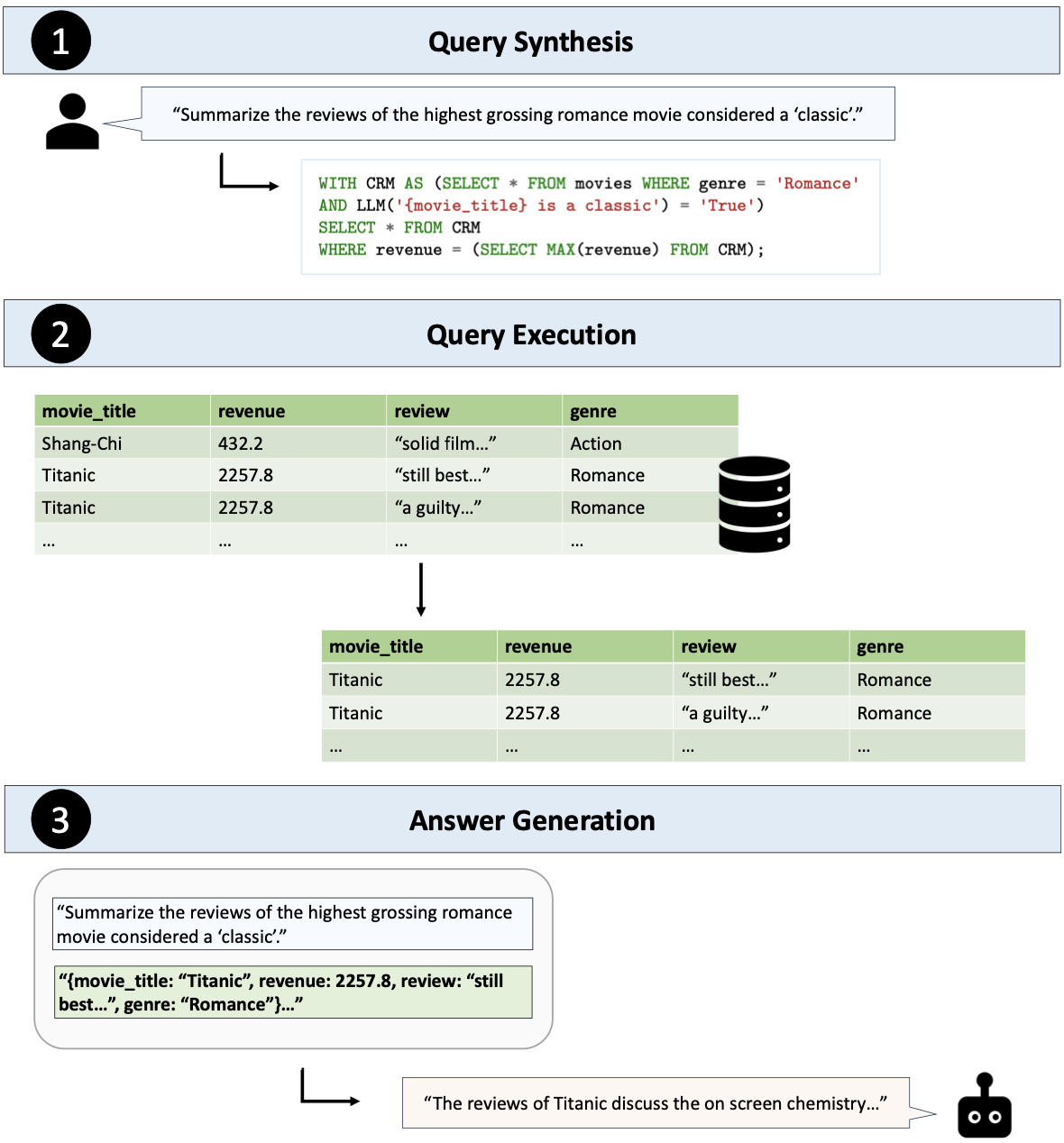
TAG는 ▲사용자 질문을 실행 가능한 데이터베이스 쿼리로 변환하는 '쿼리 합성(Query Synthesis)' 과정 ▲이 쿼리를 실행해 관련 데이터를 검색하는 '쿼리 실행(Query Execution)' 과정 ▲그리고 이 데이터와 쿼리를 사용해 자연어 답변을 생성하는 '답변 생성(Answer Generation)' 과정으로 구성된다. 이를 통해 특정 쿼리에 제한되는 텍스트-SQL이나 RAG와 달리, TAG는 더 넓은 범위의 쿼리를 처리할 수 있다.
이 접근 방식을 통해 언어 모델의 추론 능력이 쿼리 합성 및 답변 생성 단계 모두에 통합되며, 데이터베이스 시스템의 쿼리 실행은 집계, 수학 계산, 필터링 등 계산 작업을 처리하는 데 있어 RAG의 비효율성을 해결한다. 시스템은 의미적 추론, 세계 지식, 도메인 지식을 모두 요구하는 복잡한 질문에 답할 수 있게 된다.
예를 들어, "고전으로 여겨지는 최고 수익을 올린 로맨스 영화의 리뷰 요약"이라는 질문에 답할 수 있다.
이 질문은 전통적인 텍스트-SQL나 RAG 시스템에게는 어려운 과제다. 데이터베이스에서 최고 수익을 올린 로맨스 영화를 찾아야 할 뿐만 아니라, 세계 지식을 활용해 해당 영화가 '고전'인지도 판단해야 하기 때문이다.
하지만 TAG의 3단계 접근 방식을 통하면, 시스템은 관련 영화 데이터를 위한 쿼리를 생성하고, 필터와 언어 모델을 사용해 수익 순으로 정렬된 고전 로맨스 영화 테이블을 생성한 뒤 테이블에서 가장 높은 순위의 영화에 대한 리뷰를 요약해 원하는 답변을 제공한다.
TAG 효과를 테스트하기 위해 연구진은 언어모델의 텍스트-SQL 능력을 평가하는 BIRD 데이터셋을 활용하고, 데이터 소스에 있는 정보를 넘어서는 세계 지식에 대한 의미적 추론을 요구하는 질문들을 추가해 벤치마크를 강화했다.
수정된 벤치마크는 TAG 구현이 텍스트-SQL나 RAG 등 다른 방식과 비교해 어떤 성과를 내는지 평가하는 데 사용됐다.
그 결과, 모든 기준 모델이 20% 이상의 정확도를 달성하지 못한 반면, TAG는 40% 이상의 정확도로 훨씬 더 나은 성과를 보였다.
구체적으로 TAG 기준 모델은 전체적으로 55%의 쿼리에 정확하게 답변했으며, 비교 쿼리에서 65%의 정확도를 기록하며 가장 우수한 성과를 보였다. 이 기준 모델은 항목의 정확한 순서 지정이 어려운 랭킹 쿼리를 제외하고, 모든 쿼리 유형에서 50% 이상의 정확도를 꾸준히 유지했으며, 전반적으로 표준 기준 모델들에 비해 20%에서 65%까지 정확도 향상을 제공했다.
이 외에도 연구진은 TAG 구현이 다른 기준 모델들에 비해 쿼리 실행 속도가 3배 빠르다는 것을 발견했다.
결론적으로 이 접근법은 AI와 데이터베이스 기능을 통합해 구조화된 데이터 소스에서 복잡한 질문에 답할 수 있는 방법을 제공한다. 이를 통해 복잡한 코드를 작성하지 않고도 데이터셋에서 더 많은 가치를 추출할 수 있다는 설명이다.
연구진은 "LLM과 데이터베이스 간의 상호 작용 범위는 이전에는 거의 연구되지 않았다"라며 "이번 연구는 데이터에 대한 LLM의 세계 지식과 추론 능력을 활용하기 위한 흥미로운 기회가 됐으며, 후속 연구의 필요성을 강조한다"라고 밝혔다.
현재 수정된 TAG 벤치마크의 코드는 깃허브에 공개, 추가 실험을 할 수 있다.
박찬 기자 cpark@aitimes.com
