
업스테이지가 차세대 광학문자인식(OCR) 모델과 벤치마크를 선보였다.
인공지능(AI) 전문 업스테이지(대표 김성훈)는 이미지 등 다양한 문서를 정형화된 파일로 전환해 주는 OCR 모델의 업그레이드 버전 ‘도큐먼트 파스(Document Parse)’를 공개했다고 17일 밝혔다.
도큐먼트 파스는 기존 업스테이지 OCR 모델보다 복잡한 '레이아웃 인식’ 측면에서 뛰어난 성능을 보인다고 전했다.
즉, 명확한 인식이 어려웠던 여러 열의 레이아웃이나 테이블 등을 포함한 복잡한 형태의 문서에서도 구조와 텍스트 정보를 정확히 분석, 데이터 자산화를 가능케 한다는 설명이다. 어떤 형식의 문서도 HTML과 같은 구조화된 텍스트 형식으로 전환, 기업이나 기관에서서 LLM 활용에 바로 적용할 수 있다고 강조했다.
또 검색 증강 생성(RAG)을 도입하고 데이터 전처리 과정에서의 정확성을 제고, LLM의 응답 정확도를 높였다고 전했다.
빅테크 모델을 능가하는 정확도와 속도를 기록했다고 강조했다. 이는 업스테이지가 구축한 문서 구조 분석 벤치마크 ‘DP-벤치’로 테스트한 결과다.
업스테이지 관계자는 “기존에도 OCR 벤치마크는 존재했지만, 업계에서 통용할 만큼 객관적이고 영향력 있는 벤치마크는 드물었다"라며 “널리 사용할 수 있는 객관적 기준 마련을 위해 벤치마크를 따로 제작했다”라고 설명했다.
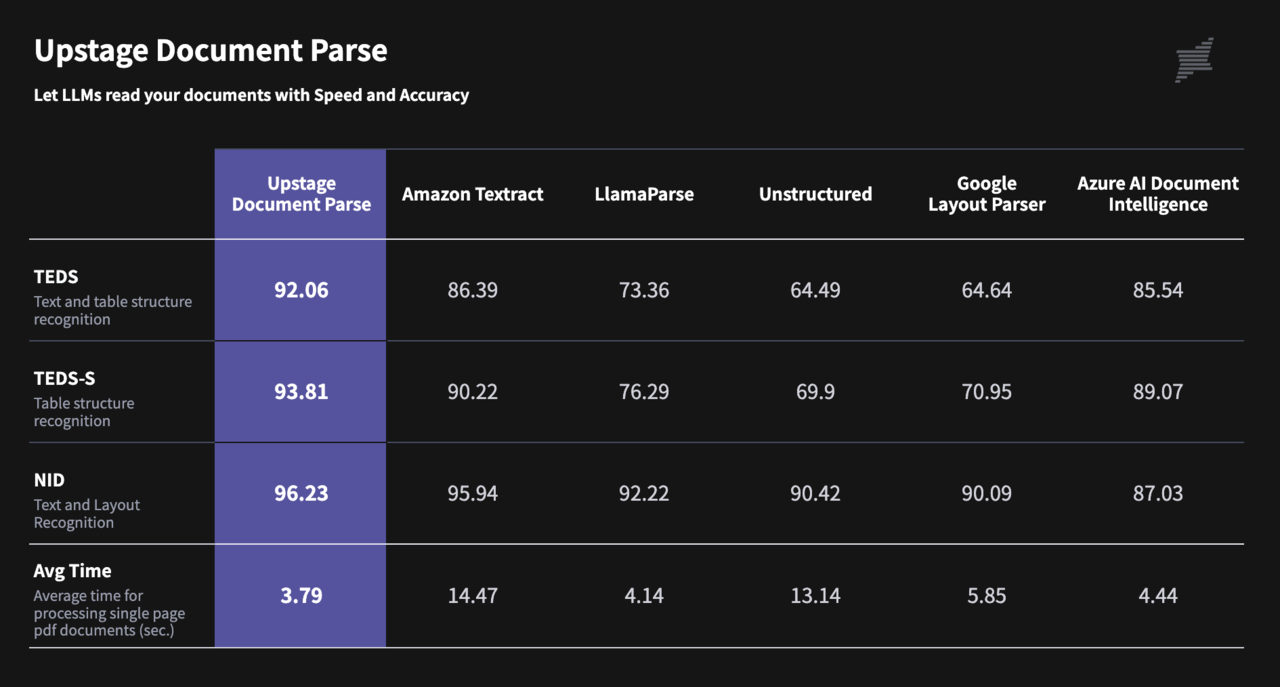
결과에 따르면, 도큐먼트 파스는 레이아웃 및 테이블 구조, 콘텐츠 분석 등 정확성을 측정하는 모든 지표에서 아마존웹서비스(AWS)와 마이크로소프트(MS)를 포함한 빅테크 5개사의 관련 서비스보다 5% 이상 높은 점수를 받았다.
속도면에서도 1분에 100장을 처리, 같은 기준을 적용한 '아마존 텍스트랙트(Textract)'보다 10배, '라마파스(LlamaParse)'보다 5배 가량 빠른 능력을 보였다.

또 DOCX, PDF, PPTX, PNG 등 9종의 문서 처리뿐만 아니라 수식 인식 및 이미지 추출과 같은 새로운 기능을 추가했다. HTML 외에도 헤더 및 테이블 요소를 마크다운 형식으로 제공, LLM 사용자가 입력 문서의 토큰 크기를 줄일 수 있다는 것을 강점으로 들었다.
업스테이지는 2023년부터 자체 OCR 모델을 서비스했다. 같은 해 글로벌 최고 권위인 AI OCR 경진대회 'ICDAR'에서도 아마존과 엔비디아 등을 제치고 1위를 차지한 바 있다. 이런 노하우를 통해 이번에 최고 수준의 모델을 개발했다.
김성훈 업스테이지 대표는 “기업이 가진 기존 문서를 가장 정확하게 자산화시켜 LLM을 실제 업무에 즉각 효율적으로 적용할 수 있도록 만드는 최적의 도구”라며 “다양한 비즈니스에서 활용해 업무 혁신을 현실화할 것”이라고 말했다.
장세민 기자 semim99@aitimes.com
