
알리바바가 열린 결말의 문제 해결과 창의적인 사고에 초점을 맞춘 새로운 인공지능(AI) 추론 모델을 공개했다. 오픈AI의 추론 모델 'o1'에 영감을 받았으며, 기존 수학이나 코딩처럼 명확하고 정량화 가능한 결과를 다루는 모델과는 차별화된 접근법이라고 설명했다.
알리바바는 21일(현지시간) 개방형 추론 문제 해결 역량 강화를 목표로 설계한 AI 모델 ‘마르코-o1(Marco-o1)’의 연구 논문을 아카이브에 게재했다.
이 모델은 오픈AI의 'o1'를 힌트로 개발된 대형추론모델(Large Reasoning Model, LRM)이다. 하지만 o1이 AIME와 코드포스(CodeForces)와 같은 수학 및 코딩 벤치마크에서 뛰어난 성과를 보였다면, 마르코-o1은 구조화되지 않은 과제를 해결하는 데 중점을 두고 설계됐다.
이처럼 명확한 평가 기준이 없는 다양한 분야에서 일반화된 성능을 발휘하는 것이 목표다.
이를 위해 사고 사슬(Chain-of-Thought, CoT) 기반 미세 조정, 몬테카를로 트리 탐색(Monte Carlo Tree Search, MCTS), 그리고 추론 중심의 행동 전략 등 첨단 기술이 적용됐다. 이런 기술은 마르코-o1이 복잡한 문제를 효과적이고 정교하게 해결할 수 있도록 돕는다.
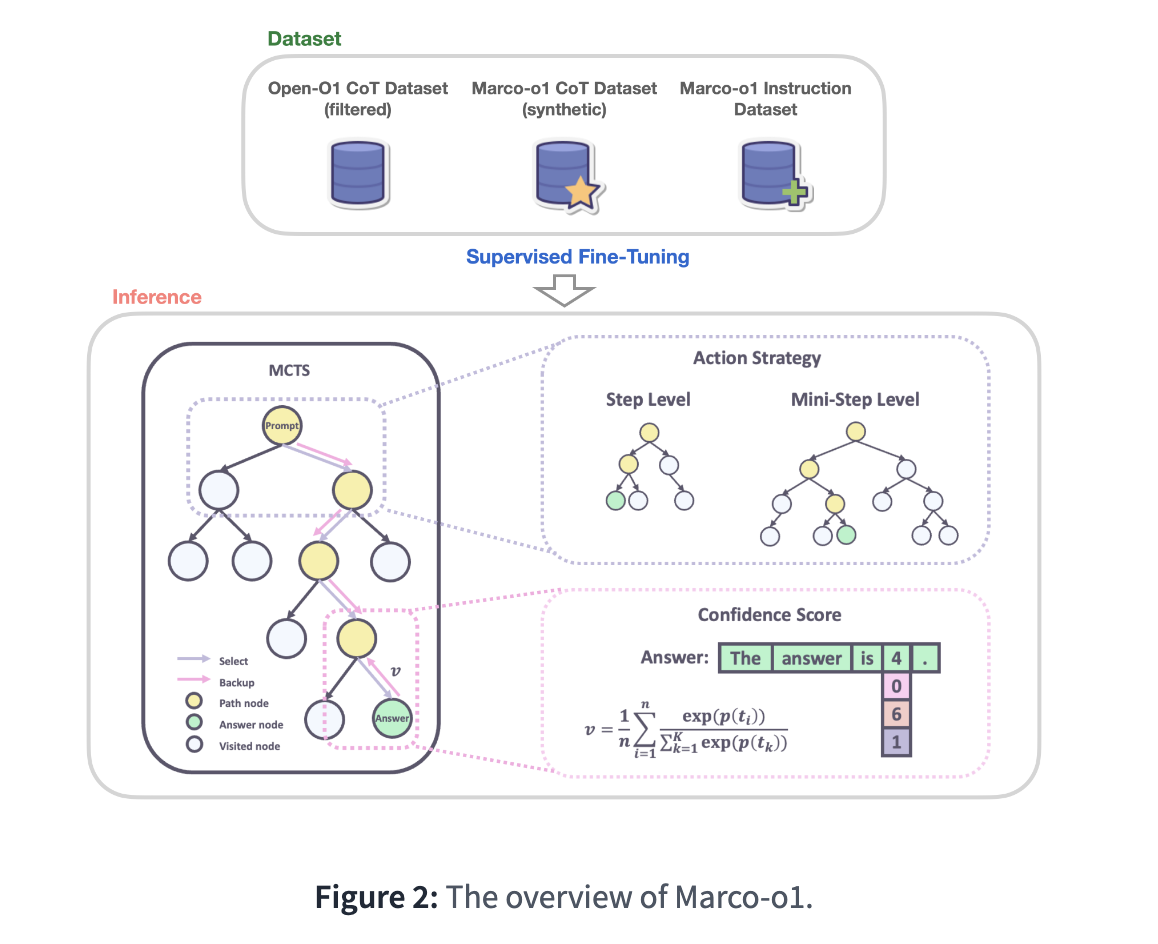
특히 사고 과정을 명시적으로 추적하고 단계적으로 관리할 수 있도록 설계된 CoT 기반 조정은 문제 해결을 투명하고 체계적으로 만든다는 설명이다. MCTS 기술은 문제 해결 과정에서 여러 추론 경로를 탐색하며, 각 경로에 신뢰 점수를 부여함으로써 가장 유망한 경로를 선택해 최적의 해답을 도출하도록 한다.
더불어 문제 해결 시 행동 단위를 동적으로 조정할 수 있는 추론 기반 행동 전략을 채택해 검색 효율성과 정확도를 극대화한다. 또 자기 반성 메커니즘을 도입해 모델이 스스로 해결책을 검토하고 개선하도록 설계됐다. 이 기능은 복잡한 문제에서 정확도를 높이는 데 기여한다.
이처럼 다양한 기술이 결합된 마르코-o1은 구조화된 과제뿐만 아니라 복잡하고 열린 결말의 문제까지도 효과적으로 처리할 수 있는 역량을 보유하고 있다고 전했다.
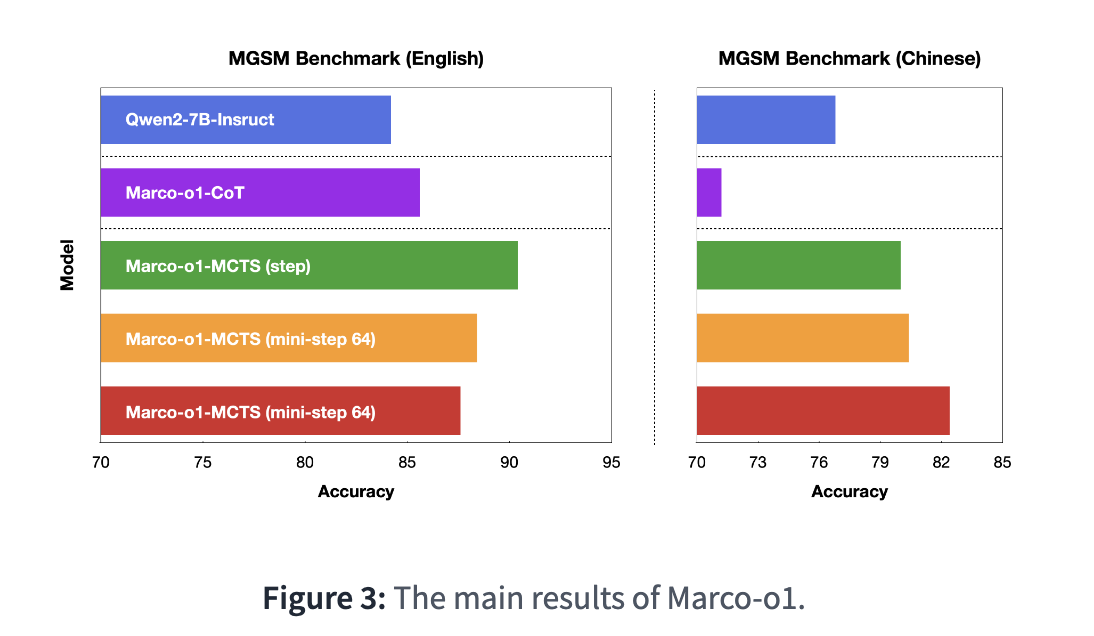
벤치마크 테스트 결과, 마르코-o1은 다국어 수학 벤치마크 MGSM에서 영어 데이터셋 기준 6.17%, 중국어 데이터셋 기준 5.60%의 정확도 향상을 기록했다. 또 번역 작업에서도 뛰어난 성과를 보였으며, 특히 문화적 뉘앙스를 반영한 구어체 번역에서 높은 정확도를 입증했다.
연구진은 "이번 연구는 모델 이름에도 드러났듯 오픈AI의 o1에서 영감을 받았다"라며 "불분명한 대규모 추론 모델에 대한 기술 로드맵을 밝히기 위한 잠재적인 접근 방식을 탐구하는 것을 목표로 한다"라고 밝혔다.
또 "모델은 o1과 유사한 추론 특성을 보이고 있으며, 성능은 완전히 구현된 o1에 미치지 못한다는 점을 인정한다"라며 "이번 연구는 일회성이 아니며, 지속적인 최적화와 지속적인 개선에 전념하고 있다"라고 덧붙였다.
현재 마르코-o1 모델과 코드는 허깅페이스와 깃허브에서 공개, 누구나 사용할 수 있다.
박찬 기자 cpark@aitimes.com
