
엔비디아가 4K 이상의 고화질 이미지를 생성할 수 있는 이미지 생성 인공지능(AI) 모델을 선보였다. 하지만 모델의 매개변수는 5억9000만개에 불과하며 GPU를 장착한 일반 노트북에서도 구동이 가능하다고 설명했다.
엔비디아는 최근 깃허브를 통해 MIT 연구진과 개발한 '사나(Sana)'를 오픈 소스로 공개했다.
사나-0.6B는 최대 4096×4096 해상도의 이미지를 생성할 수 있는 텍스트-이미지 모델로 '선형 확산 트랜스포머(Linear Diffusion Transformer)' 구조다.
고해상도 이미지를 생성하기 위해서는 확산 모델의 매개변수가 커지는 것이 일반적이지만, 연구진은 강력한 텍스트-이미지 정렬을 통해 고해상도, 고품질 이미지를 놀라울 정도로 빠르게 합성할 수 있다고 강조했다.
모델이 작기 때문에 거대한 서버가 필요하지 않으며 노트북 GPU에도 배포할 수 있다. 그럼에도 이미지 품질과 생성 시간에서는 3840×2160 해상도의 이미지를 생성하는 '픽스-아트 시그마'보다 성능이 더 좋다고 밝혔다.
개선된 자동 인코더와 선형 DiT(Document Image Transformer) 및 디코더를 사용해 훈련 및 추론 비용을 줄였다는 설명이다.
우선 자동 인코더의 압축 비율을 이전에 사용했던 8에서 32로 높여서 잠재 토큰 소비를 4배 줄였다. 고품질 이미지는 일반적으로 높은 중복성을 포함하기 때문에 압축 비율을 낮춰도 이미지 품질에는 영향을 미치지 않는다고 전했다.
또 DiT에서 선형 어텐션 블록을 사용하는 셀프 어텐션 메커니즘을 사용해 복잡도를 줄였다. 작은 디코더를 가진 대형언어모델(LLM) '젬마-2(Gemma-2)'를 활용했다. 이 아키텍처는 생각의 사슬(CoT)를 통해 뛰어난 추론 능력을 가지고 있기 때문에 다른 큰 인코더 기반 모델보다 뛰어난 성능을 제공한다.
이 밖에도 4개의 비전언어모델(VLM)으로 학습 이미지 라벨링을 실시했다고 전했다.
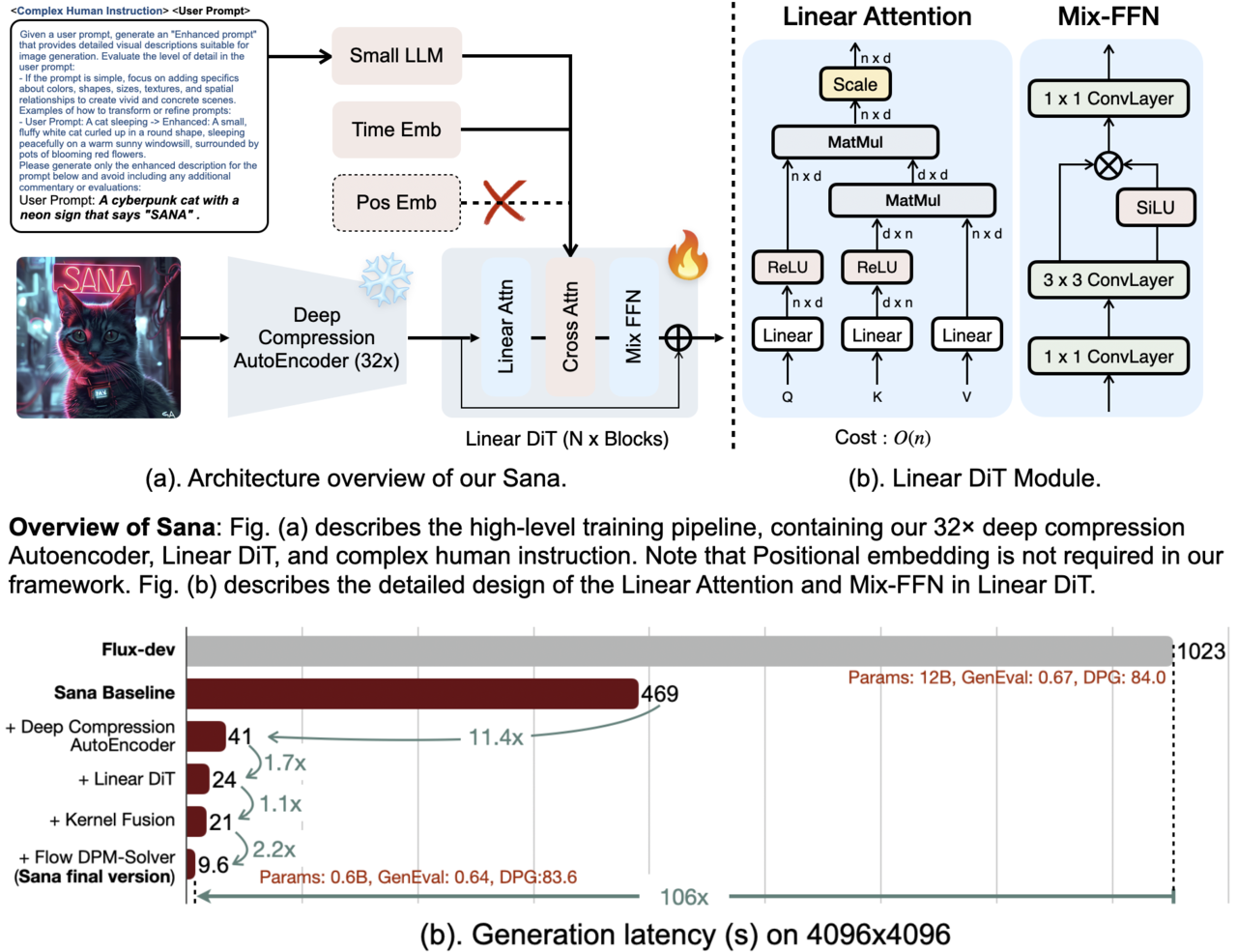
이를 통해 현재 이미지 생성 최강으로 꼽히는 '플럭스(Flux-12B)'와 맞먹는 성능을 보이며, 처리량은 20배 더 작고 100배 이상 더 빠르다고 밝혔다.
특히 16GB 노트북 GPU에서 사용할 수 있으며, 1024×1024 해상도 이미지를 생성하는 데 1초도 걸리지 않는다고 강조했다.
사나는 데모 페이지에서 바로 성능을 확인할 수 있다.
임대준 기자 ydj@aitimes.com
