엔비디아로부터 GPU를 지원받는 클라우드 스타트업 람다가 인공지능(AI) 추론 서비스를 위한 새로운 API를 출시했다. 이 API가 시장에서 가장 저렴한 서비스라고 주장했다.
람다는 12일(현지시간) ‘람다 인퍼런스 API(Lambda Inference API)’를 출시했다고 발표했다.
이 회사는 엔비디아의 강력한 지원을 바탕으로 급성장한 것으로 잘 알려져 있다. 'H100' 'H200' 'B200' 등 최신 엔비디아 GPU를 활용한 클라우드 서비스를 제공하고 있다.
이번 추론 API 출시로 람다는 기존의 AI 모델 학습 및 미세조정에 집중됐던 GPU 서비스를 AI 모델 운영으로 확장하게 됐다.
개발자는 람다의 추론 API 웹페이지에서 API 키를 생성한 뒤 별도 승인 과정없이 바로 서비스를 이용할 수 있다.
이 API는 메타의 '라마 3.3'과 '3.1', 누스의 '헤르메스-3', 알리바바의 '큐원 2.5' 등의 최신 오픈 소스 모델을 지원하며, 향후 비디오 및 이미지 생성 등 멀티모달 모델로 확장할 계획이다.
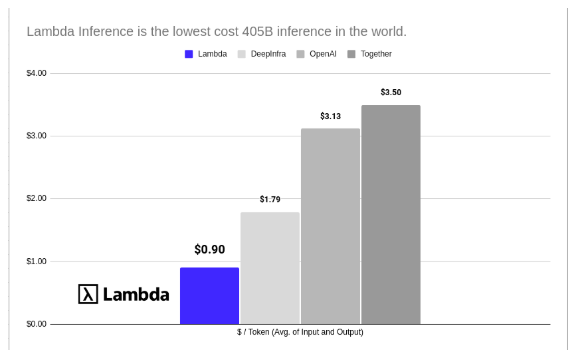
서비스 가격은 파격적으로 저렴하다. 작은 모델인 '라마-3.2-3B-인스트럭트'의 경우 100만 토큰당 0.02달러에서 시작한다. 대형 모델인 '라마 3.1-405B-인스트럭트'는 100만 토큰당 0.90달러다.
또 다른 서비스와 달리 사용한 토큰만큼만 비용을 지불하는 종량제로, 요금에 따른 속도 제한도 없다.
스티븐 발라반 람다 CEO는 X(트위터)를 통해 “돈 낭비를 멈추고 대형언어모델(LLM) 추론을 위해 람다를 사용하라”라고 강조했다.
또 “우리는 AI 커뮤니티에 속도 제한이 없는 추론 API를 자유롭게 사용할 수 있는 환경을 제공하고 싶다"라며 "수조개의 토큰까지 빠르게 확장할 수 있다”라고 설명했다.
이 회사의 진짜 강점은 풍부한 GPU 자원이다. 엔비디아의 지원으로 수만개의 GPU를 보유했다.
람다 인퍼런스 API는 현재 사용 가능하며, 홈페이지에서 가격 및 문서 정보를 확인할 수 있다.
박찬 기자 cpark@aitimes.com
