사후 훈련 과정에서 방대한 양의 학습 데이터 없이도 신중하게 선별된 최소한의 예제 데이터를 통해 추론 모델을 효과적으로 훈련할 수 있다는 연구 결과가 나왔다.
상하이대학교 연구진은 최근 정밀하게 구성된 최소한의 학습 예제만으로도 정교한 추론 능력이 발현될 수 있다는 내용의 논문을 발표했다. 논문 제목은 ‘LIMO: 적을수록 더 나은 추론(Less is More for Reasoning)’이다.
일반적으로 정교한 추론 과제에는 10만개 이상의 방대한 양의 학습 데이터를 사용한 미세조정이 필요하다고 알려졌지만, 이 연구는 복잡한 수학적 추론 능력이 예상보다 적은 예제만으로도 효과적으로 유도될 수 있다는 내용이다. 이는 대규모 데이터 요구에 대한 기존 가정을 뒤집을 뿐만 아니라, 지도 미세조정(SFT)이 주로 암기 효과를 초래하고 일반화에는 덜 기여한다는 지적도 부정하는 결과다.
최근 연구에 따르면, 수작업으로 라벨링된 예제 데이터로 SFT하는 대신 순수한 강화학습(RL) 접근 방식만으로도 모델이 스스로 추론 과제를 학습할 수 있음을 보인 사례가 등장했다. 이 방법은 접근법은 수작업을 줄여 비용과 시간을 아낄 수는 있지만, 여전히 막대한 계산 자원이 필요해 많은 기업이 감당하기 어렵다.
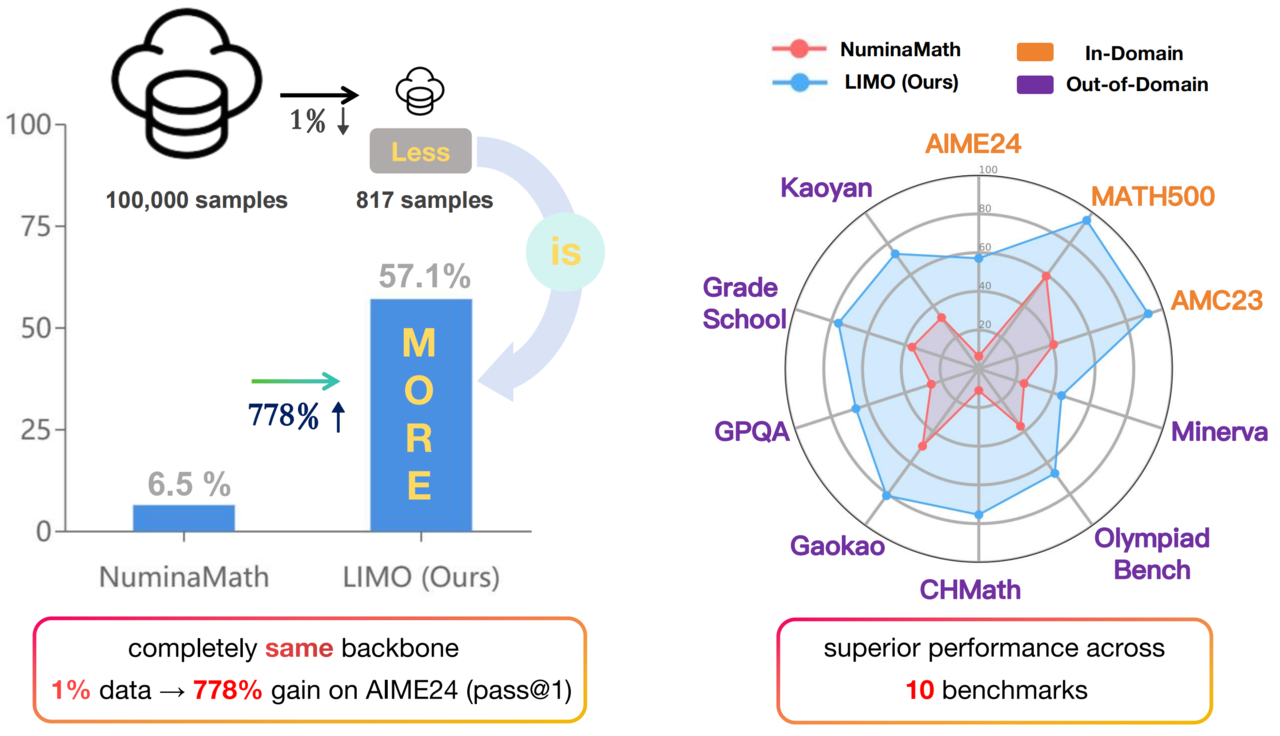
따라서 연구진은 복잡한 수학적 추론 과제를 위해 단 몇백개의 학습 예제만으로 구성된 LIMO 데이터셋을 구축했다. 수작업으로 라벨링된 방대한 예제 데이터셋을 구축하는 대신, 몇백개의 학습 예제를 정교하게 제작하는 것은 많은 기업이 감당할 수 있는 작업이다.
적절한 문제와 해법을 선택, 유용한 데이터셋을 구축하는 것이 핵심이다. 데이터 큐레이터는 복잡한 추론 체인, 다양한 사고 과정, 지식 통합을 요구하는 도전적인 문제를 우선시해야 한다. 또 모델의 기존 학습 분포에서 벗어나도록 문제를 설계, 새로운 추론 접근 방식을 유도하고 일반화 능력을 강화하도록 해야 한다.
해법도 명확하고 체계적으로 구성해야 하며, 문제의 복잡성에 맞춰 추론 단계를 조정해야 한다. 세심하고 구조화된 설명을 통해 점진적으로 이해를 심화하며, 동시에 전략적인 교육 지원 역할도 수행해야 한다는 설명이다.

이런 데이터셋으로 미세조정한 대형언어모델(LLM)은 복잡한 사고 과정(CoT) 추론을 생성할 수 있으며, 이를 통해 높은 성공률로 과제를 수행할 수 있었다고 전했다.
예를 들어, LIMO 방식을 기반으로 선택된 817개의 학습 예제로 미세조정된 '큐원2.5-32B-인스트럭트' 모델은 난이도 높은 AIME 벤치마크에서 57.1%, MATH 벤치마크에서 94.8%의 정확도를 기록했다. 이는 100배 더 많은 예제로 학습된 모델들을 능가하는 성과다.
또 이 모델은 더 많은 데이터와 연산 자원을 사용한 추론 특화 모델 'QwQ-32B-프리뷰'와 오픈AI 'o1-프리뷰'보다도 벤치마크 점수가 높았다.
뿐만 아니라, LIMO 방식으로 학습한 모델들은 훈련 데이터에 포함하지 않은 문제에도 뛰어난 일반화 성능을 보였다. 예를 들어, 올림피아드벤치 과학 벤치마크에서는 QwQ-32B-프리뷰를 능가했으며, 난이도가 높은 GPQA 벤치마크에서는 66.7%의 정확도를 기록해 o1-프리뷰의 최고 점수인 73.3%에 근접한 성과를 보였다.
연구진은 "사전 훈련 과정에서 방대한 수학적 콘텐츠와 코드를 학습한 LLM은 이미 풍부한 추론 지식을 매개변수로 내재하고 있으며, 신중하게 설계된 예제를 통해 이를 활성화할 수 있다"라고 주장했다. 이와 함께 모델에게 더 많이 생각 시간을 제공하면, 사전 학습된 지식을 더 효과적으로 풀어내고 적용할 수 있다고 강조했다.
이를 통해, 방대한 양의 학습 데이터 없이도 복잡한 추론 능력을 효과적으로 이끌어낼 수 있다는 결론이다. 연구진은 “방대한 데이터양이 아니라, 고품질 시연이야말로 복잡한 추론 능력을 발현하는 핵심 열쇠"라고 강조했다.
이처럼 o1과 딥시크 등장 이후 추론 모델의 성능을 높이기 위해 SFT와 RL, 데이터 큐레이팅 등 다양한 사후 훈련 방법이 최근 연구되고 있다.
연구진은 LIMO 모델을 훈련하는 데 사용된 코드와 데이터를 깃허브에 공개했다.
박찬 기자 cpark@aitimes.com
- "사후 훈련에 SFT 없이 RL만 사용하는 것이 효과적"
- '딥시크'와 '딥 리서치' 등장의 의미..."기업들은 더 이상 똑같은 모델 사용하지 않을 것"
- 스탠포드·워싱턴대 "50달러로 추론 모델 구축...'증류' 방식 적용"
- 토큰 7.6%만 사용하는 CoT 기술 등장..."추론 비용 대폭 감소"
- 딥시크 수학 실력 능가하는 오픈 소스 모델 등장..."단 1000달러로 훈련"
- 추론 모델 '생각 길이' 최적화하는 강화학습법 등장
- RAG 필요 없이 LLM이 '자율 검색'하는 추론 기술 등장
- 구글, 새로운 '증강 미세조정' 제안..."ICL 일반화 강점에 미세조정 효율성 합쳐"
- 텐센트·워싱턴대, 인간 라벨링 없는 ‘자가 진화형 AI 학습 프레임워크’ 공개
- MIT “AI 모델 미세조정에서 강화 학습이 망각 적어”
