인공지능(AI) 모델을 미세조정할 때 생기는 ‘치명적 망각(catastrophic forgetting)’, 즉 이전에 학습한 능력을 잃어버리는 문제를 줄이기 위해서 강화 학습(RL)이 효과적이라는 연구 결과가 나왔다.
MIT 연구진은 최근 온라인 아카이브를 통해 지도학습 기반 미세조정(SFT)과 RL을 비교한 논문 ‘RL의 원리: 온라인 강화 학습이 망각을 줄이는 이유(RL's Razor: Why Online Reinforcement Learning Forgets Less)’를 발표했다.
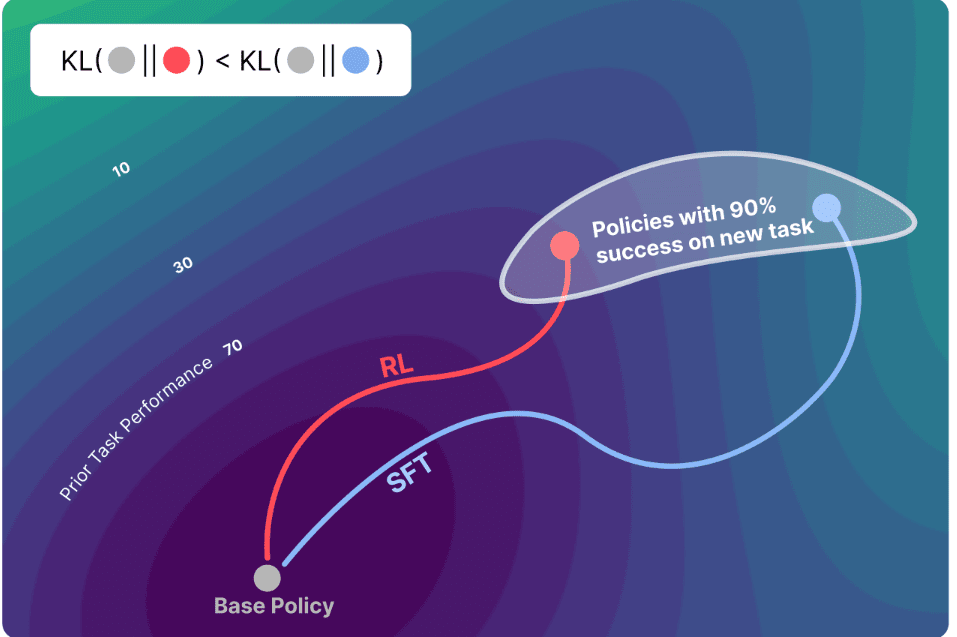
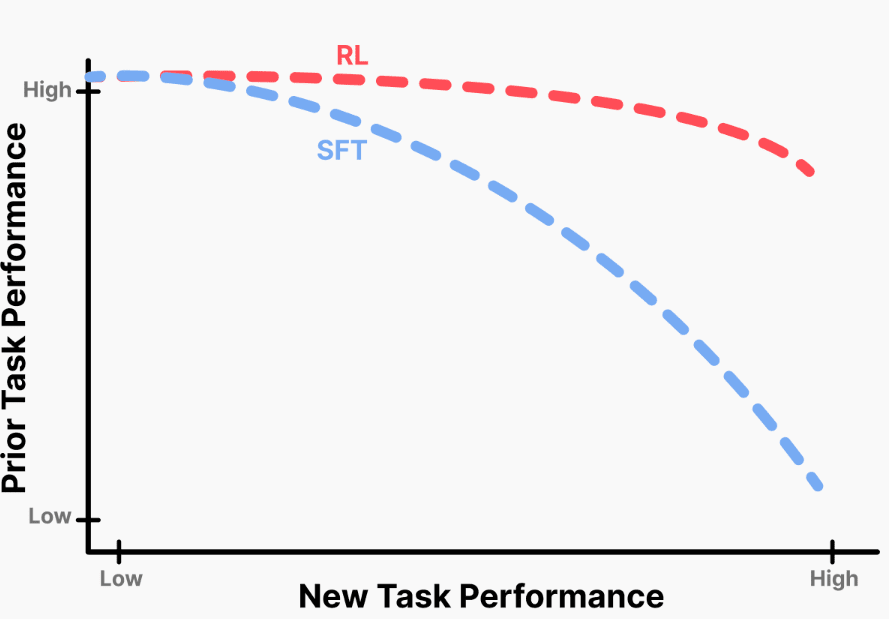
이에 따르면, 두 방식 모두 새로운 작업을 학습하는 데 높은 성능을 발휘했다. 그러나, SFT는 이전에 학습한 내용을 쉽게 잃어버리지만, RL은 이를 잘 보존하는 것으로 나타났다.
연구진은 모델이 새로 학습하면서 원래 모델(기본 정책)과 바뀐 모델(조정된 정책)의 결과가 얼마나 달라지는지가 핵심이라고 설명했다.
이를 설명하기 위해 연구진은 간단한 망각 법칙 ‘Forgetting∝KL(π0, π)’을 내놨다. 여기서 π₀는 원래 모델, π는 새로 조정된 모델을 뜻한다.
쉽게 말해, 새로운 과제를 풀 때 두 모델의 차이를 나타내는 KL값이 클수록 이전에 알던 것을 더 많이 잊는다는 것이다. KL 덕분에 과거 데이터를 다시 확인하지 않아도 망각 정도를 수치로 예측할 수 있게 됐다.
KL 발산(Kullback–Leibler divergence)은 두 확률 분포 간의 차이를 측정하는 척도다. 하나의 확률 분포가 다른 확률 분포로부터 얼마나 다른 정보를 가지고 있는지, 또는 근사한 분포가 이상적인 분포와 얼마나 다른지를 나타낸다. KL 발산은 항상 0 이상이며, 두 분포가 완벽히 일치할 때만 0이 된다.
연구진은 '큐원 2.5 3B-인스트럭트'를 기반으로 수학 추론(Open-Reasoner-Zero), 과학 질의응답(SciKnowEval), 도구 사용(ToolAlpaca) 과제를 학습했다.
이후 헬라스웨그(HellaSwag), MMLU, 트루스풀QA(TruthfulQA), 휴먼이밸(HumanEval) 등 벤치마크에서 성능을 검증했다. 그 결과 RL은 새로운 작업 정확도를 향상하면서도 이전 작업 성능을 유지했지만, SFT는 지속적으로 기존 지식이 줄어드는 양상을 보였다.
로봇 제어 실험(OpenVLA-7B, SimplerEnv)에서도 비슷한 결과가 나왔다. RL은 일반 조작 능력을 유지했지만, SFT는 새로운 작업에서는 성공했으나 기존 조작 능력이 약화됐다.
이후 망각 정도를 KL값에 따라 그래프로 그려보니, 모든 결과가 하나의 예측 곡선 위로 모였다. 이는 망각을 결정하는 핵심 요인이 KL이라는 것을 의미한다.
원인은 학습 방식의 차이에 있었다. RL은 모델이 스스로 만든 출력에서 샘플을 추출하고, 보상에 따라 조금씩 가중치를 조정하면서 학습하기 때문에 원래 모델과 가까운 분포 안에서만 학습이 이뤄진다.
반면, SFT는 정해진 레이블과 맞추는 방식이라 원래 모델과 멀리 떨어진 분포까지 이동할 수 있다. 이론 분석에서도 '정책 경사법(policy gradient)'이 KL 최소값에 수렴한다는 사실이 확인됐다. 정책 경사법은 RL에서 에이전트의 정책을 직접 학습해 최적의 행동을 선택하게 하는 방법이다.
연구진은 다른 지표들도 실험했다. 가중치 변화, 은닉 표현 이동, 업데이트 희소성, 역방향 KL, 총변동 거리, L2 거리 등 여러 방법을 시험했지만, KL만큼 망각을 정확히 예측하는 지표는 없었다.
결국 모델 출력 분포가 원래 모델과 얼마나 가까운지가 지식을 잘 유지하는 핵심 요인이라는 것이 확인됐다고 강조했다.
연구진은 이번 결과를 '강화 학습의 면도날(RL's Razor)'이라고 명명했다. 모델의 망각 현상에 대한 여러 이유를 '오컴의 면도날(Occam's razor)'처럼 가장 간단하게 설명했다는 것이다.
"새로운 작업을 해결하는 모든 방법 중에서 RL은 원래 모델에 가장 가까운 KL을 선호한다"라는 결론이다.
박찬 기자 cpark@aitimes.com
