이미지를 보고 실시간으로 음성으로 설명하는 최초의 오픈 소스 비전-음성 모델(VSM)이 공개됐다. 인공지능(AI) 음성 비서의 핵심 기능을 구축하는 데 도움이 될 것으로 보인다.
프랑스의 인공지능(AI) 스타트업 큐타이는 21일(현지시간) 오픈 소스 비전-음성 모델 ‘모시비스(MoshiVis)’ 논문을 온라인 아카이브에 게재했다.
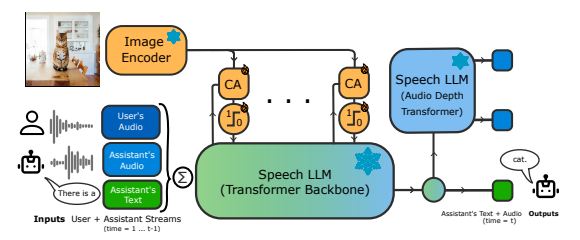
모시비스는 실시간 대화를 위한 음성 기반 모델인 '모시(Moshi)'를 확장, 시각적 입력에 대응할 수 있도록 설계됐다. 모시는 큐타이가 지난해 7월 출시한 최초의 실시간 양방향 음성 기반 대형언어모델(LLM)이다.
모시비스는 모시에 2억600만개의 매개변수를 가진 경량 크로스-어텐션(CA) 모듈을 추가해 구글의 비전-언어 모델(VLM) ‘팔리젬마2-3B-448’의 시각 인코더에서 추출한 시각적 토큰 정보를 모시의 음성 토큰과 결합한다.
이 방식은 모시의 실시간 대화 능력에 시각적 정보를 처리하고 이를 바탕으로 대화할 수 있는 기능을 더한다. 이미지-음성 데이터가 부족한 문제를 해결하기 위해, 음성 없는 이미지-텍스트 데이터를 활용해 모시가 이미지에 대해 대화할 수 있도록 훈련했다.
모시비스는 'M4 프로' 칩이 탑재된 '맥미니(MacMini)'에서 448픽셀 크기의 입력 이미지 1024 토큰에 대해 추론 단계당 약 7밀리초의 지연만 추가하며, 총 55밀리초의 지연을 발생시켰다. 이는 실시간 지연 기준인 80밀리초보다 훨씬 낮은 수준을 유지하는 것이다.
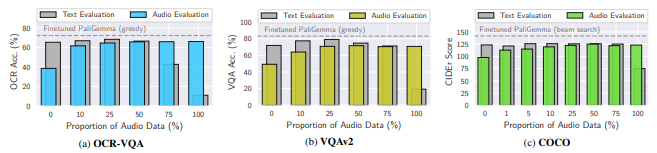
연구진은 모시비스의 CA 적응 모듈을 읽기 작업을 위한 OCR-VQA, 상세한 시각적 질문-응답을 위한 VQAv2, 일반적인 이미지 이해를 위한 COCO 캡션에서 훈련한 후, 이미지-음성 데이터 샘플 비율을 달리하여 성능을 평가했다.
그 결과, 훈련 시 이미지-음성 데이터가 1%만 포함돼도, 모시비스는 음성 입력 프롬프트를 받을 때 뛰어난 성과를 보였고, 25%의 음성 샘플을 사용했을 때는 팔리젬마와 비슷한 성과를 달성했다.
실제 응용 프로그램에서는 자연스러운 음성을 통해 시각적 장면에 대한 자세한 설명을 제공한다. 예를 들어, 모시비스는 주변 광경에 대해 "두개의 녹색 금속 구조물과 변에는 큰 나무들이 있습니다. 뒤로는 밝은 갈색 외관에 검은색 지붕이 있는 건물이 보이는데, 지붕은 돌로 만들어진 것 같습니다"와 같은 설명을 내놓는다.
이 기능은 시각 장애인을 위한 오디오 설명 제공, 접근성 향상은 물론, 기기 사용 설명이나 상품 정보 등과 연결돼 AI 음성 비서의 기본 기능으로 활용할 수 있다.
모시비스의 모델과 코드는 허깅페이스와 깃허브에서 다운로드할 수 있으며, 데모 사이트에서 체험해 볼 수도 있다.
한편, 큐타이는 프랑스의 부호인 자비에르 니엘 일리어드 창립자와 에릭 슈미트 구글 전 CEO 등 억만장자 3명이 '유럽의 오픈AI'를 만들기 위해 2023년 설립한 비영리 단체다. 현재는 AI 음성 비서 관련 기술 개발에 집중하고 있다.
박찬 기자 cpark@aitimes.com
