
알리바바가 제한적인 리소스에서도 고성능을 발휘하는 새로운 비전-언어모델(VLM)을 출시했다. 모바일 AI 에이전트용으로 적합한 모델이라는 설명이다.
알리바바는 24일(현지시간) 이미지와 텍스트 데이터를 해석하고 유용한 정보를 생성하는 VLM ‘큐원2.5-VL-32B-인스트럭트’를 무료 출시했다.
이 모델은 이미지 속 객체를 인식하고 텍스트, 차트, 아이콘, 그래픽, 레이아웃 등을 분석하는 데 뛰어난 성능을 보여, 시각 데이터를 처리하는 데 매우 효과적이라고 전했다.
또 한시간 이상의 비디오를 분석하고 관련된 구간을 식별할 수 있는 능력을 가지고 있다.
이미지를 분석해 객체를 정확하게 식별하고, 테두리나 점을 생성해 안정적인 JSON 출력을 제공하는 객체 위치 지정 기능도 뛰어나다. 이는 실시간 이미지 처리 및 분석에 유용한 기능이다.
청구서, 양식, 표 등과 같은 데이터를 구조화된 형태로 출력할 수 있어, 금융 및 상업 용도의 데이터 분석을 효율적으로 처리할 수 있게 한다고 덧붙였다.
이런 기능들로 인해 휴대폰과 컴퓨터를 구동하기 위해 도구를 사용하는 능력을 가진 '시각 에이전트' 역할을 할 수 있다고 강조했다. 이를 입증하기 위해 휴대폰 앱에서 항공편을 예약하는 장면도 공개했다.
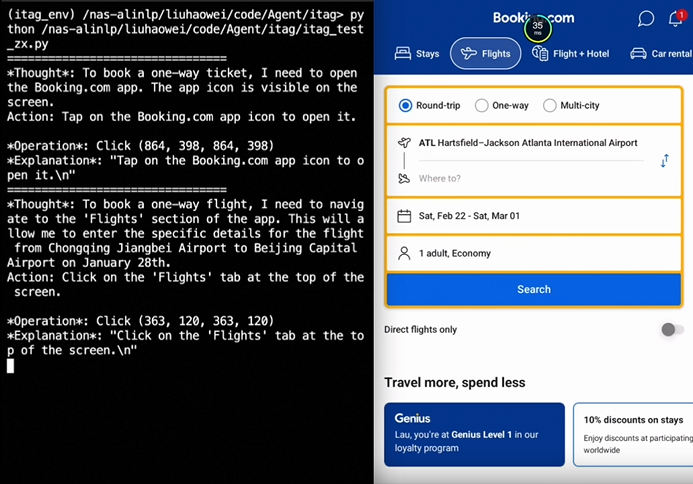
더 큰 모델들의 성능을 능가, 모바일과 같이 제한된 리소스에서도 활용성이 높다는 것을 보여줬다.
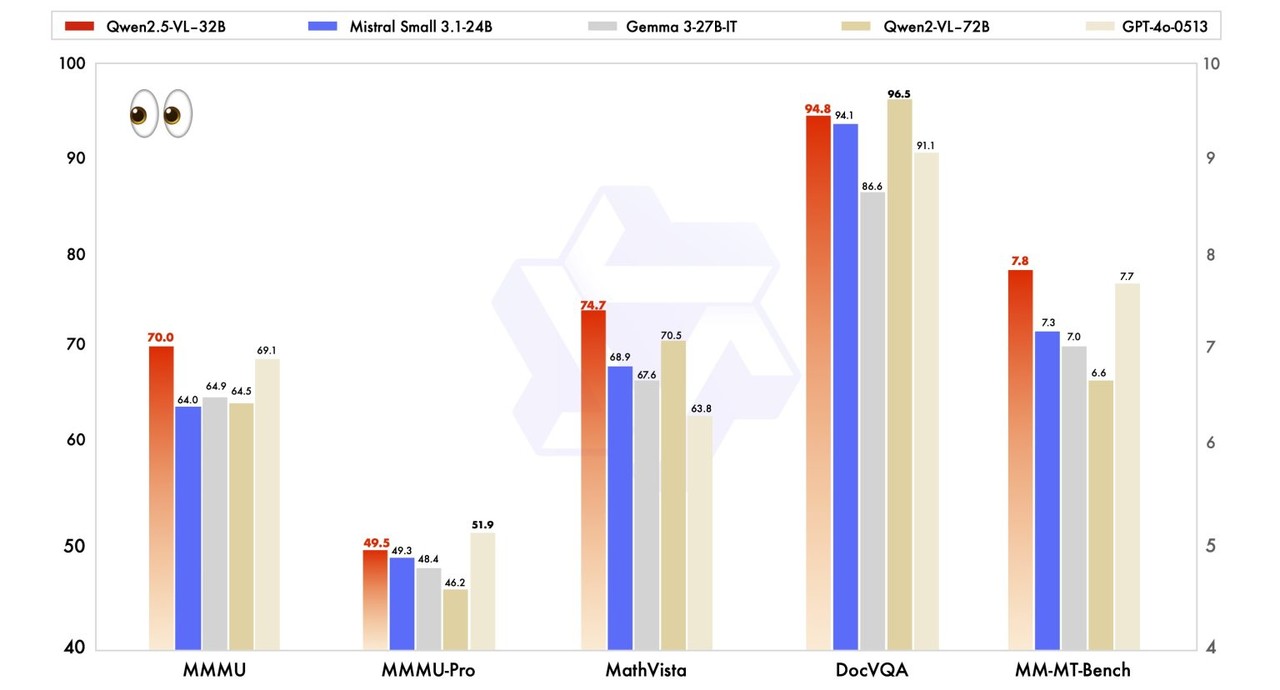
비전 작업에서 이 모델은 'MMMU(Massive Multitask Language Understanding)' 벤치마크에서 70.0점을 기록하며, 이전 모델인 '큐원2-VL-72B'의 64.5점을 넘어섰다.
또, '메스비스타(MathVista)'에서는 74.7점을 얻어 이전 모델의 70.5점을 능가했으며, 'OCR벤치V2(OCRBenchV2)'에서는 57.2/59.1점을 기록하며 기존 이전 47.8/46.1점을 크게 넘어섰다. '안드로이드 제어'에서도 69.6/93.3점을 기록, 이전 모델의 66.4/84.4점을 끌어 올렸다.
텍스트 작업에서도 우수한 성과를 보였다. 'MMLU'에서 78.4점, 'MATH'에서 82.2점, '휴먼이밸(HumanEval)'에서 91.5점을 기록하며, 'GPT-4o 미니'와 같은 모델들을 일부 영역에서 능가했다.
알리바바는 "강화 학습(RL)을 통해 수학 및 문제 해결 능력을 강화했다"라며 "이를 통해 모델의 주관적 사용자 경험도 크게 개선했으며, 응답 스타일이 인간의 선호에 더 잘 맞도록 조정됐다"라고 설명했다.
한편, 알리바바는 이달 초 '쿼크(Quark)'라는 모바일 에이전트를 출시, 큰 인기를 얻고 있다. 또 마누스 AI와 협력, 중국어 에이전트를 개발 중이다. 큐원2.5-VL-32B는 이를 위한 연구 결과인 셈이다.
큐원2.5-VL-32B-인스트럭트 모델은 허깅페이스에서 다운로드할 수 있다.
박찬 기자 cpark@aitimes.com
