
엔비디아가 대형언어모델(LLM)의 순차적 계산 문제를 향상한 새로운 트랜스포머 아키텍처를 선보였다. 컴퓨팅 비용을 절감하면서도 성능을 유지할 수 있다는 설명이다.
엔비디아 연구진은 24일(현지시간) 트랜스포머의 순차적 계산 병목 현상을 해결하는 새로운 아키텍처 최적화 기법 ‘FFN 퓨전(FFN Fusion)’ 논문을 온라인 아카이브에 게재했다.
이번 연구는 트랜스포머 모델의 '피드 포워드 네트워크(FFN)'의 순차적 처리에 따른 문제를 해결하는 것이다.
FFN은 레이어 결과물을 다음 레이어로 전달해 순차적으로 처리하는 방식으로, LLM에서는 문제가 될 수 있다. 모델 크기가 커지면 GPU 간의 계산과 데이터 전송이 차례로 이뤄져 효율성이 떨어지고, 이에 따른 비용도 증가한다. 특히, 실시간 AI 어시스턴트와 같이 다중 토큰 생성이 필요한 작업에서는 이 문제가 더 두드러진다.
엔비디아는 이런 문제를 해결하기 위해 계산 시간을 줄이면서 정확성을 유지할 수 있는 새로운 병렬 처리 기법 ‘FFN 퓨전’을 도입했다. FFN 퓨전의 핵심은 병렬로 실행할 수 있는 FFN 시퀀스를 찾아내 순차 처리 문제를 해결하는 것이다.
FFN 퓨전은 여러 연속적인 FFN 레이어를 하나의 더 넓은 FFN으로 결합하는 방식으로 작동한다. 이 과정에서 여러 FFN의 가중치를 결합해 원래 레이어들의 합처럼 작동하는 단일 모듈을 생성하고, 이를 병렬로 계산할 수 있다.
예를 들어 세개의 FFN이 차례로 배열돼 있을 때, 각 FFN은 이전 FFN의 출력에 의존한다. 하지만 이들을 융합하면 세 FFN이 각각 동일한 입력을 처리하고, 그 출력들을 합쳐 이전 출력의 의존 문제를 제거할 수 있다.
FFN 퓨전은 이론적으로 원래 표현 능력을 유지하면서 효율성을 개선할 수 있다.
연구자들은 FFN 출력 간의 코사인 거리 분석을 통해 상호 의존성이 적은 영역을 찾아내고, 이를 병렬 처리에 적합한 영역으로 구분했다. 이 방식으로 성능을 유지하면서도 계산 효율성을 극대화할 수 있다는 설명이다.
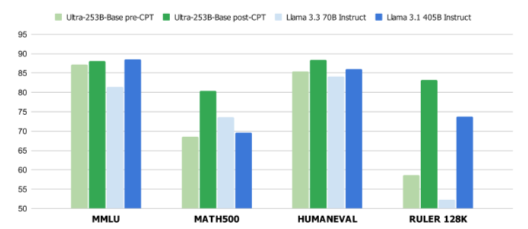
연구진은 ‘라마-3.1-405B-인스트럭트’ 모델에 FFN 퓨전을 적용, 성능과 효율성을 크게 향상한 ‘울트라-253B-베이스’를 개발했다.
훈련 과정에서는 8000 컨텍스트 창에서 540억 토큰을 증류한 뒤 1만6000, 3만2000, 12만8000 컨텍스트에서 단계별 미세 조정을 진행했다. 이 과정을 통해 융합된 모델이 크기는 줄이면서 높은 정확도를 유지할 수 있었다고 전했다.

테스트 결과, 울트라-253B-베이스는 추론 지연 시간을 1.71배 향상하고, 배치 크기 32에서 토큰당 계산 비용을 35배 절감하는 성과를 보였다.
또 다양한 벤치마크에서 '라마-3.1-405B-인스트럭트'와 비슷하거나 이를 능가하는 성능을 나타냈다. 'MMLU'에서 85.17%, 'MMLU-프로'에서 72.25%, '아레나 하드(Areana Hard)'에서 84.92%, '휴먼이밸HumanEval)'에서 86.58%, 'MT-벤치'에서 9.19를 기록했다. 메모리 사용량도 2배 절감됐다.
연구진은 "FFN 퓨전은 더 큰 모델에서 더 효과적이며, 양자화 및 가지치기와 같은 기존 최적화 기술을 보완할 수 있음을 보여준다"라고 밝혔다.
또 "가장 흥미로운 점은, 어텐션과 FFN 레이어를 모두 포함하는 전체 변압기 블록조차도 때때로 병렬화될 수 있다는 것을 확인, 신경 구조 설계에 대한 새로운 방향을 보여준다"라고 강조했다.
박찬 기자 cpark@aitimes.com
- 인셉션, 최초의 확산 방식 언어모델 '머큐리' 공개
- '확산' 방식 언어모델, DLM 등장..."LLM보다 10배 빠르고 10배 저렴"
- 딥시크, 저비용 고효율 'MoE 엔지니어링' 핵심 기술 오픈 소스 공개
- 엔비디아, '딥시크-R1' 절반 크기로 성능 앞서는 오픈 소스 추론 모델 출시
- 유휴 상태에서 미리 답변 준비하는 '수면 시간 컴퓨팅' 등장..."예측 가능한 질문에 효과적"
- 엔비디아, 60분짜리 오디오 1초 만에 받아 쓰는 전사 모델 오픈 소스 공개
- 메타·구글 "LLM은 매개변수당 3.6비트 기억...학습 데이터 더 늘면 일반화 능력 강화"
- 화웨이, LLM 경량화 기술 ‘SINQ’ 오픈 공개..."메모리 사용 70%까지 절감"
