
화웨이가 대형언어모델(LLM)의 메모리 요구량을 크게 줄이면서도 출력 품질을 유지할 수 있는 새로운 양자화(quantization) 기술을 선보였다. 이를 통해 고성능 GPU 없이도 모델 배포가 가능해질 정도로 메모리 사용량을 줄였다는 설명이다.
화웨이의 취리히 컴퓨팅 연구소는 3일(현지시간) 온라인 아카이브를 통해 빠르고 보정(calibration)이 필요 없으며 기존 모델 워크플로우에 손쉽게 통합할 수 있도록 설계된 새로운 양자화 방식 ‘SINQ(Sinkhorn-Normalized Quantization)’를 선보였다.
연구진은 SINQ의 전체 코드를 깃허브과 허깅페이스에 오픈 소스로 공개했다. 기업과 개발자는 이를 자유롭게 사용·수정·상업적 배포까지 가능하다.
SINQ는 모델 크기와 비트폭(bit-width)에 따라 메모리 사용량을 60~70%까지 줄일 수 있다는 설명이다. 기존에 60GB 이상의 메모리가 필요하던 모델도 20GB 환경에서 구동할 수 있어, 고성능 엔터프라이즈 GPU 없이도 대형 모델 실행이 가능하다고 강조했다.
예를 들어, 엔비디아 'A100(80GB, 약 1만9000달러)'이나 'H100(3만달러 이상)' 등의 GPU가 필요했던 모델을 이제는 GeForce RTX 4090(약 1600달러) 한장으로도 구동할 수 있다고 주장했다.
클라우드 환경에서도 비용 절감 효과는 뚜렷하다. A100 기반 작업 비용이 시간당 3~4.5달러인 반면, 24GB GPU 인스턴스는 1~1.5달러 수준에 불과하다. 장기적인 추론 작업에서는 수천달러의 비용 절약 효과를 얻을 수 있다.
일반적으로 신경망은 부동소수점(float) 숫자를 사용해 가중치와 활성화 값을 표현한다. 이는 정밀하지만, 메모리와 계산량이 크다. 양자화는 이런 값을 더 적은 비트로 근사해 저장함으로써 효율성을 높이는 기술이지만, 정밀도가 떨어지는 문제가 있었다.
SINQ는 이런 한계를 극복하기 위해 보정 데이터 없이도 높은 품질을 유지하는 ‘플러그 앤 플레이(plug-and-play)’ 솔루션을 제시했다.
특히, 두가지 핵심 혁신을 통해 기존 양자화 기술의 한계를 뛰어넘는 성능 향상을 이뤄냈다.
기존의 양자화 방식이 하나의 행렬(matrix)에 단일 스케일링 팩터를 적용하는 데 그쳤다면, SINQ는 이중 축 스케일링(Dual-Axis Scaling) 기법을 통해 행(row)과 열(column)에 각각 별도의 스케일 벡터를 적용한다.

이를 통해 특정 값의 이상치(outlier)가 전체 계산 결과에 미치는 영향을 줄이고, 행렬 내 오차의 분포를 교하게 조정할 수 있게 됐다고 밝혔다. 이런 구조적 유연성이 낮은 비트폭 환경에서도 높은 정밀도를 유지하는 데 결정적인 역할을 한다는 것이다.
또 싱크혼 반복 알고리즘에서 아이디어를 얻은 '싱크혼-크노프 정규화(Sinkhorn-Knopp Normalization)' 기법으로 행과 열 단위로 표준편차를 빠르게 조정하도록 설계됐다.
연구진은 이 방법으로 ‘행렬 불균형(matrix imbalance)’이라는 새로운 지표를 최소화할 수 있으며, 기존의 첨도(kurtosis) 기반 방식보다 훨씬 효율적이라고 설명했다.
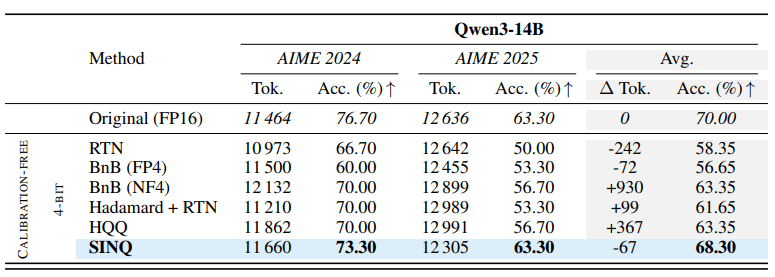
두 방식의 결합으로 SINQ는 RTN, HQQ, Hadamard 기반 양자화 등 기존의 비보정(calibration-free) 양자화 기술들을 전반적으로 능가했다.
SINQ는 '큐원3'와 '라마' '딥시크' 등 다양한 아키텍처에 적용, 테스트 됐다. '위키텍스트2(WikiText2)'와 'C4' 등 주요 벤치마크에서 기존 방식보다 낮은 불확실성(perplexity)와 정보 저장 속도(flip rate)를 기록했으며, 일부 구간에서는 보정 기법과 비슷한 수준의 성능을 보여 줬다.
런타임 효율 면에서도 SINQ는 HQQ보다 2배, AWQ보다 30배 이상 빠르게 양자화를 수행했다.
연구진은 "이번 결과는 양자화 과정에서 데이터 보정 없이도 높은 성능과 효율을 동시에 확보할 수 있다는 것을 의미한다"라고 밝혔다.
또 "LLM 배포의 진입 장벽을 낮춰 개발자와 연구자가 품질이나 호환성 측면에서 큰 타협 없이 모델을 효율적으로 축소할 수 있도록 지원하겠다"라며, 추가 업데이트도 예고했다.
박찬 기자 cpark@aitimes.com
