아주 다양한 머신러닝 알고리즘을 그 데이터에 대한 설명 즉, 레이블의 유무에 따라 구분한 지도 학습, 비지도 학습 그리고 준지도 학습을 지난 회에 설명했다. 이번 회에서는 명시적인 데이터가 없더라도 프로그램의 결정에 따른 피드백에 따라 학습하는 강화 학습의 발전 과정에 대해 알아본다.
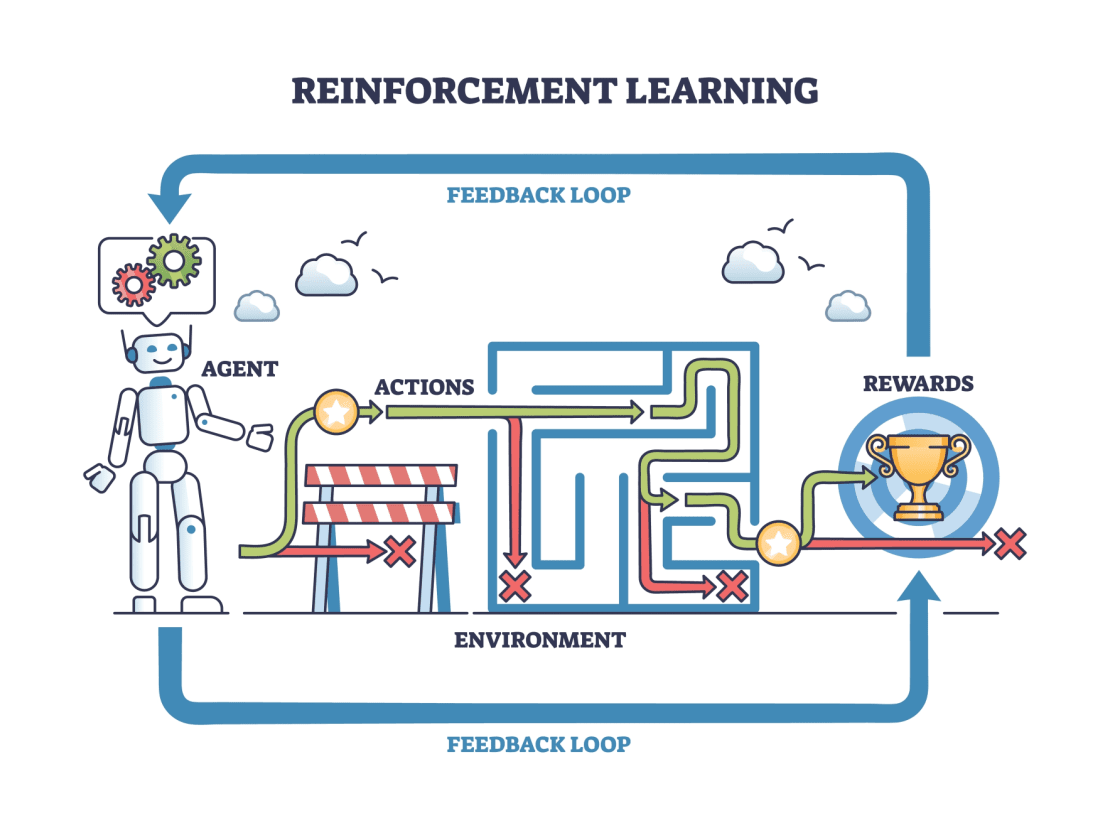
강화 학습(Reinforcement Learning)은 특정 환경 내에서 행동을 취하고, 행동의 결과로 보상이나 처벌을 받으면서 누적 보상을 최대화하는 최적의 행동 정책을 학습하는 방식이다. 머신러닝 프로그램에 명시적인 정답을 주지 않고 프로그램이 결정하도록 하는데, 다만 그 결정에 대해서 옳은 결정인지 잘못된 결정인지 피드백을 받을 수 있도록 하는 것이다. 이런 피드백을 ‘보상(Reward)’이라고 하며, AI가 시행착오를 통해 다음 결정에서는 되도록 긍정적 보상을 받을 수 있는 방향으로 결정하고, 부정적 보상을 받은 방향으로는 결정하지 않도록 학습하는 것이다.
강화 학습 알고리즘으로는 Q-러닝, 몬테카를로(Monte-Carlo) 학습, 시간차(Temporal-Difference) 학습, 정책 경사(Policy Gradient), AC2 그리고 딥마인드가 개발한 DQN(Deep Q-Network) 등이 있다.
세개의 차선으로 이루어진 미니 트랙에서 모형 자동차를 운행하며 강화 학습하는 예를 들어 보자. 차량은 주행 중 가장 가운데 차선으로 가면 +1점을 보상받고, 양쪽 끝 차선으로 가면 0점, 세개의 차선을 벗어나면 -1점을 받는 머신러닝 프로그램으로 동작한다. 주행에 관련된 특정한 지시가 없었으므로 초기에는 이 차량이 무작위로 이리저리 이동하며 차선을 벗어나기도 하겠지만, 각 지점에서 지점 정보와 바퀴의 방향 설정 정보에 따라 점수가 증가하거나 줄어들면서 차량은 학습하게 된다. 학습이 반복되며 차량은 각 지점에 점점 더 점수가 높아지는 방향으로 위치 제어를 하게 되고, 결국은 가운데 차선으로만 주행할 수 있게 되는 것이다.
강화 학습은 한마디로 시행착오를 통해 학습하는 방식이다. 시행착오를 통해 학습한다는 개념은 이미 1800년대 중반부터 형성됐고, 이때는 주로 동물의 행동에 대한 관찰을 설명하기 위해 사용됐다. 1911년에는 미국의 심리학자 손다이크(Edward Thorndike)가 선택의 경향과 행동 강화의 연관성을 설명하는 '효과의 법칙(Law of Effect)'을 통해 시행착오 학습의 본질을 간결하게 설명했다.
그것은 특정 행동의 선택에 있어서 만족도가 높은 결과를 일으키는 행동은 연결성이 높아져 그 행동을 다시 시행할 가능성이 높고, 불편함으로 드러나는 특정 행동은 연관성이 약해져 다시 시행할 가능성이 낮아진다는 것이었다. 1927년에는 파블로프의 조건 반사 실험에 관한 논문이 영어로 번역되며 ‘강화(Reinforcement)’라는 용어가 처음 등장했다. 이는 동물에게서 자극이 행동 패턴을 강화하거나 또는 약화하는 개념을 설명하려 한 것이다.
동물이 아닌 컴퓨터, 즉 기계에 시행착오를 통해 학습을 구현한다는 아이디어는 앨런 튜링의 1948년 논문 ‘지능을 가진 기계(Intelligent Machinery)’에 명시적으로 나타났다. 논문에서 튜링은 “기계의 행동이 틀렸을 때 고통 자극을 가하고, 옳았을 때 쾌락 자극을 가한다”라며 “적절한 자극을 신중하게 가하면 성격은 바람직한-잘못된 행동이 감소하는- 쪽으로 수렴하리라고 예상할 수 있다”라고 했다. 튜링은 논문에서 머신러닝의 개념을 '기계 교육(Education of Machinery)'으로 소개했으며, 학습하는 방법으로 현대 강화 학습의 보상과 처벌에 관한 개념을 제시했다.
1951년에는 강화 학습을 적용한 기계가 만들어졌다. AI의 선구자인 마빈 민스키가 박사 과정을 이수하며 개발한 최초의 신경망 학습기기 ‘SNARC(Stochastic Neural Analog Reinforcement Calculator, 확률적 신경 아날로그 강화 계산기)’였다. 실제 움직이는 마우스 없이 시뮬레이션만 수행했지만, 이는 섀넌의 마우스 테세우스를 본떠 개발했고 미로 문제 푸는 법을 학습할 수 있음을 발견했다. 비록 아날로그 회로로 구성했지만, 최초의 신경망 학습기기를 개발하고 신경 아날로그 강화 이론으로 박사 학위를 받은 민스키가 신경망 AI에 대한 공격의 선봉에 섰던 것은 참으로 아이러니한 상황이었다.
1960년 영국의 미치(Donald Michie)는 ‘MENACE(Matchbox Educable Noughts And Crosses Engine)’라고 하는 기계적인 컴퓨터 프로그램을 구현했다. 쉽게 컴퓨터를 사용하기는 어려웠던 시절이어서 그는 304개의 성냥갑으로 프로그램을 구현했는데, 수백번의 게임을 통해 결과에 따라 각 성냥갑의 구슬 수량을 업데이트해 프로그램을 훈련할 수 있었다. 이때 박스에 구슬을 추가하거나 제거해서 결정을 보상하거나 처벌했는데, 이후 MENACE는 컴퓨터 프로그램으로 만들어졌고, 강화 학습의 대표적인 알고리즘인 ‘Q-러닝’ 개발에 상당한 영향을 미쳤다.
이후 1970년대와 1980년대를 거쳐 조금씩 발전하던 강화 학습에 대한 연구는 서튼(Richard Sutton)과 바르토(Andrew Barto)에 의해 ‘강화 학습’이라는 용어로 정립되고, 현대적 계산 모델로 발전했다. 이들은 1980년대 초부터 강화 학습 분야를 개척했으며, 1998년에 초판이 발행된 그들의 책 ‘강화 학습(Reinforcement Learning)은 이 분야의 교과서로 자리매김했다. 그들은 책에서 강화 학습은 시행착오를 통한 학습 외에도 최적 제어(Optimal Control) 문제와 시간차(TD, Temporal-Difference) 학습이 결합하면서 현대의 강화 학습을 만들어냈다고 했다.
최적 제어라는 용어는 1950년대 후반에 동적 시스템의 동작을 시간에 따라 최소화하거나 최대화하기 위한 컨트롤러를 설계하는 문제를 설명하기 위해 사용됐는데, 다양한 접근 방식이 제시됐다. 특히 1950년대부터 연구된 마르코프 결정 과정(MDP, Markov Decision Process)’ 문제를 해결하기 위해 스탠포드 교수인 하워드(Ronald Howard)가 MIT에 있던 1960년에 제시한 방법은 현대 강화 학습 이론과 알고리즘의 기초가 됐다. 1989년에는 영국의 왓킨스(Christopher Watkins)가 박사 논문 ‘지연된 보상으로부터의 학습’에서 MDP 제어를 최적화하기 위해 보상과 처벌 시스템을 적용한 모델로 Q-러닝이라는 새로운 알고리즘을 제안하며 강화 학습이 널리 활용되기 시작했다.
마지막으로 시간차(TD) 학습은 아서 사무엘이 1959년의 논문 ‘체커 게임에서 머신러닝에 대한 연구’에서 최초로 제안하고 구현했다. TD 학습은 강화 학습의 독특한 특징인 지연된 보상 즉, 당장의 보상이 아닌 장기적인 관점에서 최적의 전략을 찾는 특징에 중요한 역할을 한다. 한동안 큰 발전이 이뤄지지 않던 TD 학습은 1980년대가 돼서 추가 연구가 활발히 진행됐는데, 1989년에 Q-러닝을 통해 강화 학습에 결합했다.
그러나, 한편으로 IBM의 테소로(Gerald Tesauro)는 아서 사무엘의 TD 학습의 형태를 개선하고 이를 인공 신경망으로 구현한 ‘TD-개먼(Gammon)’ 프로그램을 1992년에 발표하며 큰 관심을 받았다. 이는 백개먼(Backgammon)이라는 보드게임을 플레이하는 프로그램으로 게임에 탐색이 아닌 직관적 접근 방식으로, 신경망과 강화 학습이 본격적으로 사용된 모델이라는 특징이 있었다. MENACE와 TD-Gammon은 후에 게임과 강화 학습을 설명할 때 좀 더 자세히 알아볼 예정이다.

이렇게 시행착오에 의한 학습과 최적제어 그리고 TD 학습이 결합하며 1990년대에 정립된 강화 학습은 수많은 시뮬레이션을 통해 학습하는 방식으로 AI 프로그램이 스스로 규칙을 익히고 실력을 향상할 수 있게 해줬다. 특히 체커, 체스, 아케이드 게임, 바둑과 같이 경기 규정과 제한 사항이 명확하고, 점수라는 또 다른 명확한 보상이 있는 게임들은 강화 학습을 적용하기에 이상적인 사례리다.
2016년 이세돌과의 바둑 시합에서 4승을 거둔 알파고는 강화 학습을 적용한 대표적인 사례로, DQN과 몬테카를로 탐색 트리를 포함한 여러 머신러닝 알고리즘이 복합적으로 활용됐다. 또 로봇 청소기나 자율 이동 로봇도 미지의 공간을 돌아다니고 부딪히며 탐색하는데 강화 학습이 적용될 수 있다.
한편으로 강화 학습의 어려운 점은 많은 경우 보상에 지연이 생겨 프로그램이 어떤 결정이 긍정적 결과를 갖는지 결정하기 어려울 때가 있다는 것이다. 지점에 따라 좋고 나쁜 결정을 바로 알 수 있는 차량 주행과 달리, 체스 게임의 경우 전체 경기가 다 끝나야 승패 결과를 알 수 있다. 경기 동안 이뤄진 수많은 수 중에서 승패를 결정짓는데 어느 수가 옳았고 어느 수가 잘못된 것인지 알기 어려울 수도 있다는 것이다.
문병성 싸이텍 이사 moonux@gmail.com
- [AI의 역사] 58 교사가 있는 학습과 정답지가 없는 학습 - 머신러닝의 분류 (상)
- [AI의 역사] 57 1990년대에 개발된 머신러닝 알고리즘들 – 머신러닝 전성시대(하)
- [AI의 역사] 56 기존 이론이 발전해 온 머신러닝 알고리즘들 – 머신러닝 전성시대(중)
- [AI의 역사] 60 AI의 겨울인가 아닌가? – 세기말 전후의 AI 연구
- [AI의 역사] 61 AI 노벨상을 비난한 위대한 이방인의 불만 – 쉬미트후버와 순환 신경망의 개발
- [AI의 역사] 62 또 다른 장벽에 가로 막힌 신경망 연구 -기울기 소실 문제와 과적합 문제
