
텐센트가 다국어 번역에 특화된 오픈 소스 인공지능(AI) 모델 2종을 공개했다.
텐센트는 최근 차세대 번역 모델 '훈위안-MT-7B(Hunyuan-MT-7B)'와 '훈위안-MT-키메라-7B(Hunyuan-MT-Chimera-7B)'를 공개했다. 특히 훈위안-MT-7B는 중국에서 열린 'WMT 2025' 기계 번역 대회에서 31개 언어쌍 가운데 30개에서 1위를 기록하며 주목을 받았다.
훈위안-MT-7B는 70억 매개변수를 갖춘 번역 모델로, 티베트어·몽골어·위구르어·카자흐어 등 중국 소수 언어를 포함한 33개 언어 간 상호 번역을 지원한다. 이처럼 데이터가 적은 언어에서 뛰어난 결과를 내는 등 동급 최고 수준의 성능을 달성했다고 주장했다.
동시 공개된 훈위안-MT-키메라 7B는 약한 모델과 강한 모델을 융합하는 방식으로, 여러 번역 출력을 결합한 뒤 강화 학습(RL)과 집약 기법을 활용해 정제된 결과를 제공한다. 이런 방식을 도입한 최초의 오픈 소스 번역 모델로, 단일 시스템에 비해 뛰어난 번역 품질을 구현했다는 설명이다.
두 모델은 5단계 학습 프레임워크를 기반으로 훈련됐다. ▲112개 언어와 방언을 아우르는 1.3조 토큰 규모의 일반 사전 학습 ▲mC4·OSCAR·OPUS 등 대규모 데이터셋을 활용한 번역 특화 사전 학습 ▲지도형 미세조정(SFT) ▲그룹 상대 정책 최적화(GRPO) 알고리즘 기반 강화 학습 ▲약-강 결합 강화학습(Weak-to-Strong RL) 순으로 구성됐다.
특히, 훈위안-MT-키메라 7B는 마지막 단계를 통해 번역 견고성을 강화하고 반복 오류를 줄였다는 설명이다.
성능 평가 결과도 눈에 띈다.
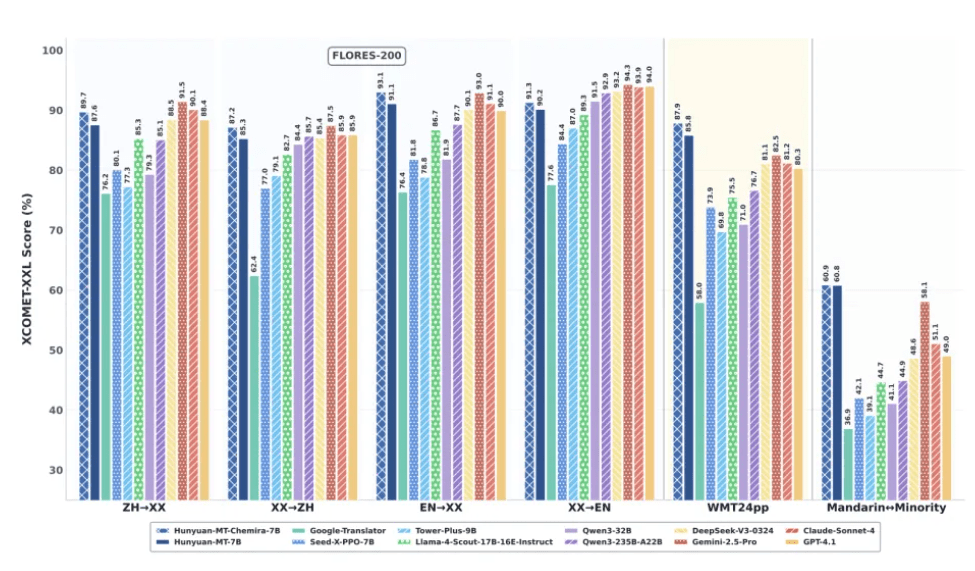
'WMT24pp' 영어-기타 언어 평가에서 훈위안-MT-7B는 XCOMET-XXL 기준 0.8585를 기록, '제미나이-2.5-프로(0.8250)'와 '클로드 소네트 4(0.8120)'를 능가했다.
'FLORES-200(33개 언어, 1056쌍)' 평가에서도 0.8758을 달성해 '큐원3-32B(0.7933)' 등 오픈 소스 모델을 크게 앞섰다. 특히 중국어와 소수민족 언어 간 번역에서는 0.6082로, 제미나이-2.5-프로(0.5811)를 넘어 저자원 번역 성능 개선 가능성을 보여줬다.
비교 평가에서는 구글 번역기 대비 15~65% 더 높은 성능을 기록했으며, 'Tower-Plus-9B·Seed-X-PPO-7B' 같은 특화 모델도 앞질렀다. 훈위안-MT-키메라-7B는 FLORES-200에서 약 2.3% 추가 성능을 높였는데, 특히 중국어-기타 언어 및 비영어-비중국어 번역에서 강점을 보였다.
인간 평가에서도 경쟁력을 입증했다. 사회, 의료, 법률, 인터넷 등 다양한 도메인에서 진행된 맞춤형 평가에서 훈위안-MT-7B는 평균 3.189점을 기록해 제미나이-2.5-프로(3.223), 딥시크-V3(3.219)와 근접한 성과를 냈다. 반면, 구글 번역기는 평균 2.344점에 그쳤다.
이번 훈위안-MT 모델은 허깅페이스에 제공된다.
한편, 텐센트도 최근 굵직한 오픈 소스 모델을 잇달아 공개, 중국 내 경쟁에서 자리를 잡아가고 있다.
지난 6월 희소 전문가(sMoE) 방식을 채택, 성능과 효율을 동시에 잡은 추론 모델 ‘훈위안-A13B’를 출시했다. 또 7월에는 자연어나 이미지 입력으로 인터렉티브한 3D 가상 세계를 생성할 수 있는 '훈위안 3D 월드 모델 1.0'을 공개해 화제가 됐다.
박찬 기자 cpark@aitimes.com
