텐센트와 메릴랜드대학교 연구진은 25일(현지시간) 대형언어모델(LLM)의 추론 능력을 끌어올릴 새로운 강화 학습(RL) 기법 ‘패러렐-R1(Parallel-R1)’에 관한 논문을 온라인 아카이브에 공개했다.
병렬적 사고(Parallel Thinking)는 대형언어모델(LLM)이 단일 경로가 아닌 여러 추론 경로를 동시에 탐색하도록 해, 복잡한 문제 해결 능력을 높이는 새로운 접근법으로 주목받고 있다.
문제 해결 시 하나의 경로만 따르는 것이 아니라, 동시에 여러 추론 경로를 통해 다양한 답안을 탐색한 뒤 결론을 도출하는 방식이다. 구글이 국제수학올림피아드에서 '제미나이 딥 싱크(Gemini Deep Think)'가 금메달 성적을 낸 비결로 이 방식을 언급한 바 있다.
지금까지는 주로 답안을 다수 생성한 뒤 최적 선택(best-of-N)이나 트리 탐색(Tree of Thoughts) 같은 방식을 도입해 왔다.
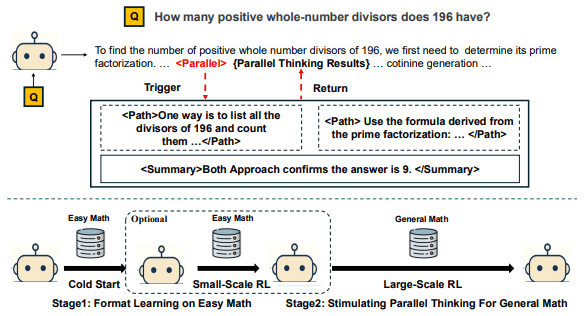
이번 연구의 핵심은 모델의 크기를 확장하는 대신, 추론 과정에서 병렬적 사고를 직접 학습하고 활용하도록 설계했다는 점이다. 패러렐-R1은 병렬 사고를 모델 훈련 단계에서 직접 내재화, 복잡한 문제에서 이를 수행할 수 있도록 만든 최초의 강화 학습(RL) 프레임워크다.
이 프레임워크는 ▲콜드 스타트(cold-start) 단계 ▲쉬운 수학 RL 단계 ▲일반 수학 RL 단계 등으로 구성된 단계적 학습(curriculum learning) 구조를 활용해, RL 학습 초기에 발생하는 콜드 스타트 문제를 해결했다. 콜드 스타트는 데이터가 없거나 새로운 시스템이 시작돼 초기 성능이 저하되는 문제를 말한다.
콜드 스타트 단계에서는 쉬운 수학 문제를 이용해, 대형 모델 '딥시크-R1' 압축 버전이 7000여개의 병렬 추론 예시를 만들도록 하고, 이를 바탕으로 지도 학습(SFT)을 진행했다.
그다음 쉬운 수학 RL 단계에서는, 이미 병렬 추론 방식을 배운 모델에 RL을 적용하고, 정답을 맞히는 능력과 병렬 구조 사용을 동시에 보상하는 ‘교대 보상 전략’을 사용했다.
마지막으로 일반 수학 RL 단계에서는 더 어려운 수학 문제로 학습 범위를 넓혀, 모델이 병렬적 사고 능력을 다양한 문제에 적용할 수 있도록 강화했다.
이를 통해 모델은 특정 지점에서 <Parallel> 태그를 생성하고 여러 <Path>를 전개한 뒤, <Summary> 블록에서 결론을 종합하는 방식으로 구조적 추론을 수행한다.
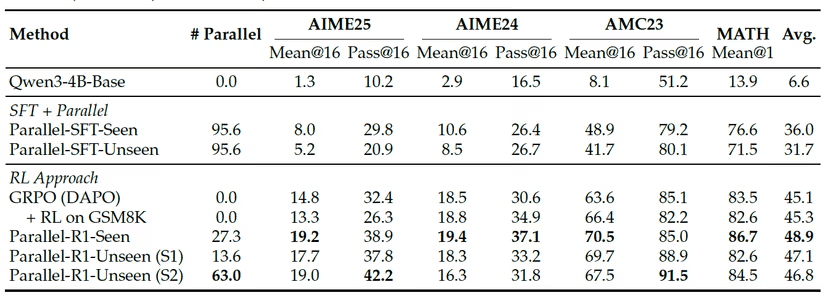
오픈 소스 모델 '큐원-3-4B-베이스'에 패러렐-R1을 적용한 결과, 'MATH' 'AMC23' 'AIME' 등 수학 벤치마크 전반에서 기존 RL 모델보다 평균 8.4% 정확도 향상을 기록했다. 특히, 'AIME25'에서는 기존 대비 42.9% 성능 향상이라는 두드러진 성과를 보였다.
연구진은 병렬적 사고가 학습 초반에는 탐색 전략으로, 이후에는 다각적 검증 도구로 활용되는 점에 주목했다. 이는 단순 정답 산출을 넘어, 모델이 스스로 사고 과정을 확장하고 검증하는 새로운 추론 패러다임을 열 수 있다는 것을 의미한다고 강조했다.
또 패러렐-R1이 방대한 수작업 데이터 제작이나 초거대 매개변수 확장 없이, 추론 단계에서 성능을 끌어올릴 수 있는 효율적 방법론이라고 강조했다. 연구진은 “복잡한 데이터 파이프라인 없이도 병렬적 사고를 학습, 실제 기업 환경에서도 고도 추론 AI를 경제적으로 활용할 수 있다”라고 밝혔다.
현재 패러렐-R1 관련 코드는 깃허브에서 다운로드할 수 있다.
박찬 기자 cpark@aitimes.com
