화웨이가 별도의 미세조정 없이 인공지능(AI) 에이전트의 성능을 지속적으로 향상할 수 있는 실시간 학습 패러다임을 선보였다. 메모리 시스템을 추가해 실시간으로 지식을 업데이트한다는 내용인데, 이처럼 에이전트에 메모리를 더해 기존 문제를 해결하는 방안이 잇달아 등장하고 있다.
화웨이의 연구 조직인 노아 아크 랩(Noah's Ark Lab)과 런던대학교(UCL)는 최근 온라인 아카이브를 통해 '메멘토(Memento)'라는 논문을 발표했다. 관련 코드는 깃허브에 공개했다.
현재 대형언어모델(LLM) 기반 에이전트의 성능을 향상하기 위해서는 미세조정을 통해 기반 모델 자체를 업데이트하는 것이 일반적이다. 따라서 새로운 상황에 적응하는 것은 불가능하며, 업데이트에는 시간과 비용이 들어간다. 특히, 연구진은 미세조정 중 매개변수를 변경하면 사전 학습 과정에서 습득한 지식이 손상될 수 있다고 지적했다.
이상적인 에이전트는 기본 모델을 미세조정하는 대신, 실시간 환경과 상호 작용하면서 동작을 업데이트할 수 있어야 한다는 것이다.
연구진이 내놓은 방법은 외부 메모리를 활용해 경험을 따로 저장하는 식이다. 새로운 과제에 직면했을 때, 에이전트는 과거의 비슷한 상황을 활용해 의사 결정을 내린다.
이 프로세스는 AI에서 에이전트에게 최적의 결정을 내리도록 가르치는 고전적인 프레임워크 '마르코프 결정 프로세스(MDP)'를 기반으로 한다. 표준 MDP에서 에이전트는 현재 상태를 관찰하고, 행동을 선택하고, 보상이나 페널티를 받는다. 에이전트의 목표는 시간이 지나며 총 보상을 극대화하는 전략을 학습하는 것이다.
MDP를 메모리로 증강한 것이 이번 연구의 핵심인 'MDP(M-MDP)'다. 이는 에이전트가 현재 상태와 잠재적 행동뿐만 아니라 과거 이벤트에 대한 풍부한 기억까지 고려할 수 있도록 프레임워크를 강화한다.
이 에이전트는 사례 기반 추론(CBR)이라는 기법을 사용하는데, 이는 이전 문제 해결 경험을 바탕으로 해결책을 검색하고 문제를 수정한다. 예를 들어, 웹 기반 작업을 성공적으로 완료한 에이전트는 경험을 활용해 이전에는 본 적이 없지만, 구조적으로 유사한 작업을 해결할 수 있다.
연구진은 "이 방법은 심층 연구 에이전트에게 효율적인 일반화가 가능하며, 인간이 배우는 것처럼 지속적인 학습을 가능케 한다"라고 밝혔다.
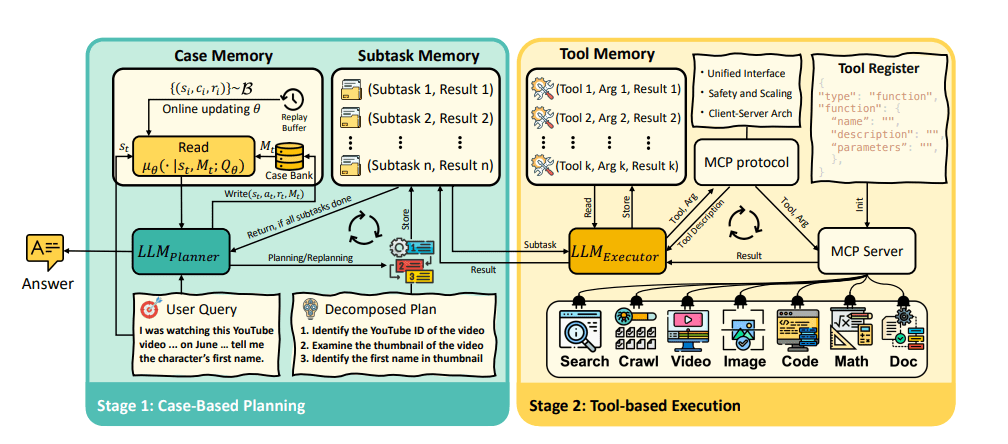
이를 위해 메멘토는 3부분으로 구성됐다. 임무를 받아 계획을 짜는 '계획자(planner)'와 도구를 실행하는 '실행자(executor )', 그리고 과거 경험을 저장하는 '사례 은행(case bank)' 등이다.
작업 요청을 받은 계획자는 우선 사례 은행을 통해 유사 경험이 있는지를 조회한다. 사례가 검색되면 이는 작업 지시와 결합해 새로운 프롬프트를 생성하며, 이 프롬프트는 LLM이 작업을 하위 작업으로 나누고 단계별 계획을 생성하도록 안내한다. 그리고 최종 계획은 LLM이 구동하는 실행자에게 전달된다.
실행자가 하위 작업을 진행하는 동안 '메모리 모듈'이 진행 상황과 결과를 추적한다. 각 작업이 끝나면 계획자는 그 결과를 검토해 작업을 제대로 실행했는지를 검토한다. 그렇지 않은 경우, 업데이트된 계획을 다시 내놓는다. 이런 식으로 작업을 마치면, 이 과정은 일봉의 경험으로 사례 은행에 저장된다.
실행자는 다양한 외부 도구와 연결할 수 있도록 모델 컨텍스트 프로토콜 (MCP)을 사용한다. 여기에는 검색 엔진과 멀티모달 정보 처리 도구가 포함된다.
사례 은행도 두가지 유형을 가지고 있다. 매개변수와는 관계없는 비모수적(non-parametric) 버전은 의미적 유사성을 따져 사례를 검색한다. 더 발전된 매개변수적(parametric) 버전은 강화 학습(RL)을 통해 강화한다. 이를 통해 에이전트가 경험이 쌓이며 더 안정적으로 학습할 수 있게 만드는 것이다.
연구진은 오픈AI의 'GPT-4.1'을 메멘토의 계획자로 활용한 상태에서, 'o3'나 'o4-미니'와 같은 다른 모델을 실행기로 사용했다. 그 결과, 까다로운 벤치마크에서 뛰어난 성능을 보였다.
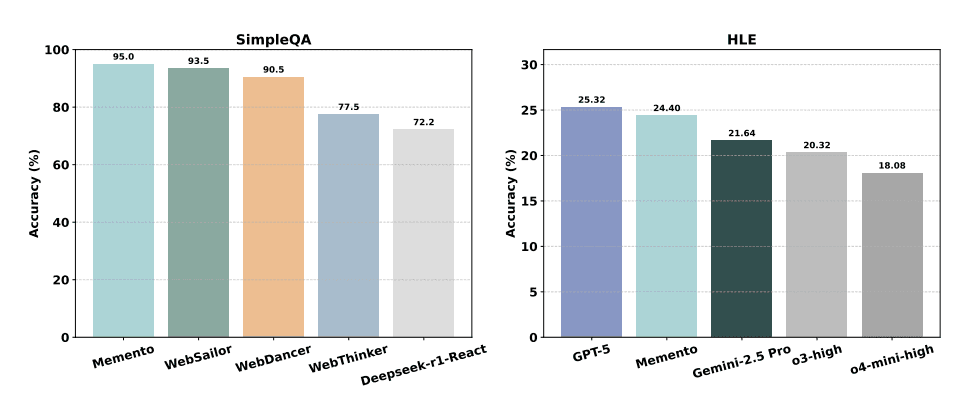
실시간 웹 조사와 추론 능력을 테스트하는 '딥리서처(DeepResearcher)' 벤치마크에서 메멘토는 66.6%의 점수를 달성했다. 이는 검색 증강 생성(RAG)을 사용한 모델의 거의 2배에 달하는 성능이다.
장기 계획과 도구 활용을 평가하는 '가이아(GAIA)' 벤치마크에서는 1위, '인류의 마지막 시험(HLE)'에서는 'GPT-5'에 약간 뒤진 2위를 차지했다. 간단한 지식을 테스트하는 '심플QA(SimpleQA)'에서는 다른 방식보다 가장 높은 정확도를 기록했다.
연구진은 메멘토의 핵심 프레임워크인 M-MDP가 RAG보다 훨씬 더 발전된 것이라고 강조했다. "검색 방식이나 RAG는 학습과 일반화를 제한하는 반면, 강화 학습을 통합하면 메모리의 매개변수화가 가능해져 직접 일반화가 가능해진다"라는 설명이다.
또 앞으로 진정한 자율 AI 에이전트를 구축하는 데 가장 중요한 요소로 '데이터 수집'을 꼽았다. 에이전트가 행동을 개선하려면 환경과 상화작용하며 피드백을 받아야 한다는 것이다. 그다음으로 에이전트가 필요에 따라 '능동적으로' 탐색하게 되면, 자율 시스템 구축에 한층 가까워질 것으로 봤다.
한편, AI 스타트업 깁슨 AI는 에이전트가 과거에 수행한 작업을 기억하지 못하는 현상을 해결하기 위해 표준 SQL 데이터베이스를 사용하는 LLM에 메모리를 제공하는 엔진 '메모리(Memori)'를 개발했다. 이는 깃허브에 오픈 소스로 공개했다.
또 알리바바는 지난달 27일 에이전트가 사람처럼 경험을 축적해 업데이트하고 재활용하며 성능을 높일 수 있도록 돕는 동적 메모리 기법 '멤프(Memp)’를 공개한 바 있다.
이처럼 최근 AI 에이전트에는 사람이 학습하고 기억하는 방식을 모방, 작업 정확도를 높이고 추가 학습 비용을 줄이는 메모리 방식이 잇달아 도입되고 있다.
임대준 기자 ydj@aitimes.com
