대형언어모델(LLM)의 자율적 행동 능력, 즉 인공지능(AI) 에이전트 기능을 높이기 위해 반드시 방대한 데이터가 필요한 것은 아니라는 연구 결과가 나왔다.
상하이교통대학교와 중국의 생성 AI 연구소(GAIR) 공동 연구팀은 2일(현지시간) AI의 자율성을 확보하려면 방대한 데이터보다 선별된 고품질 시연(demonstration)이 더 중요하다는 내용의 연구 ‘LIMI(Less Is More for Intelligent Agency)’를 온라인 아카이브를 통해 공개했다.
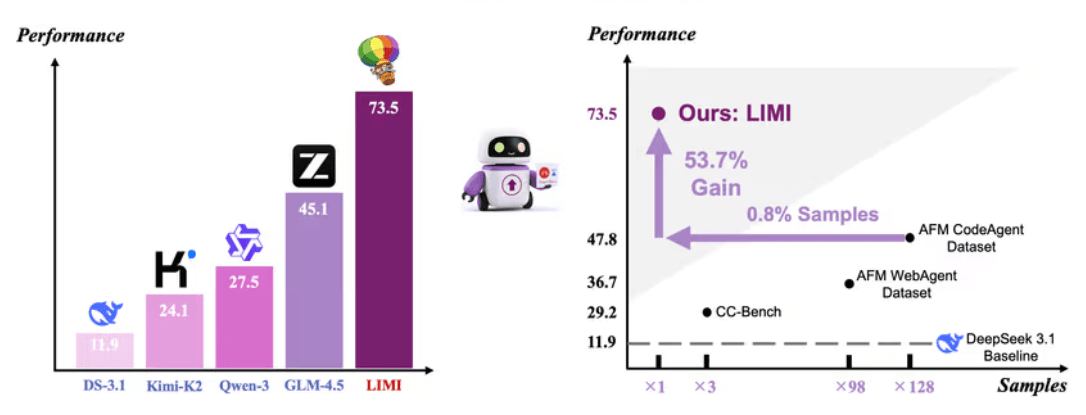
연구진은 실험을 통해, 단 78개의 고품질 예시 데이터만으로도 수천개의 사례로 훈련된 모델을 뛰어넘는 성능을 구현했다고 밝혔다. 특히, 에이전트 능력을 테스트하는 '에이전시벤치(AgencyBench)'에서 LIMI로 미세조정한 모델은 평균 73.5%의 점수를 기록, 기존 최고 성능 모델 'GLM-4.5(45.1%)'을 크게 앞섰다.
연구진은 “AI의 자율성은 많은 데이터를 학습하는 방식이 아니라, 그 본질을 이해하고 이를 정밀하게 구현하는 데서 비롯된다”라며 “이 결과는 ‘생각하는 AI(Thinking AI)’에서 ‘일하는 AI(Working AI)’로의 전환을 이끌 핵심 원리”라고 설명했다.
LIMI는 단순히 학습 데이터를 줄이는 데 초점을 둔 것은 아니다. 연구진은 소량의 데이터만으로도 고도화된 자율적 지능(agency)을 학습할 수 있도록 기존과는 다른 데이터 구성 방식을 적용했다.
이 프레임워크에서 사용되는 학습 시연은 ‘질의(Query)’와 ‘과정(Trajectory)’ 두 부분으로 이뤄진다. 질의는 사용자의 요청을 의미하며, 과정은 AI가 질의를 해결하기 위해 수행하는 전체 문제 해결 과정을 말한다.
과정에는 단계별 사고 전개, 코드 작성과 실행, 외부 도구 호출, 오류 발생 시의 수정 과정 등이 모두 포함된다. AI가 문제를 해결하는 동안의 시도와 실패, 그리고 전략을 조정해 나가는 전 과정이 기록되는 것이다.
이 데이터는 단순히 성공적인 결과만을 수집하는 것이 아니라, AI가 스스로 학습하고 개선해 나가는 흐름을 반영한다. 일부 복잡한 과제의 경우, 이런 상호작용 기록이 15만 토큰을 초과할 정도로 방대하게 축적됐다.
연구진은 먼저 실무 개발자와 연구자로부터 현장에서 직면하는 실제 문제 60개를 수집하고, 'GPT-5'를 이용해 깃허브 풀 리퀘스트로부터 추가 질의를 합성했다. 이후 컴퓨터공학 박사과정 4명이 직접 검증을 거쳐 최종 78개의 고품질 샘플을 확정했다.
이들은 CLI 기반 GPT-5 코딩 에이전트와 협업해 각 과제를 완수하는 과정을 단계별로 기록했으며, 성공뿐 아니라 실패에서 회복하는 전략까지 학습 데이터에 포함했다.
LIMI로 학습된 모델은 1만개 샘플로 훈련된 모델보다 128배 적은 데이터로도 53.7% 향상된 성능을 보였다. 코딩, 도구 사용, 과학 연산 등 다양한 영역의 벤치마크에서도 모든 비교 모델을 앞섰다.
연구진은 “이번 발견은 자율형 AI 개발 방식을 근본적으로 재정의한다”라며 “이제 중요한 것은 ‘얼마나 많은 데이터를 모으는가’가 아니라 ‘얼마나 현명하게 시연을 구성하는가’라는 점”이라고 강조했다.
이번 연구는 데이터가 부족하거나 수집 비용이 많이 드는 기업 환경에서 큰 의미를 가진다. 대규모 데이터 수집 대신, 내부 전문가와 협력해 소규모 고품질 데이터셋을 직접 구축함으로써 맞춤형 AI 에이전트를 효율적으로 개발할 수 있다는 설명이다.
연구진은 LIMI의 데이터 생성 코드와 훈련 절차, 모델 가중치 등을 허깅페이스에 모두 공개했다.
박찬 기자 cpark@aitimes.com
