
인공지능(AI) 검색과 추론의 핵심 기술인 '벡터 임베딩(vector embedding)' 구조에 근본적인 수학적 한계가 존재한다는 연구 결과가 나왔다. 이번 발견은 모델 규모를 확대하거나 학습 데이터 증가로는 해결할 수 없는 구조적 문제로, 기업용 AI 시스템과 검색 엔진 설계 방식에 큰 변화를 촉발할 전망이다.
구글 딥마인드 연구진은 최근 온라인 아카이브를 통해 '임베딩 기반 검색의 이론적 한계(On the Theoretical Limitations of Embedding-Based Retrieval)'라는 논문을 발표했다.
임베딩은 텍스트, 이미지, 오디오 같은 비정형 데이터를 고차원 공간의 벡터로 변환해 의미적 관계를 파악하는 방식이다. 현재 대부분의 검색 증강 생성(RAG) 시스템은 쿼리를 벡터로 변환한 뒤, 가장 가까운 문서를 찾아내는 ‘덴스 검색(Dense Retrieval)’ 방식을 활용한다.
연구진은 '사과를 좋아하는 사람은'과 같은 특정 질문에 대해 여러 문서가 동시에 관련성을 가지는 경우, 임베딩 차원이 모든 조합을 표현하기에 본질적으로 부족하다는 점을 입증했다. 즉, 단일 벡터 방식은 문서 간 복잡한 추상적 관계를 모두 포착하지 못한다는 것이다.
자연어 제약을 배제하고 벡터 자체를 직접 최적화하는 ‘자유 임베딩 최적화(Free Embedding Optimization)’ 실험을 통해 이 한계를 검증했다. 임베딩 차원이 일정 수준을 넘어서면 문서 수가 많아질수록 관련 문서 조합을 전부 표현하는 것이 불가능하게 되는 ‘임계점’이 존재한다는 것을 발견한 것이다.
예를 들어, 512차원 임베딩은 약 50만개 문서, 1024차원은 약 400만개, 4096차원은 최대 2억5000만개 문서까지만 제대로 작동한다는 것이다. 그 이상의 규모에서는 수학적인 표현 한계에 부딪혀 검색 성능이 붕괴한다.
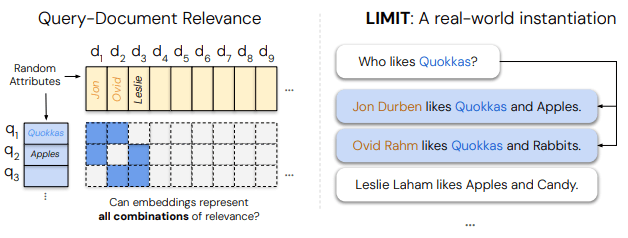
딥마인드 연구진은 실제 검증을 위해 LIMIT라는 데이터셋을 제작했다. 단순한 질문과 명확한 답변 구조에도 불구하고, 문서들이 여러 쿼리에 동시에 연관되도록 설계해 모델의 한계를 극대화했다.
이를 적용한 결과, 문서가 46개밖에 없는 아주 단순한 실험에서도 구글과 스노우플레이크의 최신 임베딩 모델은 정답을 찾는 비율이 20%도 안 됐다. 반면 수십년 된 전통적 키워드 기반 검색 알고리즘인 BM25는 같은 작업에서 뛰어난 성능을 보였다.
또 LIMIT로 모델을 추가 학습해도 성능 개선은 거의 없었다. 이는 단순한 도메인 전환 문제가 아니라 구조적 제약 때문이라는 것을 보여준다.
연구팀은 이번 결과가 현재 RAG 시스템과 엔터프라이즈 검색 엔진에 직접적인 경고라고 강조했다. 단일 벡터 임베딩에만 의존하는 현재 구조는 웹 규모 데이터베이스, 복잡한 논리적 쿼리, 지침 기반 검색 등에서 성능을 발휘할 수 없다는 것이다.
대안으로 ▲쿼리-문서 쌍을 직접 평가하는 크로스 인코더(Cross-Encoder) ▲문서당 여러 벡터를 활용하는 멀티 벡터 모델(ColBERT) ▲차원이 사실상 무제한인 희소 검색 모델(BM25, TF-IDF, 신경망 기반 희소 검색기) 등이 제시됐다.
특히, 가장 실용적인 방법으로 하이브리드 검색 아키텍처를 구축하는 것이라고 밝혔다. "이들을 결합하면 훨씬 더 탄력적이고 안정적인 시스템을 제공할 수 있다"라고 말했다.
하지만, 최적의 답이 하나만 있는 간단한 애플리케이션은 원래 임베딩 모델이 더 적합할 수 있다고 언급했다.
이번 연구는 대규모 AI 검색과 RAG 시스템이 단일 벡터 임베딩에만 의존하면 겉보기에는 그럴듯해도 최고의 답을 얻기 어렵다는 것을 시사한다.
연구진은 “임베딩 기반 검색이 만능 해결책은 아니다”라며 “대규모 AI 검색이나 추론 시스템을 위해서는 단일 벡터 패러다임을 넘어서는 새로운 아키텍처 혁신이 필요하다”라고 강조했다.
박찬 기자 cpark@aitimes.com
