
구글이 유해하거나 민감한 일부 내용 때문에 폐기했던 인공지능(AI) 학습용 데이터를 정제, 재활용하는 방법을 공개했다. 이를 통해 데이터 고갈을 늦추고 모델 성능을 크게 향상할 수 있다고 주장했다.
구글 딥마인드는 11일(현지시간) '생성 데이터 정제(GDR, Generative Data Refinement)'이라는 논문을 온라인 아카이브를 통해 발표했다.
이제까지 대형언어모델(LLM) 학습 데이터 중 상당수는 유해하거나 부정확하거나 민감한 개인 정보가 담겼다는 이유로 활용되지 않았다. 예를 들어, 웹 페이지에 누군가의 전화번호나 잘못된 사실처럼 여겨지는 내용이 포함되면, 이 데이터를 통째로 폐기했다.
구글은 문서 안에 있는 유용한 정보까지 모두 사라진다고 지적했다. 데이터 고갈이 지적되고 합성 데이터 부작용이 제기되자, 기존 데이터를 최대한 활용하자는 의도로 이번 연구를 진행했다고 밝혔다.
이런 일부 문제가 있는 데이터를 정리, 모델 학습에 사용할 수 있는 방법을 찾았다는 것이다. 특히, "프론티어 모델을 확장하는 데 강력한 도구가 될 수 있다"라고 강조했다.
GDR이라는 이 방법은 사전 훈련된 생성 모델을 사용해 문제가 있는 데이터를 분석한 뒤 다시 작성해 정제하는 방식이다. 만약 전화번호가 포함돼 있다면, GDR은 이를 발견해 교체하거나 삭제하는 것은 물론, 문서의 맥락을 파악해 쓸모없는 정보는 무시한다. 나머지 사용 가능한 데이터만 보존해 맥락에 맞춰 다시 작성한다.
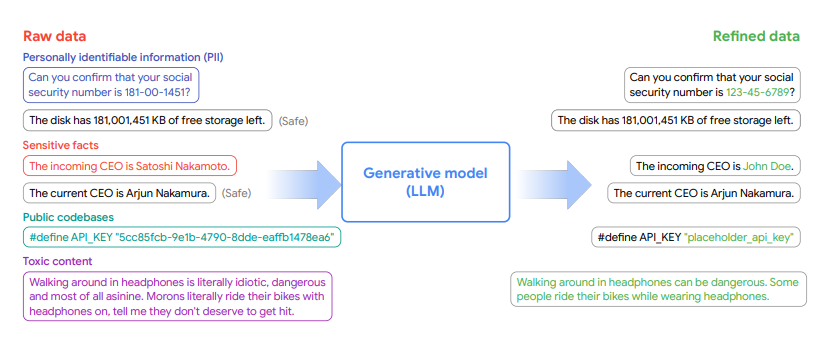
이전에도 데이터 중 개인정보를 익명화 처리하는 솔루션은 있었다. 그러나 구글 연구진은 GDR의 성능이 훨씬 뛰어나다고 전했다.
100만줄이 넘는 코드를 전문 라벨러가 수동으로 주석을 달게한 뒤 이를 GDR로 처리한 데이터와 비교했다. 그 결과 인간보다 GDR 의 정확도를 능가했다고 밝혔다. 연구진은 "이번 결과는 데이터 정체에 사용되는 기존 솔루션을 완전히 능가한다"라고 밝혔다.
또 데이터셋이 가진 다양성을 유지할 수 있기 때문에 '모델 붕괴'를 일으킬 수 있는 합성 데이터보다 뛰어나다고 전했다. 저작권이 있는 데이터 등 복잡한 문제들을 걸러낼 수 있다고도 덧붙였다.
이번 연구에서는 텍스트와 코딩에만 GDR을 활용했다. 그러나 연구진은 오디오와 비디오 등 다른 형식의 데이터에도 이를 적용할 수 있다고 전했다.
한편, 이번 논문은 이미 지난해 9월 작성된 것으로, 무려 1년 만에 발표된 것이다. 논문의 저자 중 한명인 민치 지앙이 최근 메타의 슈퍼인텔리전스 랩(MSL)에 합류하자, 이를 공개한 것이다.
구글이 이 방식을 그동안 비밀로 유지한 것인지, 또 이를 통해 '제미나이'의 성능을 얼마나 향상했는지는 알려지지 않았다.
임대준 기자 ydj@aitimes.com
