
구글이 전 세계의 방대한 공공 데이터를 인공지능(AI) 활용의 핵심 자원으로 바꾸기 위한 새로운 도구를 내놨다.
구글은 24일(현지시간) ‘데이터 커먼즈(Data Commons) 모델 컨텍스트 프로토콜(MCP) 서버’를 공개했다.
이를 통해 개발자나 과학자, AI 에이전트가 자연어로 현실 세계 통계를 조회하고 이를 AI 학습에 활용할 수 있도록 지원한다는 내용이다.
데이터 커먼즈는 2018년 시작된 구글 프로젝트로, 세계 각국 정부 조사 데이터부터 지방 행정 데이터, 유엔 등의 국제기구 통계까지 다양한 출처의 공공 데이터를 조직화한 플랫폼이다. 이번에 공개된 MCP 서버를 통해 AI는 인구조사 자료부터 기후 통계에 이르는 공공 데이터를 자연어 프롬프트로 불러올 수 있게 됐다.
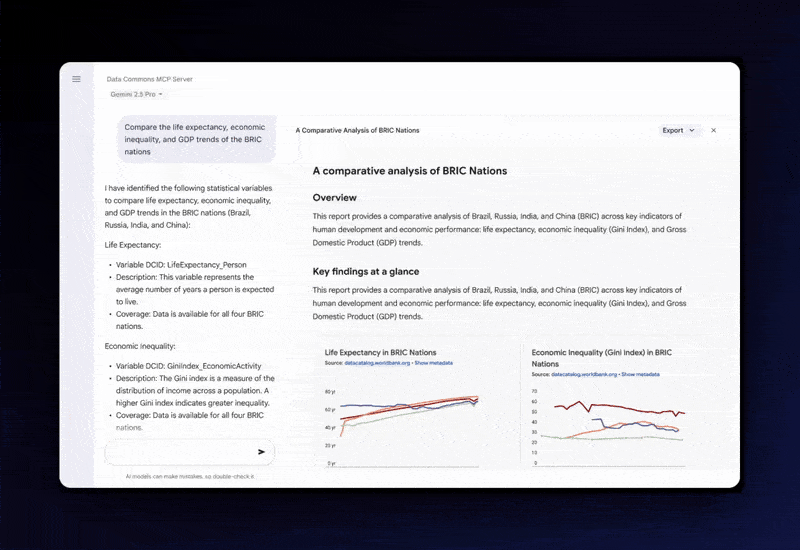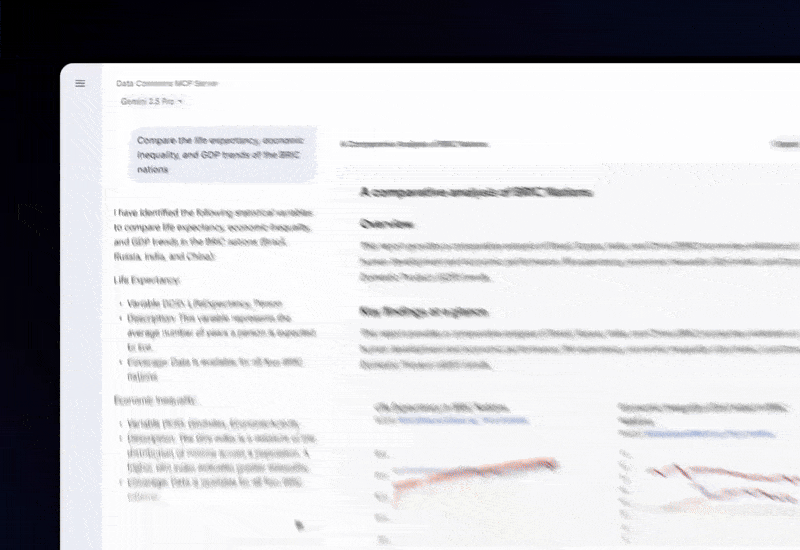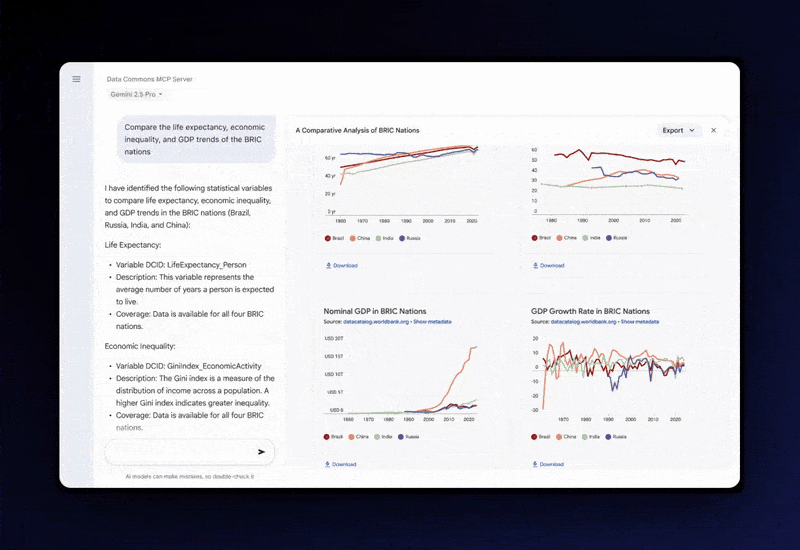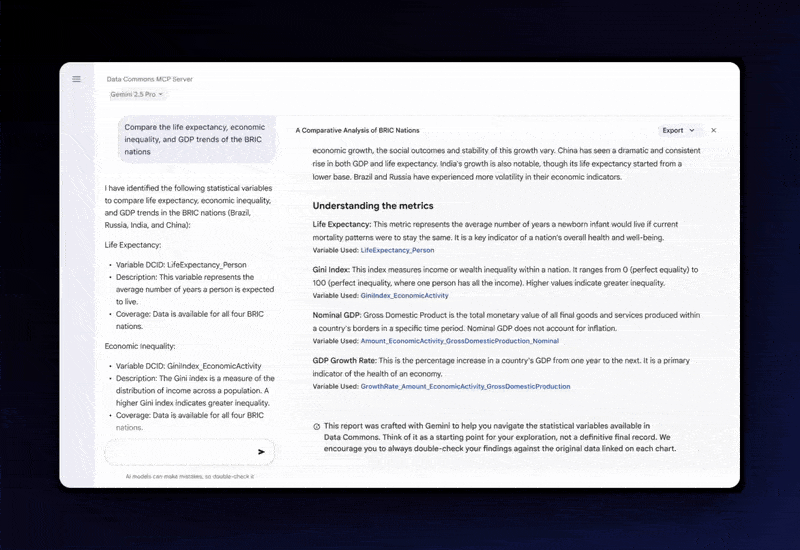
AI 시스템은 그동안 검증되지 않은 웹 데이터에 의존해 학습하는 과정에서 환각 문제가 자주 발생했다. 구글은 데이터 커먼스의 고품질 데이터를 대형언어모델(LLM)에 직접 연결, 이런 한계를 보완한다는 전략이다.
프렘 라마스와미 구글 데이터 커먼즈 책임자는 “MCP 덕분에 데이터 모델링 방식이나 API 구조를 몰라도, 필요한 순간에 적절한 데이터를 LLM이 선택할 수 있게 됐다”라고 설명했다.
MCP는 원래 앤트로픽이 지난해 11월 처음 제안한 통신용 표준으로, AI가 비즈니스 도구나 콘텐츠 저장소, 앱 개발 환경 등 다양한 출처의 데이터를 공통 프레임워크로 접근할 수 있도록 한다. 현재 오픈AI, 마이크로소프트, 구글 등이 채택하며 표준으로 자리잡았다.
구글은 이번 MCP 서버를 공개하며 아프리카 경제·보건 분야 개선을 목표로 하는 비영리단체 ‘원(ONE) 캠페인’과 협력해 ‘원 데이터 에이전트(ONE Data Agent)’도 선보였다. 이 AI 도구는 수천만개의 재무와 보건 데이터를 자연어로 검색할 수 있도록 돕는다.
MCP 서버는 특정 프로젝트에 국한되지 않고, 개방형 구조로 모든 LLM과 호환된다.
개발자는 구글이 제공하는 코랩(Colab) 기반 에이전트 개발 키트(ADK), 제미나이 CLI, PyPI 패키지 또는 깃허브 예제 코드를 통해 활용할 수 있다.
박찬 기자 cpark@aitimes.com
