알리바바가 첨단 '딥 리서치(deep research)' 모델과 경쟁할 수 있는 대형언어모델(LLM) 훈련 프레임워크를 오픈 소스로 공개했다.
알리바바는 26일(현지시간) AI 훈련 프레임워크 ‘에이전틱 CPT(Agentic Continual Pre-training)’를 온라인 아카이브에 발표했다.
사전 훈련과 사후 훈련 사이에 새로운 중간 단계를 추가, 복잡한 다단계 문제 해결 능력을 갖춘 ‘에이전트용 파운데이션 모델’을 구축하는 방식이다. 이를 통해 기업들은 비용 효율적으로 맞춤형 딥리서치 에이전트를 구축할 수 있다는 설명이다.
생성 AI는 대화형 챗봇을 넘어, 도구 활용과 다단계 추론을 수행하는 에이전트로 진화하고 있다. 딥 리서치는 대표적인 연구용 에이전트다.
그러나 일반 목적으로 개발한 파운데이션 모델을 사후 훈련하는 방식으로는 안정적이고 유연한 연구형 에이전트를 만들기 어렵다는 한계가 지적됐다. 특히, 감독 학습(SFT)이나 강화 학습(RL)만으로는 복잡한 탐색이나 추론 과제를 해결하는 데 부족, 모델이 단순 모방에 머물거나 최적화 충돌을 일으키는 문제가 발생했다.
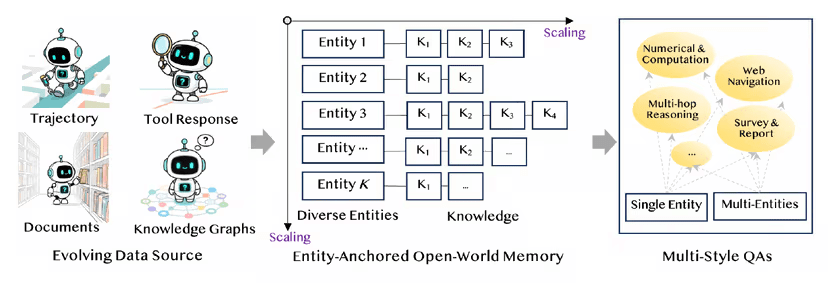
이를 해결하기 위해 알리바바 연구진은 사전 정렬(pre-alignment)된 파운데이션 모델을 만들자는 접근법을 제시했다. 에이전틱 CPT는 방대한 데이터와 다양한 행동 패턴을 반영한 합성 학습 데이터를 통해 모델이 스스로 문제 해결 전략을 탐구하도록 설계됐다.
핵심은 학습용 대규모 합성 데이터 생성이다. 이를 위해 두가지 방식이 활용된다.
먼저 '일차 행동 합성(FAS)'은 사실 검색에서부터 다단계 추론에 이르기까지 폭넓은 시나리오를 포함한 데이터셋을 구축하는 단계다. 이어 '고차 행동 합성(HAS)'은 단일한 정답만을 제시하는 대신 다양한 추론 경로를 만들어내, 모델이 유연한 의사결정 방식을 학습할 수 있도록 돕는다.
특히, 이런 모든 과정은 오프라인 환경에서 이뤄지기 때문에 고비용 API 호출에 의존하지 않고도 대규모 학습을 진행할 수 있다는 장점이 있다.
에이전틱 CPT는 사전 훈련과 사후 훈련 단계 사이에 중간 훈련을 추가한다. 또 새로운 훈련 과정은 두단계로 진행된다.
1단계에서는 3만2000개의 컨텍스트 창을 사용해 약 2000억 토큰의 데이터로 기본적인 에이전트 능력을 학습하고, 2단계에서는 12만8000개의 컨텍스트 창을 사용해 1000억 고품질 데이터를 추가해 장기 계획 능력과 불확실성 관리 능력을 강화한다.

이 방식으로 개발된 '에이전트파운더-30B(AgentFounder-30B)'는 '큐원3-30B'를 기반으로 훈련한 결과물이다.
'브라우즈컴프-en(BrowseComp-en)' 벤치마크에서 기존 최고 성능을 기록한 모델보다 무려 10%포인트 높은 성과를 거뒀으며, '인류의 마지막 시험(HLE)'에서는 처음으로 30점대를 돌파하는 성과를 냈다.
또 '아카데믹 브라우즈(Academic Browse)'에서는 75.3%의 점수를 기록해 학술 검색 보조 도구로서의 가치를 입증했다. 특히, 오픈 소스 딥 리서치 모델 중에서는 처음으로 오픈AI나 딥시크 등에 근접한 성능을 보여줬다.
연구진은 “경쟁사 분석이나 공급망 모니터링처럼 다원적인 검증이 필요한 과제에서 신뢰성 높은 리포트를 빠르게 생성할 수 있다”라고 강조했다. 하지만, 고위험 분야에서는 인간의 검증과 승인 절차가 필요하다고 덧붙였다.
또 기업은 자체 데이터와 도구를 활용해 에이전트파운더-30B를 미세조정할 수 있다. 이를 통해 기업에 특화된 딥 리서치 에이전트를 빠르고 저렴하게 만들 수 있다는 설명이다.
박찬 기자 cpark@aitimes.com
