
메타의 연구 조직 FAIR가 코드 생성 능력을 한 단계 끌어올릴 새로운 대형언어모델(LLM)을 내놨다.
메타 FAIR는 25일(현지시간) 코드 생성 연구를 위한 320억 매개변수의 오픈 웨이트 LLM ‘코드 월드 모델(CWM)’을 공개했다.
기존 정적인 코드 학습만으로는 얻기 어려운 심층적인 코드 이해 능력을 강화하기 위해 개발한 디코더 전용 LLM이다. 단순한 소스 코드 학습을 넘어 코드 실행 과정과 에이전트가 환경과 오랫동안 상호작용한 데이터까지 학습, 코드 생성에 월드 모델(world modeling) 개념을 적용한 것이 특징이다.
CWM은 기존 코드 모델이 소스 텍스트만 학습하던 방식을 넘어, 코드가 실제로 어떻게 작동하는지를 파악하는 대규모의 관찰–행동 궤적을 활용한다. 구체적으로는 파이썬 실행 추적을 통해 각 코드 라인이 실행된 뒤 지역(local) 변수 상태가 어떻게 변하는지를 기록하고, 여기에 더해 도커(docker) 환경에서의 상호작용까지 반영한다.
이를 통해 저장소 내 코드 수정, 셸 명령 실행, 테스트 결과 피드백 등 실제 개발 과정에서 일어나는 다양한 활동이 학습 데이터로 포함된다. 도커는 독립된 환경에 애플리케이션과 동작을 위해 필요한 모든 것을 묶어두기 위해 사용하는 컨테이너 기반의 가상화 플랫폼이다.
연구팀은 수천개의 깃허브 프로젝트를 도커 이미지로 변환한 뒤, 자체 개발한 포리저에이전트(ForagerAgent)를 활용해 방대한 실행 데이터를 수집했다. 이를 통해 약 300만개의 다단계 실행 궤적, 1만개의 이미지, 그리고 3150여개의 저장소가 CWM 학습의 핵심으로 활용됐다.
CWM은 세단계의 학습 절차를 거쳐 완성됐다.
먼저 사전 학습 단계에서는 코드 비중이 높은 약 8조개의 토큰을 사용해 모델을 훈련했으며, 이때 컨텍스트 길이는 8000토큰으로 설정됐다. 중간학습 단계에서는 5조개의 토큰을 활용하며 컨텍스트를 13만1000토큰까지 확장했다. 이 과정에는 파이썬 실행 추적 데이터, 에이전트 상호작용 기록, PR 변경 내역(diff), 컴파일러 관련 정보, 수학적 추론 자료 등 폭넓은 학습 데이터가 포함됐다.
마지막으로 사후 학습 단계에서는 1000억 토큰 규모의 SFT를 통해 지시 수행과 추론 능력을 강화한 뒤, 1720억 토큰 규모의 멀티태스크 강화 학습(RL)을 실시했다. 이 단계에서는 코딩, 수학, 소프트웨어 엔지니어링 등 다양한 환경에서 검증 가능한 RL이 진행됐다.
이런 과정을 통해 CWM은 단순한 코드 생성 능력을 넘어, 문제 파악에서 계획, 수정, 검증까지 포함하는 다단계 추론과 도구 활용 능력을 갖추게 됐다고 전했다.
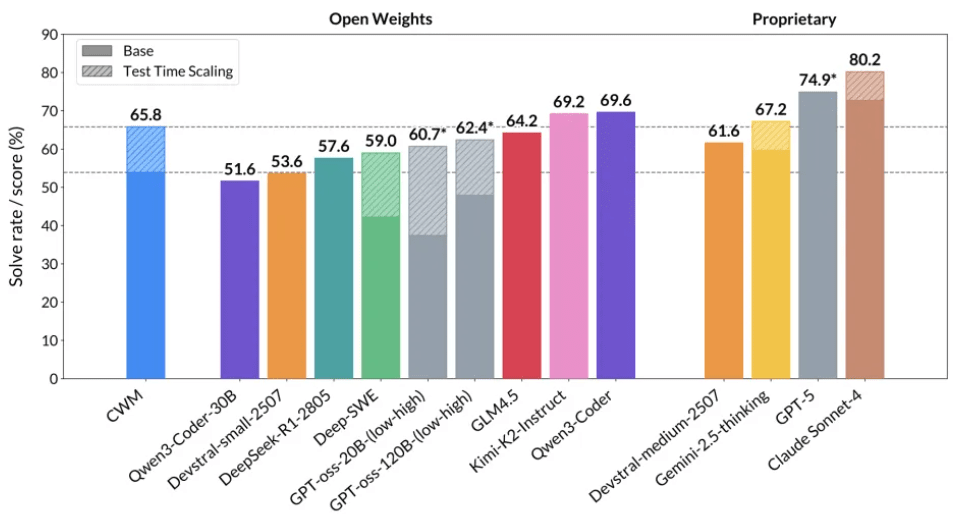
CWM은 동급의 오픈 소스 모델은 물론, 일부 폐쇄형 대형 모델과 비교해도 경쟁력 있는 성능을 보였다.
'SWE-벤치 베리파이드'에서는 확장 적용을 통해 65.8%의 정확도를 기록했고, '라이브벤치코드'에서는 v5에서 68.6%, v6에서 63.5%를 달성했다. 특히 SWE-벤치 베리파이드 점수는 동일 규모의 오픈 소스 모델 중 최고 수준으로, 일부 대형 폐쇄형 모델과의 성능 격차를 크게 좁혔다는 평가를 받았다.
수학 평가에서는 'Math-500'에서 96.6%, 'AIME 2024'에서 76.0%, 'AIME 2025'에서 68.2%를 기록했으며, '크럭스이밸-아웃풋(CruxEval-Output)'에서는 94.3%를 기록했다.
CWM은 성능 향상을 넘어 두가지 추가 기능을 제공한다. 실행 추적 예측(Execution-trace prediction) 기능은 코드와 초기 스택 프레임이 주어졌을 때 함수 실행 과정을 단계별로 예측해 변수 상태와 실행 라인을 기록하는 방식이다. 이를 통해 실제 실행을 거치지 않더라도 ‘신경 디버거(neural debugger)’처럼 근거 기반 추론을 수행할 수 있다.
또 에이전틱 코딩(Agentic coding) 기능은 실제 코드 저장소 환경에서 다중 턴을 수행하며 문제를 분석하고, 최종적으로 git diff 형식의 완결된 패치를 생성한다. 이 과정에서 모델은 숨겨진 테스트와 패치 유사도 기반의 보상 체계를 활용해, 단순히 코드 조각을 만드는 수준을 넘어 실제 결함을 수정하는 능력까지 학습한다.
하지만, 연구진은 이 모델이 "연구 전용으로 실제 운영 환경에는 적합하지 않다"라고 밝혔다. 또, CWM은 범용 어시스턴트 또는 채팅 모델로 사용돼서는 안 된다고 덧붙였다. 일반적인 챗봇 사용을 위한 철저한 최적화를 거치지 않았다는 이유다.
다만 "여러 개발자가 월드 모델과 추론을 통해 얻을 기회를 탐구할 수 있도록 모델을 공개한다"라고 전했다.
CWM 모델과 코드는 현재 허깅페이스와 깃허브를 통해 다운로드할 수 있도록 공개됐다.
박찬 기자 cpark@aitimes.com
