
딥시크가 연산 효율 개선과 비용 절감을 내세운 신형 모델을 선보였다. 차세대 모델 공개에 앞서 거쳐 가는 모델이라고 설명한 만큼, 눈에 띄는 혁신이나 경쟁력은 없다.
딥시크는 29일(현지시간) 장문 문맥 처리에서 추론 비용을 절반 이상 줄일 수 있는 대형언어모델(LLM) ‘딥시크-V3.2-Exp’를 공개했다.
이는 22일 ‘딥시크 V3.1-터미너스(DeepSeek V3.1-Terminus)’ 출시 이후 불과 일주일만이다. 이 회사는 3.2 버전을 "실험적인 모델(experimental model)"이라고 소개하며, "차세대 아키텍처를 향한 중간 단계"라고 밝혔다.
또, 중국 칩 제조업체들과도 모델 개발에 협력하고 있다고 밝혔다. 주력 모델이 아니라고 거듭 강조한 것이다.
가장 큰 특징은 희소 어텐션(sparse attention) 구조다. 기존 LLM들이 사용하는 ‘밀집 어텐션(dense attention)’은 입력된 모든 토큰을 서로 비교해야 해 문맥 길이가 늘어날수록 계산량이 기하급수적으로 증가한다. 이에 따라 GPU 사용량과 에너지 비용이 급격히 늘어나 장문 입력을 처리할수록 API 이용료가 치솟는 문제가 있었다.
딥시크는 이를 해결하기 위해 ‘라이트닝 인덱서(lightning indexer)’와 ‘세밀 토큰 선택 시스템’을 도입했다. 이 모듈은 문맥에서 중요한 부분만 먼저 선별한 뒤, 그 안에서 다시 핵심 토큰만 추려내 제한된 주의(attention) 창에 집중한다. 그 결과, 장문 입력에서도 응답 품질을 유지하며 연산 부담을 크게 낮출 수 있다.
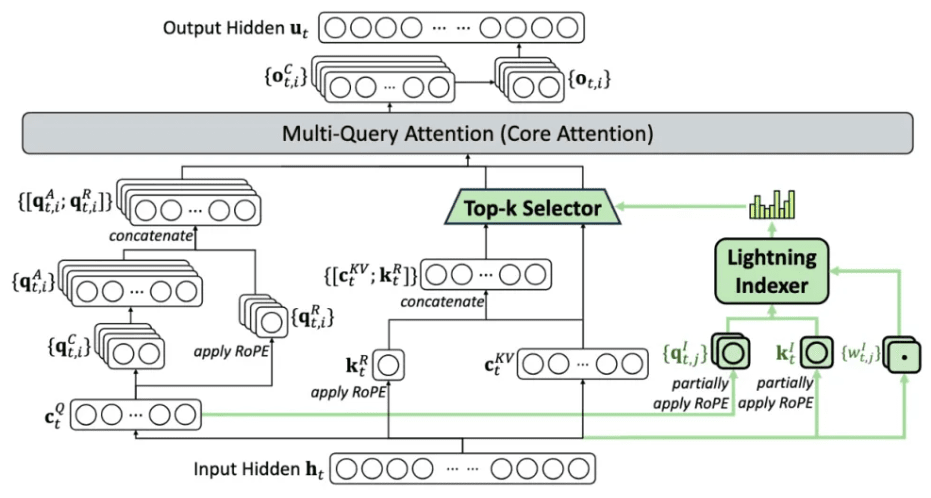
하지만, 희소 어텐션 기술은 이미 지난 해 12월 ‘딥시크-V3’에 적용됐으며, 량원평 딥시크 창립자는 관련 논문으로 국제 학술대회에서 상까지 받았다.
또 오픈AI가 지난 8월 선보인 오픈 웨이트 모델 ‘gpt-oss’에도 이 기술이 활용됐다. 따라서 이번 기술은 새로운 것이 아니다.
V3.2-Exp는 학습 과정에서 수학, 논리 추론, 경쟁 프로그래밍, 에이전트 검색 등 분야별 특화 모델을 따로 훈련한 뒤, 이를 ‘전문가 증류(specialist distillation)’ 기법으로 하나의 모델에 통합했다. 이후 강화 학습(RL) 단계에서는 기존의 다단계 접근을 대신해 GRPO(Group Relative Policy Optimization) 기반의 단일 RL 방식을 도입, 추론·에이전트·휴먼 얼라인먼트 성능을 고르게 향상했다.
하지만, 딥시크-V3가 오픈AI의 ‘o1’ 모델을 증류해 개발됐다는 의혹이 제기된 바 있으며, GRPO 기반 RL도 이미 널리 사용되는 사후 학습 기법이라는 지적이다.
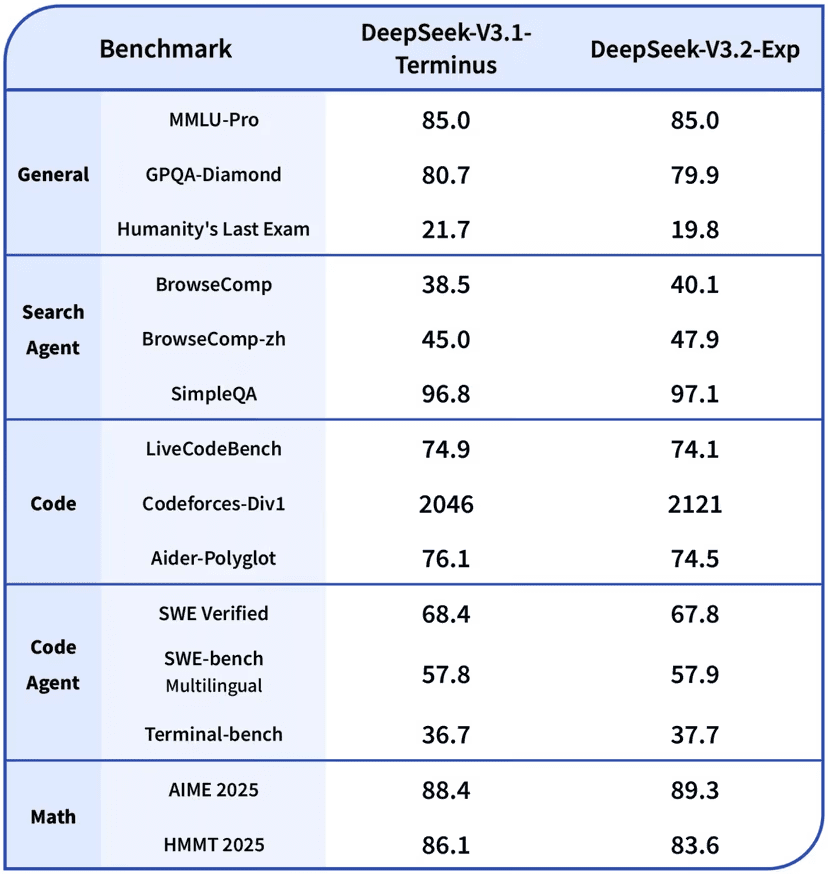
실험 결과, 모델 성능은 이전 버전과 대체로 비슷하거나 일부 지표에서 소폭 개선됐다.
'MMLU-Pro' 점수는 85.0으로 유지됐고, 'AIME 2025'는 89.3으로 상승했다. 코딩 관련 '코드포스' 점수는 2046에서 2121로 개선됐으며, '브라우저콤프'도 38.5에서 40.1로 상승했다. 반면, 'GPQA-다이아몬드'와 같은 일부 고난도 추론 과제에서는 약간의 하락을 기록했다.
API 호출 비용은 최대 50%까지 할인했다. 입력 토큰 100만개 기준으로 캐시 히트 비용은 0.07달러에서 0.028달러로, 캐시 미스 비용은 0.56달러에서 0.28달러로 줄었다. 출력 비용 역시 1.68달러에서 0.42달러로 인하됐다.
그러나 경쟁사에 비해 비싼 가격이다. 구글의 '제미나이 2.5 플래시 라이트'는 입력 100만 토큰당 0.10달러, 출력 100만 토큰당 0.4달러에 제공되며, 오픈AI의 ‘GPT-5 나노’는 입력 100만 토큰당 0.05달러, 출력 100만 토큰당 0.4달러로 가격이 크게 낮아진 상태다.
이번 모델은 허깅페이스와 깃허브를 통해 오픈 소스로 공개됐다. 개발자 편의를 위해 엔비디아 'H200', AMD 'MI350', NPU 환경 등에서 구동 가능한 도커 이미지와 데모 코드도 제공한다.
박찬 기자 cpark@aitimes.com
