
오픈AI가 예고한 대로 오픈 웨이트 추론 모델을 출시했다. 단일 GPU에서 구동 가능한 매개변수 120B 모델과 엣지 디바이스용 20B 등 2종으로, 적은 매개변수로 개방형 중 최고 성능을 달성했다고 밝혔다.
오픈AI는 5일(현지시간) 'gpt-oss-120b'와 'gpt-oss-20b' 등 두가지 온디바이스 모델을 허깅페이스를 통해 출시했다.
아파치 2.0 라이선스가 적용됐다. 즉, 소스코드 저작권과 수정 내용을 고지하면, 상업적인 용도로도 사용 가능하다. 이는 딥시크나 큐원 등과 같은 조건이다.
o3과 기존 고급 모델을 기반으로, 강화 학습(RL) 등의 기법을 조합해 훈련했다. 비슷한 규모의 오픈 모델과 비교했을 때 추론 작업에서 더 뛰어난 성능을 보여줬으며, 도구 사용 기능 측면에서 강력함을 드러냈다고 밝혔다.
gpt-oss-120b은 주요 추론 벤치마크에서 'o4-미니'와 거의 동등한 결과를 달성했다. 여기에 단일 80GB GPU에서 작동할 수 있도록 효율화를 거쳤다. 고급 노트북에서도 로컬로 구동 가능하다.
gpt-oss-20b는 일반 벤치마크에서 'o3‑미니'와 비슷한 결과를 제공하며, 16GB 메모리의 엣지 디바이스나 휴대폰에서 실행할 수 있다.
두 모델은 전문가 혼합(MoE) 방식을 채택, 효율성을 높였다. 쿼리를 받으면 gpt-oss-120b는 51억개(5.1B), gpt-oss-20b는 36억개(3.6B)의 매개변수를 활성화한다. 개별 전문가 모델은 각각 1170억개(117B), 210억개(21B)의 매개변수를 갖췄다.
컨텍스트 창 크기는 최대 12만8000개로, 기존 모델과 같다.
또 모든 매개변수를 동시에 활성화하는 덴스 모델 방식과 로컬에서 결합된 희소 어텐션 패턴을 교대로 사용한다. 추론과 메모리 효율성을 위해 모델은 그룹 크기가 8인 그룹화된 멀티 쿼리 어텐션도 사용한다고 전했다.
학습을 위해 STEM, 코딩, 일반 지식을 중점으로 구성된 고품질 영어 텍스트 데이터셋을 사용했다. 이날 함께 오픈 소스로 배포한 'o200k_하모니(harmony)’라는 o4-미니와 GPT‑4o에 사용되는 토큰나이저의 확대 버전을 사용해 데이터를 토큰화했다.
사후 훈련에는 역시 강화 학습이 핵심으로 꼽혔다. 지도 학습과 고연산 RL을 통해 답변을 생성하기 전에 CoT 추론과 도구 사용으로 출력을 검토하도록 했다. 이는 o4-미니 등에도 적용된 방법으로, 모델 성능 향상에 큰 도움이 됐다는 설명이다.
두 모델의 API도 지원하는데, 속도와 성능의 균형을 맞추기 위해 추론 수준을 낮음, 중간, 높음 등 3가지로 지원한다.
샘 알트먼 오픈AI CEO는 개방형 모델 중 가장 뛰어난 성능을 발휘하는 것이 목표라고 밝힌 바 있다. 그리고 오픈AI는 벤치마크를 통해 실제로 이를 달성했다고 주장했다.
벤치마크 결과, 두 모델은 o3-미니보다 우수하며, o4-미니와 비슷한 수준인 것으로 드러났다.
오픈AI의 최첨단 모델인 'o3'에는 미치지 못한다. 대신, 딥시크나 큐원 등 중국 오픈 소스를 모두 능가했다.
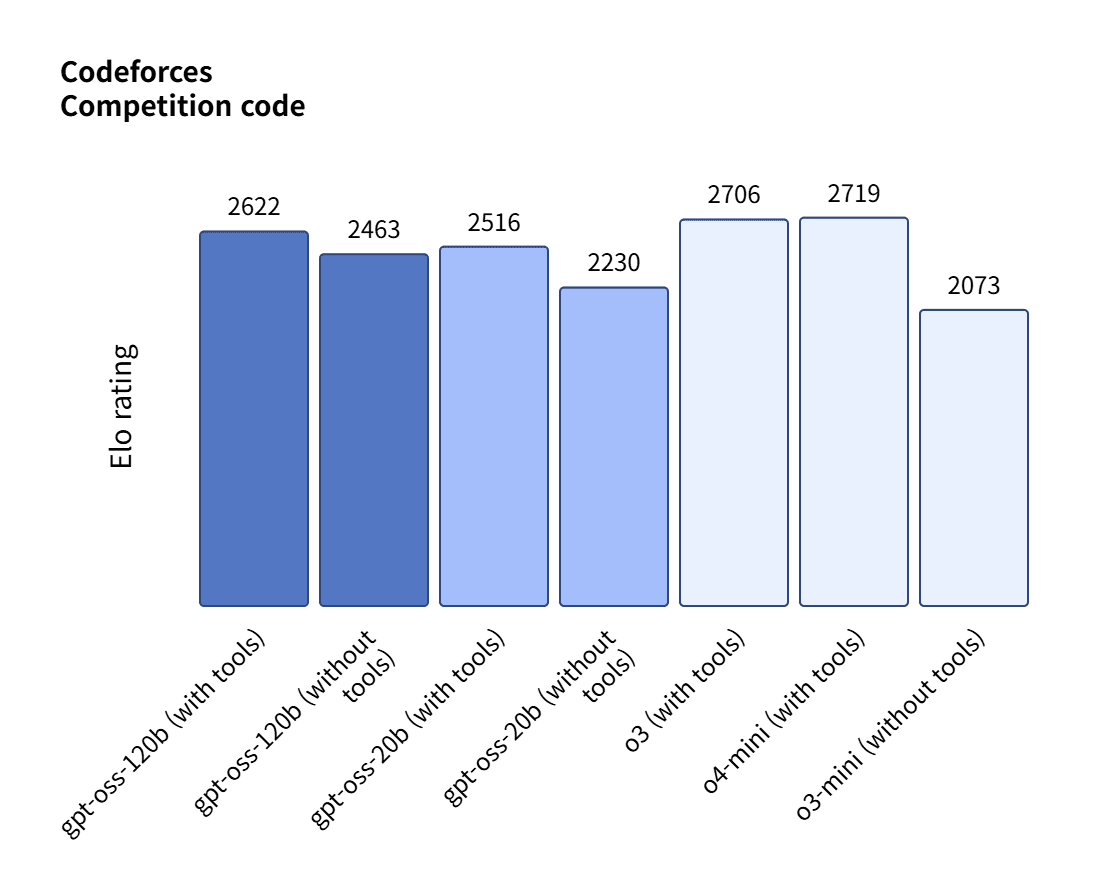
gpt-oss-120b는 코딩(코드포스), 일반 문제 해결(MMLU, HLE), 도구 호출(Tau벤치) 등에서 o4-미니와 비슷하거나 더 우수한 성능을 보여줬다. 또 의료 관련 쿼리(헬스벤치)와 수학(AIME 2024, 2025)에서 o4-미니보다 나은 결과를 달성했다.
gpt-oss-20b는 작은 규모에도 불구하고 같은 평가에서 o3‑미니와 비슷하거나 더 나은 결과를 달성했으며 수학과 의료에서는 더 뛰어난 성능을 보여줬다.
특히 코드포스에서 gpt-oss-120b와 gpt-oss-20b는 각각 2622점과 2516점을 기록, '딥시크-R1'보다 우수한 성능을 보였다.
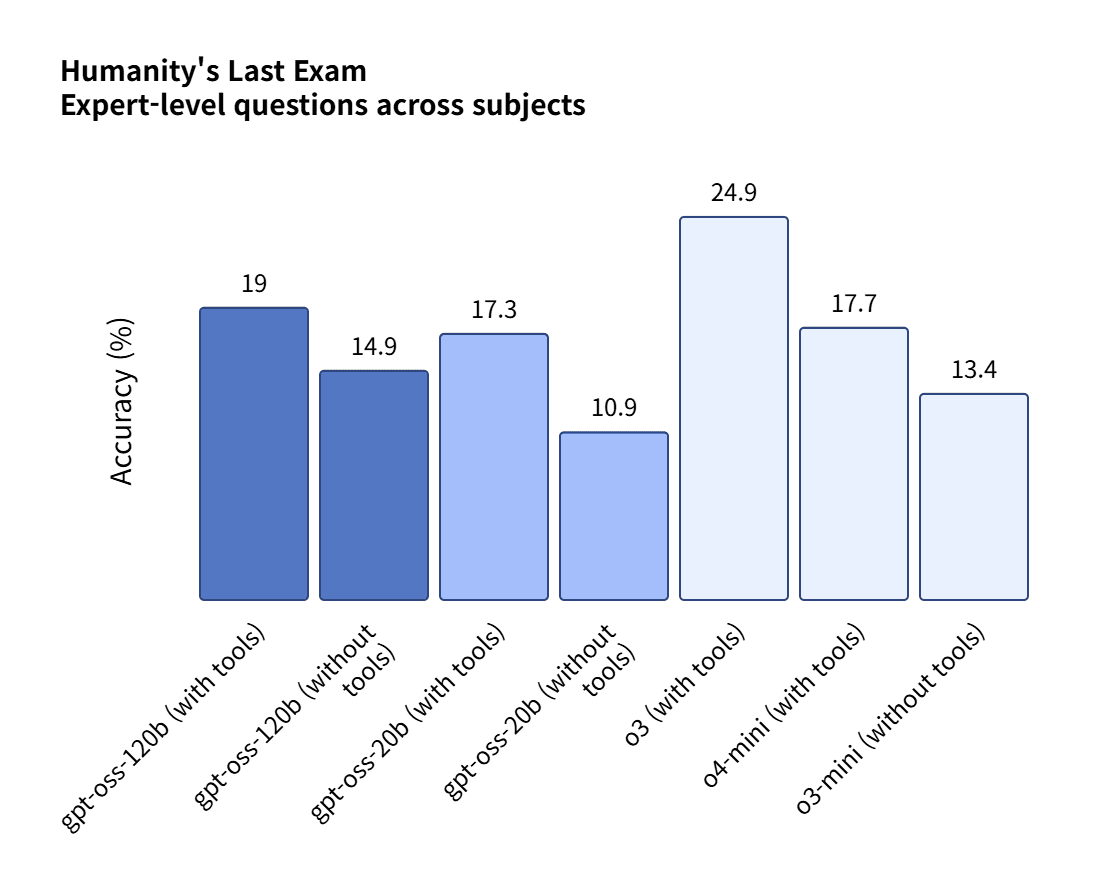
최강 난이도로 알려진 '인류의 마지막 시험(HLE)'에서는 각각 19%와 17.3%의 성적을 기록했다. 역시 o3보다는 낮지만, 딥시크와 큐원보다는 우수한 성적이다.
이번 모델은 개발자들을 위해 CoT 과정을 공개했다.
하지만 "개발자는 애플리케이션에서 사용자에게 직접적으로 CoT를 보여주면 안 된다"라고 명시했다. 또 "CoT에는 오픈AI의 표준 안전 정책을 반영하지 않는 잘못되거나 유해한 콘텐츠가 포함될 수 있으며, 모델이 최종 결과물에 포함하지 않도록 명시적으로 요청받은 정보를 포함할 수도 있다"라고 밝혔다.
오픈 웨이트 모델이 출시되면 공격자가 모델을 미세조정하는 것이 가능해진다. 이 때문에 직접 모델 미세조정 테스트를 거치며 악의적인 공격을 거부하는 버전을 만들었다고 밝혔다.
사전 훈련에서는 화학, 생물학, 방사선학, 핵과 관련된 유해 데이터를 걸러냈으며, 사후 훈련에서는 정렬 및 지침을 사용해 안전하지 않은 프롬프트를 거부하고 프롬프트 추출을 방어하도록 훈련했다고 밝혔다.
오픈AI는 모델 가용성을 높이기 위해 허깅페이스는 물론, 애저나 AWS, 투게더 AI, 데이터브릭스 등 주요 플랫폼과 협력했으며, 이를 통해 배포 범위를 확대할 것이라고 전했다.
하드웨어 측면에서는 엔비디아, AMD, 세레브라스, 그로크 등 다양한 시스템에서 최적화된 성능을 보장한다고 덧붙였다.
모델 테스트를 위한 플레이그라운드도 열었다. 모델 사용 방법이나 미세조정을 위한 가이드도 공개했다.
오픈AI는 "오픈 모델을 추가함으로써 다양한 사용 사례에서 첨단 리서치, 혁신 촉진, 더 안전하고 투명한 AI 개발을 가속하는 것이 목표"라고 밝혔다. 또 "이런 모델이 예산이 부족한 신흥 시장이나 리소스가 제한적인 분야, 소규모 조직의 장벽을 낮춰 전 세계 사람들을 위한 새로운 기회를 줄 수 있다"라고 강조했다.
알트먼 CEO는 X(트위터)를 통해 "o4-미니 수준의 성능을 제공하고 노트북이나 휴대폰에서 실행되는 모델을 만들었다. 팀이 정말 자랑스럽다"라며 "기술의 큰 승리"라고 밝혔다.
임대준 기자 ydj@aitimes.com
- 오픈AI, 오픈 웨이트 모델 출시 다음 주에서 또 연기
- 알트먼, 'o3-미니급' 온디바이스 모델 출시 예고
- 오픈AI, 다음 주부터 '오픈 웨이트' 모델 배포 준비..."o3-미니급 추론 모델"
- 오픈AI, '온디바이스 모델' 개발 하나...오픈 소스 출시 온라인 투표 진행
- 오픈AI, 700조 가치로 지분 매각 논의 중...직원 주식 판매 기회 부여
- AWS, 사상 첫 오픈AI 모델 배포...MS·엔비디아도 가세
- 오픈AI 첫 오픈 모델 ‘gpt-oss’, 연구자에 의해 추론·안전 장치 제거
- 알트먼 "오픈 모델은 중국 견제 위한 것...코딩에 최적화"
- "AI 기반 랜섬웨어 첫 발견...바이브 코딩으로 악성 코드 생성"
- 딥시크, API 비용 절반으로 줄인 실험 모델 'V3.2' 출시
- 오픈AI, 온라인 위험 감지하는 '안전 모델' 공개
