
대형 멀티모달 모델(LMM)을 특정 목적에 맞게 미세조정하는 과정에서 기존에 학습한 일부 능력을 잃는 ‘재앙적 망각(catastrophic forgetting)’ 현상이 실제 기억 상실이 아니라 출력 편향(output bias)에 따른 일시적 현상이라는 연구 결과가 나왔다.
미국 일리노이대학교 어바나-샴페인 캠퍼스 연구팀은 13일(현지시간) 온라인 아카이브에 'LMM이 새로운 기술을 학습하면서도 기존 능력을 유지하는 방법(HOW TO TEACH LARGE MULTIMODAL MODELS NEW SKILLS?)'이라는 제목의 논문을 공개했다.
연구진은 모델의 일부 계층만 선택적으로 조정하는 접근법을 통해 학습 과정에서 발생하는 망각을 줄이는 방법을 제시했다.
이미지와 텍스트를 동시에 처리하는 LMM에 다섯가지 새로운 과제를 순차적으로 학습하면서, 여덟가지 벤치마크를 통해 모델의 일반 성능을 평가했다. 그 결과, 특정 과제에 맞춰 모델을 미세조정할 경우, 이전에 잘 수행하던 다른 과제에서 성능이 크게 하락하는 현상이 나타났다.
연구진은 이 현상의 원인이 모델의 출력 토큰 분포가 작업 분포 변화에 따라 편향되기 때문이라고 분석했다. ‘망각’으로 보이는 것은 실제 지식 손실이 아니라 출력 편향(bias drift)에 가깝다는 설명이다.
즉, 모델이 학습 과정에서 일부 토큰을 더 자주 출력하도록 편향이 이동하면서 성능이 일시적으로 낮아지는 것이지, 모델이 완전히 능력을 잃는 것은 아니라는 것이다.
연구진은 이런 분석 결과를 바탕으로, 모델이 새로운 과제를 학습할 때 기존 능력을 최대한 유지할 수 있는 두가지 학습 방식을 제시했다.
첫번째는 셀프 어텐션 프로젝션(Self-Attention Projection) 층만 선택적으로 업데이트하는 방법으로, 모델 전체를 재조정하지 않고도 목표 성능을 높일 수 있다는 점이 특징이다. 두번째는 MLP(Multi-Layer Perceptron) 구조에서 입력을 받아 출력하는 게이트(Gate)와 입력 차원이 확장되는 업(Up) 부분만 조정하고 축소되는 다운(Down) 프로젝션은 그대로 고정하는 방식으로, 학습 효율을 유지하면서 불필요한 성능 저하를 방지할 수 있다는 설명이다.
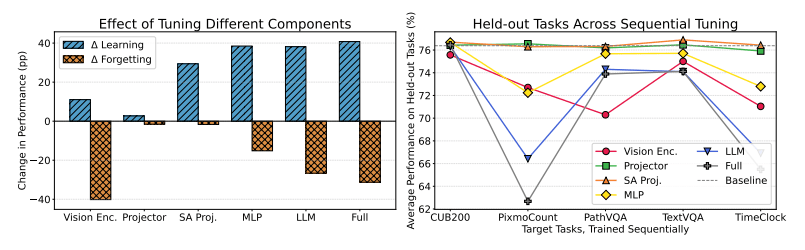
연구진은 이 방법을 이미지 기반 응답을 생성하는 'LLaVA'와 '큐원 2.5-VL'에 적용한 결과, 전체 모델을 학습하지 않고도 목표 과제에서 높은 성능을 달성하면서 보류된 과제의 성능 저하를 거의 막을 수 있었다고 밝혔다.
특히, 셀프 어텐션 층만 조정했을 때는 5개의 연속 과제를 학습하는 동안 거의 측정되지 않을 정도의 망각이 발생하지 않았으며, 한번 떨어졌던 성능도 이후 특화 작업을 학습하며 회복되는 양상을 보였다.
하지만, MLP 층을 조정하면 정확도는 높아졌지만, 숫자형 토큰을 출력할 가능성이 커지고 다른 과제 성능이 동반 하락하는 경향을 나타냈다.
연구진은 “트랜스포머 디코더에서 셀프 어텐션은 입력 데이터를 처리하는 알고리즘 역할을 하고, MLP는 외부 메모리에서 정보를 불러와 출력 분포를 생성한다”라며 “좁은 과제에 대한 미세조정 후 나타나는 망각은 실제 지식 손실이 아니라 출력 분포가 특정 방향으로 치우치는 현상”이라고 설명했다.
이번 연구는 대규모 AI 모델을 효율적으로 업데이트하면서도 기존 성능을 유지할 수 있는 실용적 접근법이라고 전했다.
연구진은 “LMM을 처음부터 훈련하는 데는 수백만달러와 몇주에 달하는 시간이 필요하다”라며 “모델의 일부분만 미세조정하는 방식은 계산 비용 절감과 지속적 성능 보존을 동시에 달성할 수 있는 핵심 전략이 될 것”이라고 강조했다.
한편, 이와 비슷한 기법으로는 마이크로소프트(MS)에서 개발한 매개변수 효율적 미세조정(PEFT) 기술 ‘로라(LoRA)’를 꼽을 수 있다. 로라는 미세조정 중 전체 가중치 대신 일부 가중치만을 조정해 이런 비용을 줄이는 방법이다. 즉, 모델 매개변수 전체를 업데이트하는 대신 모델 매개변수의 변경 사항만을 업데이트한다.
다만 로라는 망각을 완화하기 위한 기술이 아니다. 원래 훈련 데이터와 다른 데이터로 모델을 미세조정해 일부 가중치를 업데이트하면, 결과적으로 왜곡된 부분을 식별하고 수정하기가 어려워진다는 내용이다.
박찬 기자 cpark@aitimes.com
